一.数据流图
1.节点(node):节点代表数据所做的的运算或某种操作.
2.边(edge):对应于向OPeration传入和从Operation传出的实际值
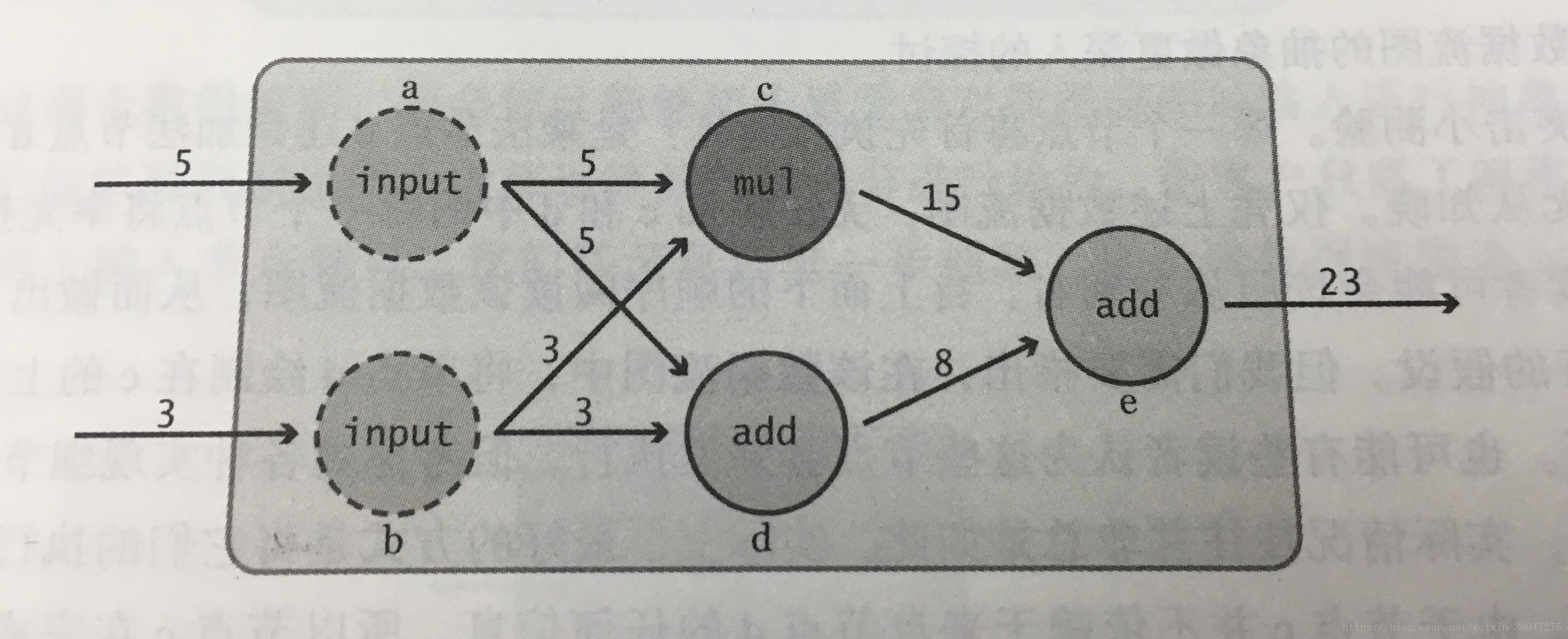
如图,节点a,b表示输入,节点c,d表示乘法和加法操作,e为输出.用公式表达为:
a=input_1;b=input_2;
c=a*b;d=a+b:
e=c+d;
当如图a=5,b=3时,带入上式即可求得e.
3.节点的依赖关系:对于任意节点A,如果其输出对于某个后继节点B的计算是必须的,则称A为B的依赖节点.如果A,B彼此不需要来自对方的任何信息,则称两者是独立的.
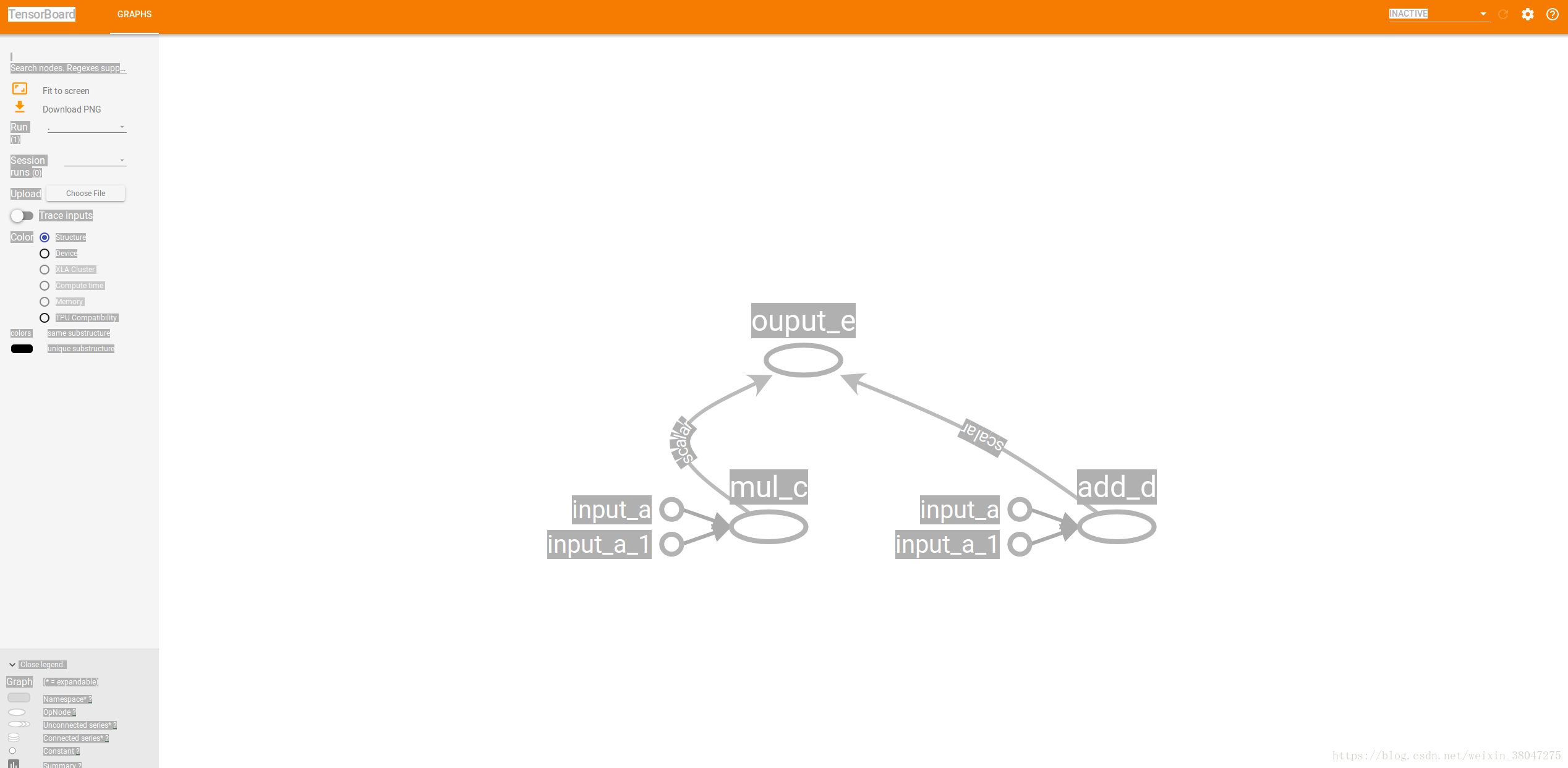
4.在TensorFlow中构建数据流图
import tensorflow as tf
# 对变量赋值
a=tf.constant(5,name='input_a')
b=tf.constant(3,name='input_a')
# 对节点进行标示
c=tf.multiply(a,b,name='mul_c')
d=tf.add(a,b,name='add_d')
e=tf.add(c,d,name='add_e')
# 创建一个Session对象,并运行
sess=tf.Session()
output=sess.run(e)
# 输出
print(output)
# 对数据流图进行可视化
writer=tf.summary.FileWriter('./mygraph',sess.graph)
# 关闭Session对象
sess.close()
writer.close()运行.py文件得到输出23,同时会在同目录出现一个mygraph文件夹,在py文件路径中打开控制台中输入:
$ tensorboard --logdir='mygraph'
打开所生成的地址(默认为6006端口)便能在TensorBoard看见直观的数据流图.
二.张量思维
1.张量: 在一个数组中的元素分布在若干维坐标的规则网络中,我们称之为张量,即n维矩阵的抽象.因此1D张量等价于向量,2D张量等价于矩阵,对于更高维张量,可称为N维张量.
如图: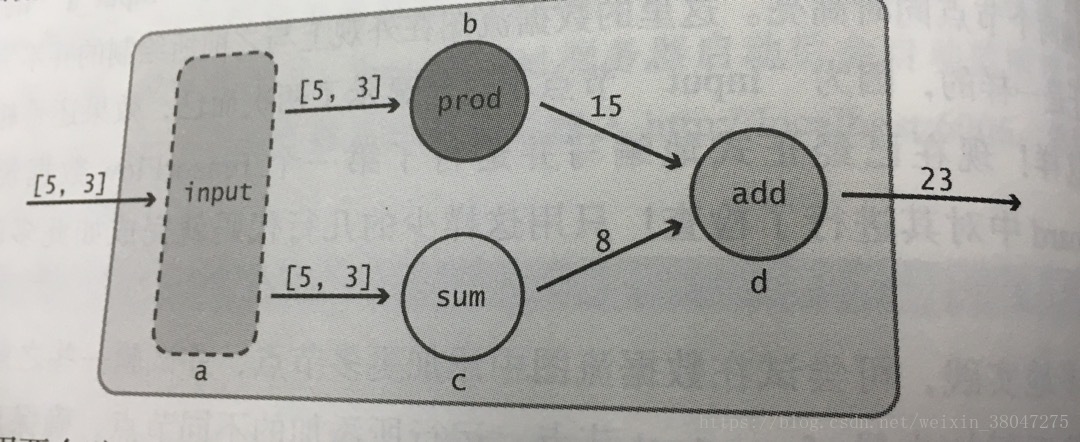
tf代码:
import tensorflow as tf
a=tf.constant([5,3],name='input_a')
b=tf.reduce_prod(a,name='prod_b')
c=tf.reduce_sum(a,name='sum_c')
d=tf.add(b,c,name='add_d')
sess=tf.Session()
output=sess.run(d)
print(output)
writer=tf.summary.FileWriter('./mygraph',sess.graph)
sess.close()
writer.close()2.Tensor对象:在tensorflow中,所有节点之间传递的数据都为Tensor对象.tensorflow操作可接受如下类型作为对象:
python原生类型:
t_0=50 # 标量
t_1=[1,2] # 向量
t_2=[[0,0],[0,0]] # 矩阵
t_3=[[[0,0],[0,0]], # 3阶向量
[[0,0],[0,0]],
[[0,0],[0,0]]]
numpy数组:
import numpy as np
# 元素类型为32位整数的标量
t_0=np.array(50,dtype=np.int32)
# 元素类型为字节字符串的向量,此时不要显示指定dtype属性
t_1=np.array([b"apple",b"peach",b"grape"])
# 元素为布尔型的矩阵
t_2=np.array([[True,False,False],[True,False,False]])
# 元素为64为整数的3阶张量
t_3=np.array([[[0,0],[0,0]],
[[0,0],[0,0]],
[[0,0],[0,0]]],dtype=np.int64)
3.张量的形状:形状为tf中专有术语,刻画了张量的维数以及每一维的长度.例如[2,3]描述了形状为2阶的张量,第一维长度为2,第二维长度为3.
例:
# 刻画了一个3*2矩阵的形状
"""
[[1,2],
[3,4],
[5,6]]
"""
shape=[3,2]
# 将形状指定为None将通知TensorFlow允许一个张量为任意形状,即张量可拥有任意维数
# 且每一维都可具有任意长度.
# 具有任意长度的向量形状
s_1=[None]
# 行数任意,列数为3的矩阵形状
s_2=[None,3]
# 第一维长度为2,第二维,第三维上长度为任意的三阶张量
s_3=[2,None,None]
# 形状任意的张量
s_any=None
如果需要在数据流图中的中间获取某个张量的形状,可使用tf.shape.op.
import tensorflow as tf
#....创建张量
shape=tf.shape(tensor,name='mystery_shape')
4.Operation:op是一些对Tensor对象执行运算的节点.调用时需要传入所需的所有Tensor参数以及为正确创建op的属性.
例
import tensorflow as tf
import numpy as np
#初始化
a=np.array([2,3],dtype=np.int32)
b=np.array([4,5],dtype=np.int32)
#利用tf.add()初始化add op
#输出
c=tf.add(a,b)
tensorflow还对常见的运算符进行重载,以使运算更加简洁.(来源于https://blog.csdn.net/zywvvd/article/details/78593618)
# 算术操作符:+ - * / %
tf.add(x, y, name=None) # 加法(支持 broadcasting)
tf.subtract(x, y, name=None) # 减法
tf.multiply(x, y, name=None) # 乘法
tf.divide(x, y, name=None) # 浮点除法, 返回浮点数(python3 除法)
tf.mod(x, y, name=None) # 取余
# 幂指对数操作符:^ ^2 ^0.5 e^ ln
tf.pow(x, y, name=None) # 幂次方
tf.square(x, name=None) # 平方
tf.sqrt(x, name=None) # 开根号,必须传入浮点数或复数
tf.exp(x, name=None) # 计算 e 的次方
tf.log(x, name=None) # 以 e 为底,必须传入浮点数或复数
# 取符号、负、倒数、绝对值、近似、两数中较大/小的
tf.negative(x, name=None) # 取负(y = -x).
tf.sign(x, name=None) # 返回 x 的符号
tf.reciprocal(x, name=None) # 取倒数
tf.abs(x, name=None) # 求绝对值
tf.round(x, name=None) # 四舍五入
tf.ceil(x, name=None) # 向上取整
tf.floor(x, name=None) # 向下取整
tf.rint(x, name=None) # 取最接近的整数
tf.maximum(x, y, name=None) # 返回两tensor中的最大值 (x > y ? x : y)
tf.minimum(x, y, name=None) # 返回两tensor中的最小值 (x < y ? x : y)
5.Graph对象
import tensorflow as tf
# 创建新的数据流图,对象初始化完成后可利用Graph.as_default()方法访问上下文管理器,为其添加op
g=tf.Graph()
with g.as_default():
# 添加op
a=tf.multiply(2,3)
# 当TensorFlow库被加载时,它会自动创建一个Graph对象,并将作为默认的数据流图
# 放置在默认数据流图中
in_default_graph=tf.add(1,2)
# 放置在g中
with g.as_default():
# 添加op
in_graph_g=tf.multiply(2,3)
# 不在with语句块中,op也放置在默认数据图中
also_graph_g=tf.subtract(5,1)
# 获得默认数据流图句柄
deffault_graph=tf.get_default_graph()
6.Tensorflow Session: Session类负责数据流图的执行.构造方法tf.Session()接受三个可选参数: target指定执行引擎,graph指定Graph对象,config配置Session对象所需要的选项如限制gpu或cpu数量.创建完使用run()方法来计算所期望的Tensor对象的输出.
run()的fetches参数接受任意的数据流图元素,指定了用户希望执行的对象.
see
sess.run([a,b]) #返回[7,21]run()的feed_dict参数:用于覆盖数据流图中的Tensor对象值,需要字典作为对象.
import tensorflow as tf
# 创建op,tensor对象
a=tf.add(2,5)
b=tf.multiply(a,3)
# 利用默认的数据流图启动一个Session对象
with tf.Session() as sess:
# 定义一个字典,将a替换为15
replace={a:15}
#运行Session对象,将replace赋值给feed_dict
out=sess.run(b,feed_dict=replace)
print (out)
)
7.利用占位节点添加输入:利用占位符可以接收数据,为某个Tensor对象预留位置.tf.placeholder()可创建占位符号
import tensorflow as tf
import numpy as np
# 创建一个长度为2,数据类型为int35的占位向量
a=tf.placeholder(tf.int32,shape=[2],name='intput')
# 将该占位符号向量视为其他任意Tenso对象
b=tf.reduce_prod(a,name='prod') #积
c=tf.reduce_prod(a,name='sum_c')#积
# 完成定义
d=tf.add(b,c)
# 定义一个Session对象
with tf.Session() as sess:
# 输入
input_dict={a:np.array([5,3])}
out=sess.run(d,feed_dict=input_dict)
print (out) #输出为308.Variable对象:
(1)创建Variable对象:Tensor对象和op对象都是不可变的,但机器学习任务的本质决定了需要一种机制保存随时间变化的值.Variable对象包含了在对Session.run()对象多次调用中可持久的可变张量值.tf.Variable()可构造Variable对象:
import tensorflow as tf
# 为Variable创建初始值3
my_var=tf.Variable(3,name="my_varibale")
add=tf.add(5,my_var)
mul=tf.multiply(8,my_var)
"""
为使创建具有这些常见类型的初值张量更加容易
TensorFlow提供了一些op
"""
# 2*2零矩阵
zero=tf.zeros([2,2])
# 长度为6的全1向量
ones=tf.ones([6])
# 3*3*3的张量,其元素服从0~10均匀分布
uniform=tf.random_uniform([3,3,3],minval=0,maxval=10)
# 3*3*3的张量,服从0均值,标准差为2的正态分布
normal=tf.random_normal([3,3,3],mean=0.0,stddev=2.0)
# 将这些op最为Variable对象的初值传入,默认均值0,默认标准差1
random_var=tf.Variable(tf.truncated_normal([2,2]))(2).Variable对象的初始话:通过tf.initialize_all_variables()传给Session.run()完成的:
init=tf.initialize_all_variable()
sess=tf.Session()
sess.run(init)如果只需对一个Variable对象初始化可采用tf.initialize_variables()
(3).Variable对象的修改:使用Variable.assign()方法
import tensorflow as tf
var=tf.Variable(1)
# 创建op,使每次运行var*2
var_time_2=var.assign(var*2)
#初始化op
init=tf.initialize_all_variables()
sess=tf.Session()
sess.run(init)
# 乘2
out1=sess.run(var_time_2)
print(out1)
# 再次乘2
out2=sess.run(var_time_2)
print(out2)三.通过名称作用域组织数据流图(每个名称作用域对其自己的op进行封装),通过with tf.name_scope()实现
import tensorflow as tf
with tf.name_scope('a'):
a=tf.add(1,2,name='a_add')
b=tf.multiply(a,3,name='a_mul')
with tf.name_scope('b'):
c=tf.add(4,5,name='b_add')
d=tf.multiply(c,6,name='b_mul')
e=tf.add(b,d,name="output")
writer=tf.summary.FileWriter('./name_scope',graph=tf.get_default_graph())
writer.close()
启动TensorBoard服务器.结果如图.
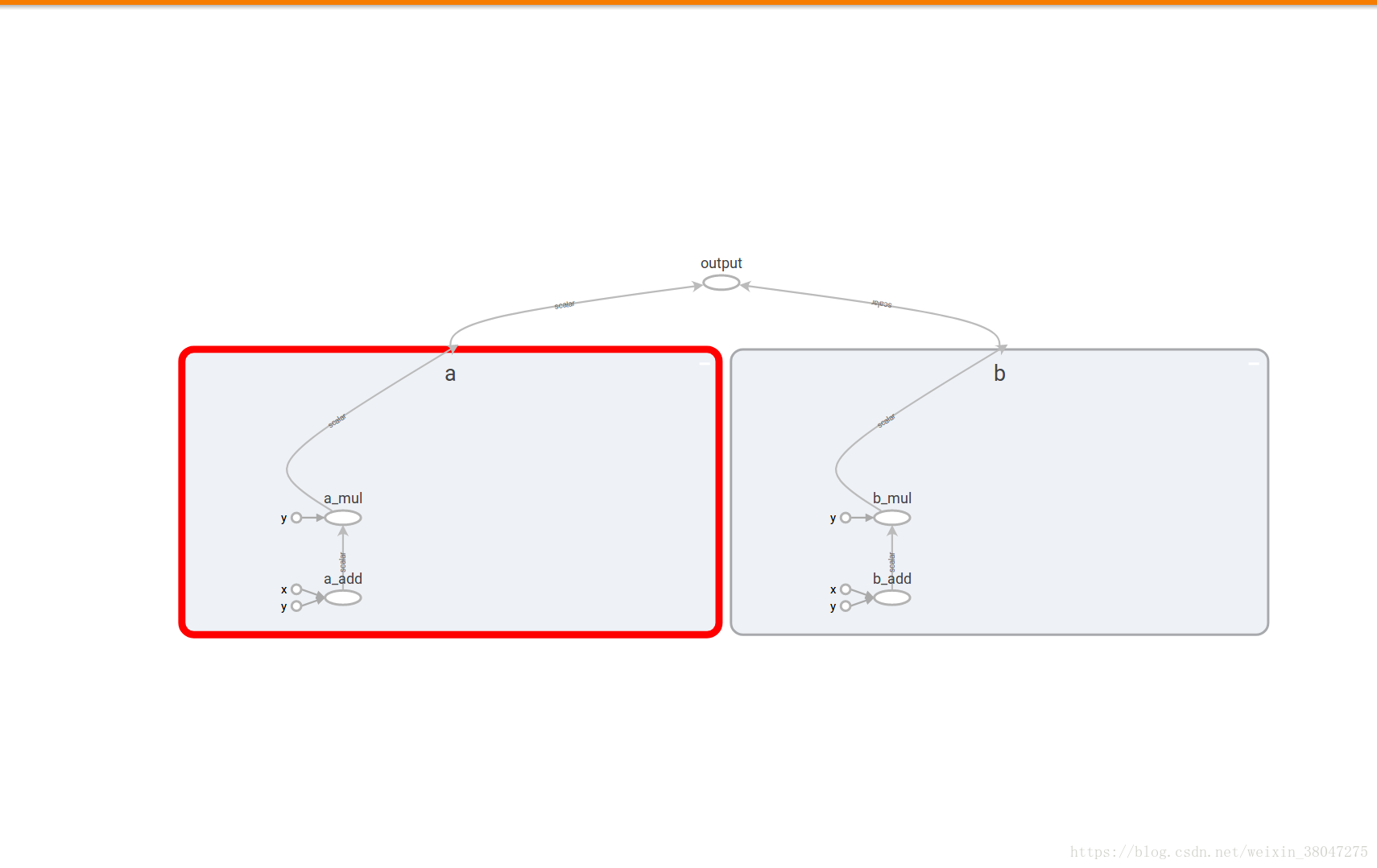
也可将名称作用域嵌入在其他名称的作用域内
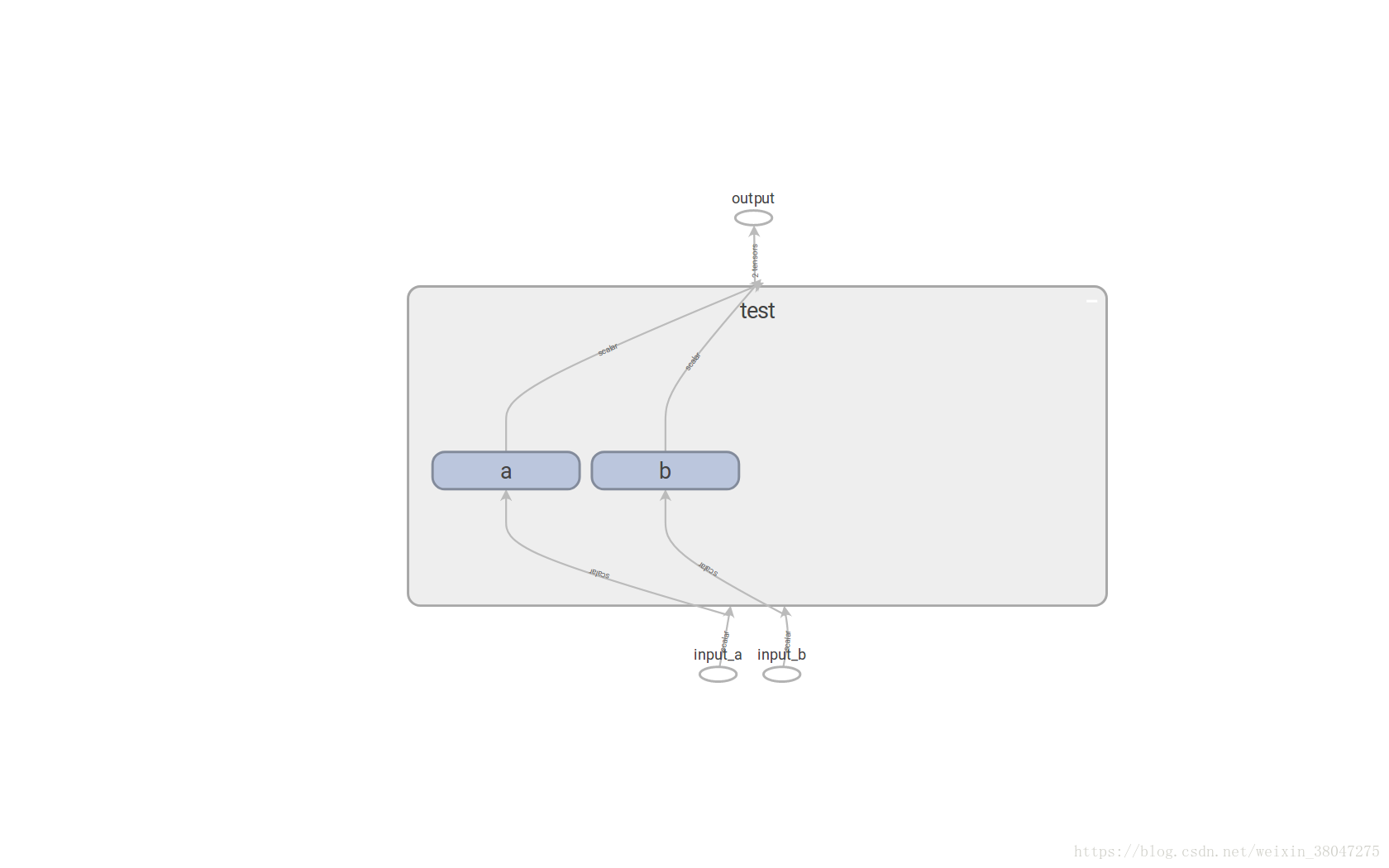
import tensorflow as tf
graph=tf.Graph()
with graph.as_default():
in_1=tf.placeholder(tf.float32,shape=[],name='input_a')
in_2 =tf.placeholder(tf.float32, shape=[],name='input_b')
const=tf.constant(3,dtype=tf.float32,name='static')
with tf.name_scope('test'):
with tf.name_scope('a'):
a=tf.add(in_1,const,name='a_add')
b=tf.multiply(a,3,name='a_mul')
with tf.name_scope('b'):
c=tf.add(in_2,const,name='b_add')
d=tf.multiply(c,6,name='b_mul')
e=tf.add(b,d,name="output")
writer=tf.summary.FileWriter('./name_scope2',graph=graph)
writer.close()
结果如图:
小结
基础内容数据流图,以及tensorflow的op,variable,session类,学完此章对运行数据流图的流程有了了解,也不难看懂官方文档中所给的例子.
import tensorflow as tf
import numpy as np
# 使用 NumPy 生成假数据(phony data), 总共 100 个点.
x_data = np.float32(np.random.rand(2, 100)) # 随机输入
y_data = np.dot([0.100, 0.200], x_data) + 0.300
# 构造一个线性模型
#
b = tf.Variable(tf.zeros([1]))
W = tf.Variable(tf.random_uniform([1, 2], -1.0, 1.0))
y = tf.matmul(W, x_data) + b
# 最小化方差
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# 初始化变量
init = tf.initialize_all_variables()
# 启动图 (graph)
sess = tf.Session()
sess.run(init)
# 拟合平面
for step in range(0, 201):
sess.run(train)
if step % 20 == 0:
print (step, sess.run(W), sess.run(b))
# 得到最佳拟合结果 W: [[0.100 0.200]], b: [0.300]参考:<<面向机器智能TensorFlow实践>>