本篇文章只是让我们形象的理解粒子滤波,所以能不用公式的地方我基本不用公式(当然,整篇文章没用一个公式)所以对于见了公式推导就头晕的小伙伴,这篇文章是很适合你们的。
为了让我们能更好的理解粒子滤波,我先说一下对于卡尔曼滤波的说明,有些零基础的可能就要头疼了,本来粒子滤波都不了解,说什么卡尔曼滤波。在此我先解释一下卡尔曼滤波的中心思想与粒子滤波中心思想是一致的,而卡尔曼滤波有一个十分简单的理解方式,卡尔曼滤波你能大致理解了,粒子滤波的中心思想你也就知道了。
一个关于卡尔曼滤波的笑话如下:
一片绿油油的草地上有一条曲折的小径,通向一棵大树.一个要求被提出:从起点沿着小径走到树下.
(1)“很简单.”A说,于是他丝毫不差地沿着小径走到了树下.
现在,难度被增加了:蒙上眼。
(2)“也不难,我当过特种兵。” B说,于是他歪歪扭扭地走到了树旁。“唉,好久不练,生疏了。” (只凭自己的预测能力)
(3)“看我的,我有 DIY 的 GPS!” C说,于是他像个醉汉似地歪歪扭扭的走到了树旁。“唉,这个 GPS 没做好,漂移太大。”(只依靠外界有很大噪声的测量)
(4)“我来试试。” 旁边一也当过特种兵的拿过 GPS, 蒙上眼,居然沿着小径很顺滑的走到了树下。(自己能预测+测量结果的反馈)“这么厉害!你是什么人?”“卡尔曼 ! ”“卡尔曼?!你就是卡尔曼?”众人大吃一惊。“我是说这个 GPS 卡而慢。
此笑话引用自 highgear 的 《授之以渔:卡尔曼滤波器…大泄蜜…》
由此你可以直观的看出卡尔曼滤波也即粒子滤波的中心思想。即预测+反馈。如果你有一些深度学习方面的知识,对于这个应该不陌生,当然没有了解过深度学习也没事,对于我们理解粒子滤波影响不大。
现在,我们已经直观的了解了什么是粒子滤波。
在具体叙述粒子滤波细节之前,根据周围人得反映情况,需要先了解如下几个简单的知识点:
①先验概率:根据以往经验和分析得到的概率,它往往作为"由因求果"问题中的"因"出现的概率。
②后验概率:基于新的信息,修正原来的先验概率后所获得的更接近实际情况的概率估计。
接下来,我们就简单的领略一下粒子滤波的细节。
1、先上一张图
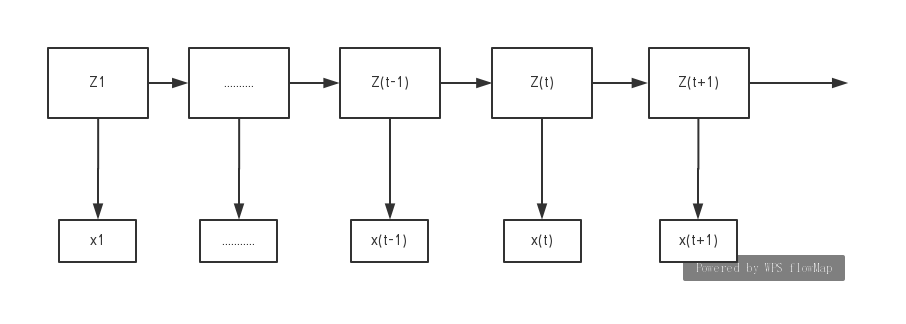
①Zt:当前状态
②xt:观测变量
当然对于Zt是当前状态怎样理解呢,我们可以认为相对于我们能观察到得变量,其实它还有一个隐变量,这个隐变量即可以认为是当前状态。此时这里的Zt是满足一阶马尔科夫假设的,即Zt与Z(t-1)满足一个函数关系式,对于马尔科夫相关解释可以点击此处链接[一阶马尔科夫形象理解]
(https://wenda.so.com/q/1535071225210053)
对于观测变量xt,要满足观测独立性假设,那什么是观测独立性假设呢,观测独立性假设:即假设任意时刻的观测只依赖于该时刻的马尔科夫链的状态,与其他观测即状态无关。即xt与Zt满足一个函数关系式。
2、在对于预测方面,根据前t-1时长的观测变量来以先验概率的形式来预测t时刻的状态Zt,由观测独立性假设可得t时刻的观测变量。
在对于反馈方面,由先验最终得到的t时刻观测变量,可以由后验概率的方式反馈修正t时刻的状态Zt。
3、但是,这里面的后验概率不好求啊,那怎么办呢,这时就引入了蒙特卡洛方法,以采样的方式来代替去直接求后验概率。蒙特卡洛方法你们不需要详细的了解,只要知道在这里我们是要用采样的方式去进行相关操作即可。采样得到的结果,可以认为是产生了许多的粒子。
4、这时,又出现了一个问题——在使用粒子滤波进行实际项目开发的时候,后验概率可能是几百维,甚至几万维,这时候怎么去采样,这时候就出现了重要性采样,这里需要详细介绍一下重要性采样:例如p(z)就是我们需要的采样概率分布,但是此时我们去分析以一种什么样的采样方式得到p(z)是很麻烦的。但是,如果我们可以找到一个分布,这个分布很好采样,那我们对于这个分布进行采样,即p(z)=[p(z)/q(z)]q(z),这里的q(z)我们称为提议分布,q(z)是很好采样得到的,那么我们就知道了采样的方式了即也是对于得到p(z)的采样方式,那么p(z)也可以求出来了。我们称p(z)/q(z)为权重W。
5运用上述,是可以求出权重的,但是每一时刻会有许多的权重,都要计算,计算量比较多,那有没有可能找一种方法减少计算量呢。确实有,如果能找到前后时刻上的权重W存在相关性,即例如t时刻的W能用t-1时刻的W表示,那么,我只需求出第一次的W即可。这时候就引出了顺序重要性采样,这个顺序可以理解为权重W在时间上的顺序。为了分析的方便,在计算每一时刻的权重时要进行归一化操作,即当前时刻的权重和为1。在经过多次更新权值后,目标粒子的权重会增大非目标的粒子权重会降低,这相当于滤波的效果,粒子滤波由此得名。
6、在进行多次的预测+反馈更新权重后,发现会出现粒子的权重出现了退化现象,即在经过多轮更新后,可能把只有极少部分粒子的权重提高了,大部分的粒子的权重降低了。这样再去进行相关操作显然是不合适的。
7、这时我们有两种方法可以减轻权重退化的现象。
①选择好的提议分布
②重采样
目前基本都是进行重采样,因此在这里只讲一下最简单的重采样原理:
出现权重退化的原因就是因为权重变化的问题,那我们可以把权重都均分啊,也就是说一个大权重的粒子平均分为几个相等权重的粒子,则此时所有的粒子权重都是相同的。这些重采样后的粒子就代表了Zt,下一轮预测时,将重采样后的粒子作为Zt,直接获得预测粒子。
至此,关于粒子滤波的白话说明就结束,希望我的文章能够给您带来一点收获。
