1 灵活性TensorFlow不是一个严格的神经网络工具包,只要你可以使用数据流图来描述你的计算过程,你可以使用TensorFlow做任何事情。你还可以方便地根据需要来构建数据流图,用简单的Python语言来实现高层次的功能。
2 可移植性TensorFlow可以在任意具备CPU或者GPU的设备上运行,你可以专注于实现你的想法,而不用去考虑硬件环境问题,你甚至可以利用Docker技术来实现相关的云服务。
3 提高开发效率TensorFlow可以提升你所研究的东西产品化的效率,并且可以方便与同行们共享代码。
4 支持语言选项目前TensorFlow支持Python和C++语言。(但是你可以自己编写喜爱语言的SWIG接口)
5 充分利用硬件资源,最大化计算性能
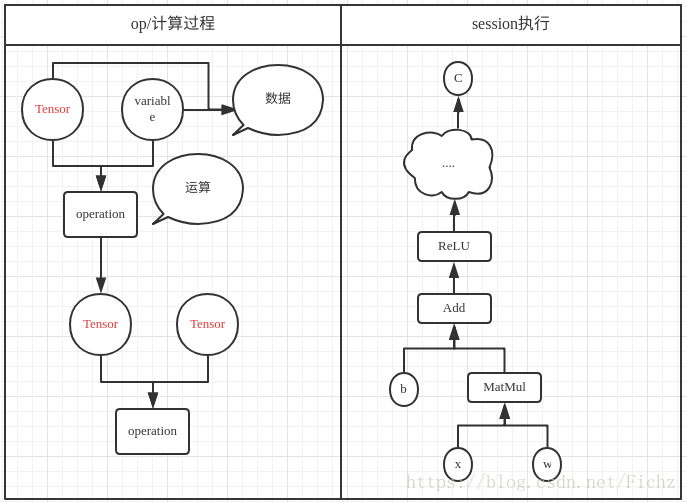
使用图(graphs)来表示计算任务
在被称之为会话(Session)的上下文(context)中执行
使用tensor表示数据(张量,n维数组)
通过变量Variable维护状态
使用feed和fetch可以为任意的操作赋值或者从其中获取数据
综述
Tensorflow 是一个编程系统,使用图(graphs)来表示计算任务。
图中的节点被称之为op (operation 的缩写)。一个 op 获得 0 个或多个 Tensor, 执行计算, 产生 0 个或多个 Tensor. 每个 Tensor 是一个类型化的多维数组.。
例如, 你可以将一小组图像集表示为一个四维浮点数数组, 这四个维度分别是 [batch, height, width, channels]. 批次、高度、宽度、渠道
一个TensorFlow 图描述了计算的过程。为了进行计算,图必须在“会话” 里被启动。 “会话” 将图的 op 分法到诸如CPU 或 GPU之类的 设备 上,同时提供执行OP的方法,这些方法执行后,将产生的tensor返回、
在python中,返回的tensor 是numpy ndarray 对象;在C和C++语言中,返回的是TensorFlow::Tensor 实例
注意,这个图只是描述了计算过程,最后再统计到会话中被执行。主要原因是为了实现高效数值运算,我们通常会把复杂运算交给其他外部语言实现。不过,从外部计算切换的回来的操作仍然是一个很大的开销。如果你用GPU来进行外部计算,这样的开销会更大。用分布式的计算方式,也会花费更多的资源用来传输数据。TensorFlow解决方式是不单独进行复杂的计算,而是让我们可以先用图描述一系列可交互的计算操作,然后全部一起在外运行。
比如:
# 我们进行一个矩阵乘法
# 创建常量op
matrix1 = tf.constant([[3., 3.]])
# 创建另外一个常量 op, 产生一个 2x1 矩阵
matrix2 = tf.constant([[2.], [2.]])
# 创建一个矩阵乘法 matmul op
product = tf.matmul(matrix1, matrix2)
product这个时候返回的是多少呢?
12?
其实这个时候返回的是一个tensor

需要通话会话执行之后才得到结果
# 定义一个会话,启动默认图
sess = tf.Session()
# 调用 sess 的 ’run()‘ 方法来执行矩阵乘法 op, 传入 ’product‘ 作为该方法的参数
# 上面提到,’product‘ 代表了矩阵乘法op 的输出,传入它是向方法声明,我们希望取回矩阵乘法 op 的输出
#
# 整个执行过程是自动化的,会话负责传递 op 所需的全部输入。op通常是并发执行的。
#
# 返回值 ’result‘ 是一个 numpy 'ndarray' 对象
result = sess.run(product)
print(result)
# ==> [[12.]]见下图,b代表偏置、w代表权重