粒子滤波 PF——在机动目标跟踪中的应用(粒子滤波VS扩展卡尔曼滤波)
对于该博客跟踪代码以及问题探讨可以联系:WX:ZB823618313
对于其他跟踪定位问题的代码及探讨也可以联系
粒子滤波 PF——在目标跟踪中的应用
原创不易,路过的各位大佬请点个赞
一、问题描述(离散时间非线性系统描述)
考虑一般非线性系统模型,
x k = f ( x k − 1 , w k − 1 ) z k = h ( x k , v k ) (1) x_k=f(x_{k-1},w_{k-1}) \\ z_k=h(x_k,v_k ) \tag{1} xk=f(xk−1,wk−1)zk=h(xk,vk)(1)
其中 x k x_k xk为 k k k时刻的目标状态向量。 z k z_k zk为 k k k时刻量测向量(传感器数据)。这里不考虑控制器 u k u_k uk。 w k {w_k} wk和 v k {v_k} vk分别是过程噪声序列和量测噪声序列,并假设 w k w_k wk和 v k v_k vk为零均值高斯白噪声,其方差分别为 Q k Q_k Qk和 R k R_k Rk的高斯白噪声,即 w k ∼ ( 0 , Q k ) w_k\sim(0,Q_k) wk∼(0,Qk), v k ∼ ( 0 , R k ) v_k\sim(0,R_k) vk∼(0,Rk),且满足如下关系(线性高斯假设)为:
E [ w i v j ′ ] = 0 E [ w i w j ′ ] = 0 i ≠ j E [ v i v j ′ ] = 0 i ≠ j \begin{aligned} E[w_iv_j'] &=0\\ E[w_iw_j'] &=0\quad i\neq j \\ E[v_iv_j'] &=0\quad i\neq j \end{aligned} E[wivj′]E[wiwj′]E[vivj′]=0=0i=j=0i=j
二、粒子滤波 PF
核心思想:是使用一组具有相应权值的随机样本(粒子)来表示状态的后验分布。该方法的基本思路是选取一个重要性概率密度并从中进行随机抽样,得到一些带有相应权值的随机样本后,在状态观测的基础上调节权值的大小。和粒子的位置,再使用这些样本来逼近状态后验分布,最后将这组样本的加权求和作为状态的估计值。粒子滤波不受系统模型的线性和高斯假设约束,采用样本形式而不是函数形式对状态概率密度进行描述,使其不需要对状态变量的概率分布进行过多的约束,因而在非线性非高斯动态系统中广泛应用。尽管如此,粒子滤波目前仍存在计算量过大、粒子退化等关键问题亟待突破。
通常情况下选择先验分布作为重要性密度函数、即
q ( x k ∣ x k − 1 ( i ) , z k ) = p ( x k ∣ x k − 1 ( i ) ) q(x_k |x_{k-1}^{(i)}, z_{k})=p(x_k |x_{k-1}^{(i)}) q(xk∣xk−1(i),zk)=p(xk∣xk−1(i))
对该函数取重要性权值为
w k ( i ) = w k − 1 ( i ) p ( z k ∣ x k ( i ) ) w_k^{(i)}=w_{k-1}^{(i)}p(z_k |x_{k}^{(i)}) wk(i)=wk−1(i)p(zk∣xk(i))
同样 w k ( i ) w_k^{(i)} wk(i)需要归一化得到 w ~ k ( i ) \tilde{w}_k^{(i)} w~k(i)。
标准的粒子滤波算法步骤为:
粒子滤波PF:
Step 1: 根据 p ( x 0 ) p(x_{0}) p(x0)采样得到 N N N个粒子 x 0 ( i ) ∼ p ( x 0 ) x_0^{(i)} \sim p(x_{0}) x0(i)∼p(x0)
For i = 2 : N i=2:N i=2:N
Step 2: 根据状态转移函数产生新的粒子为:$ x k ( i ) ∼ p ( x k ∣ x k − 1 ( i ) ) x_k^{(i)} \sim p(x_{k} |x_{k-1}^{(i)}) xk(i)∼p(xk∣xk−1(i))
Step 3: 计算重要性权值: w k ( i ) = w k − 1 ( i ) p ( z k ∣ x k ( i ) ) w_k^{(i)}=w_{k-1}^{(i)}p(z_k |x_{k}^{(i)}) wk(i)=wk−1(i)p(zk∣xk(i))
Step 4: 归一化重要性权值: w ~ k ( i ) = w k ( i ) ∑ j = 1 N w k ( j ) \tilde{w}_k^{(i)}=\frac{w_k^{(i)}}{\sum_{j=1}^Nw_k^{(j)}} w~k(i)=∑j=1Nwk(j)wk(i)
Step 5: 使用重采样方法对粒子进行重采样(以系统重采样为例)
Step 6: 得到 k k k时刻的后验状态估计:
E [ x ^ k ] = ∑ i = 1 N x k ( i ) w ~ k ( i ) E[\hat{x}_{k}]= \sum_{i=1}^Nx_{k}^{(i)}\tilde{w}_k^{(i)} E[x^k]=i=1∑Nxk(i)w~k(i)
End For
粒子滤波PF算法结构图
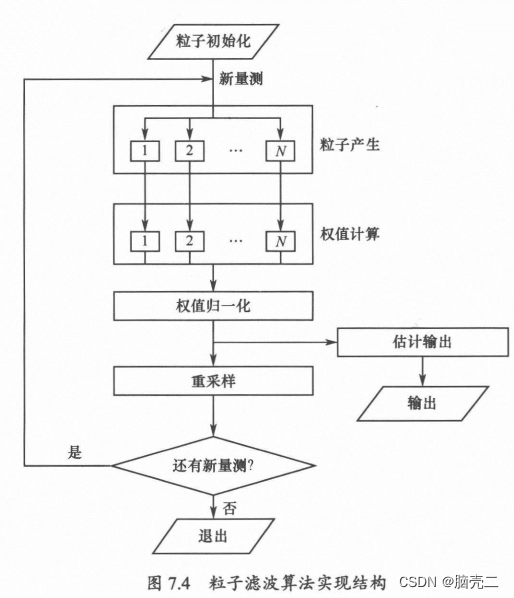

算法:系统重采样 (systematic resampling)
For i = 1 : N i=1:N i=1:N
Step 1: 初始化累积概率密度函数CDF: c 1 = 0 c_1=0 c1=0
For i = 2 : N i=2:N i=2:N
Step 2: 构造CDF: c i = c i − 1 + w k ( i ) c_i=c_{i-1}+w_k^{(i)} ci=ci−1+wk(i)
Step 3: 从CDF的底部开始: i = 1 i=1 i=1
Step 4: 采样起始点: u 1 = U [ 0 , 1 / N ] u_1=\mathcal{U}[0,1/N] u1=U[0,1/N]
End For
For j = 1 : N j=1:N j=1:N
Step 5: 沿CDF移动: u j = u 1 + ( j − 1 ) / N u_j=u_{1}+(j-1)/N uj=u1+(j−1)/N
Step 6: While u j > c i u_j>c_i uj>ci
i = i + 1 i=i+1 i=i+1
End While
Step 7: 赋值粒子: x k ( j ) = x k ( i ) x_k^{(j)}=x_k^{(i)} xk(j)=xk(i)
Step 8: 赋值权值: w k ( j ) = 1 / N w_k^{(j)}=1/N wk(j)=1/N
Step 9: 赋值父代: i ( j ) = i i^{(j)}=i i(j)=i
End For
三、仿真场景:三维雷达目标跟踪
3.1 仿真场景(三维螺旋上升机动目标)
目标模型
考虑一各三维的匀速转弯运动目标:
x k + 1 = F k x k + G k w k x_{k+1}=F_kx_k+G _kw_k xk+1=Fkxk+Gkwk
其中状态向量 x k = [ x k , x ˙ k , y k , y ˙ k , z k , z ˙ k ] ′ x_k=[x_k,\dot{x}_k,y_k,\dot{y}_k,z_k,\dot{z}_k]' xk=[xk,x˙k,yk,y˙k,zk,z˙k]′;噪声为 w k = [ w x , w y , w z ] ′ w_k=[w_x,w_y,w_z]' wk=[wx,wy,wz]′;
目标运动轨迹为三维匀速转弯运动模型
运动轨迹:螺旋上升
如果为非线性目标,则将状态转移矩阵 F k F_k Fk代替为雅可比矩阵即可。为了不是一般性这里采用线性模型进行仿真。主要处理目标跟踪,雷达量测存在的非线性滤波问题。
雷达量测模型
在三维情况下,雷达量测为距离和角度
r k m = r k + r ~ k b k m = b k + b ~ k e k m = e k + e ~ k {r}_k^m=r_k+\tilde{r}_k\\ b^m_k=b_k+\tilde{b}_k\\ e^m_k=e_k+\tilde{e}_k rkm=rk+r~kbkm=bk+b~kekm=ek+e~k
其中
r k = ( x k − x 0 ) + ( y k − y 0 ) 2 ) b k = tan − 1 y k − y 0 x k − x 0 e k = tan − 1 z k − z 0 ( x k − x 0 ) 2 + ( y k − y 0 ) 2 r_k=\sqrt{(x_k-x_0)^+(y_k-y_0)^2)}\\ b_k=\tan^{-1}{\frac{y_k-y_0}{x_k-x_0}}\\ e_k=\tan^{-1}{\frac{z_k-z_0}{\sqrt{(x_k-x_0)^2+(y_k-y_0)^2}}}\\ rk=(xk−x0)+(yk−y0)2)bk=tan−1xk−x0yk−y0ek=tan−1(xk−x0)2+(yk−y0)2zk−z0
[ x 0 , y 0 , z 0 ] [x_0,y_0,z_0] [x0,y0,z0]为雷达坐标,一般情况为0。雷达量测为 z k = [ r k , b k , e k ] ′ z_k=[r_k,b_k,e_k]' zk=[rk,bk,ek]′。雷达量测方差为
R k = cov ( v k ) = [ σ r 2 0 0 0 σ b 2 0 0 0 σ e 2 ] R_k=\text{cov}(v_k)=\begin{bmatrix}\sigma_r^2 & 0 &0\\0 & \sigma_b^2 &0\\0&0& \sigma_e^2 \end{bmatrix} Rk=cov(vk)=⎣⎡σr2000σb2000σe2⎦⎤且 σ r = 20 m \sigma_r=20m σr=20m, σ b = 20 m r a d \sigma_b=20mrad σb=20mrad, σ e = 15 m r a d \sigma_e=15mrad σe=15mrad。
性能指标
RMSE(Root mean-squared error):蒙塔卡罗次数 M = 500 M=500 M=500, x ^ k ∣ k i \hat{x}_{k|k}^i x^k∣ki为第 i i i次仿真得到的估计。
RMSE ( x ^ ) = 1 M ∑ i = 1 M ( x k − x ^ k ∣ k i ) ( x k − x ^ k ∣ k i ) ′ \text{RMSE}(\hat{x})=\sqrt{\frac{1}{M}\sum_{i=1}^{M}(\mathbf{x}_k-\hat{\mathbf{x}}_{k|k}^i)(\mathbf{x}_k-\hat{\mathbf{x}}_{k|k}^i)'} RMSE(x^)=M1i=1∑M(xk−x^k∣ki)(xk−x^k∣ki)′
Position RMSE ( x ^ ) = 1 M ∑ i = 1 M ( x k − x ^ k ∣ k i ) 2 + ( y k − y ^ k ∣ k i ) 2 + ( z k − z ^ k ∣ k i ) 2 \text{Position RMSE}(\hat{x})=\sqrt{\frac{1}{M}\sum_{i=1}^{M}(x_k-\hat{x}_{k|k}^i)^2+(y_k-\hat{y}_{k|k}^i)^2+(z_k-\hat{z}_{k|k}^i)^2} Position RMSE(x^)=M1i=1∑M(xk−x^k∣ki)2+(yk−y^k∣ki)2+(zk−z^k∣ki)2
Velocity RMSE ( x ^ ) = 1 M ∑ i = 1 M ( x ˙ k − x ˙ ^ k ∣ k i ) 2 + ( y ˙ k − y ˙ ^ k ∣ k i ) 2 + ( z ˙ k − z ˙ ^ k ∣ k i ) 2 \text{Velocity RMSE}(\hat{x})=\sqrt{\frac{1}{M}\sum_{i=1}^{M}(\dot{x}_k-\hat{\dot{x}}_{k|k}^i)^2+(\dot{y}_k-\hat{\dot{y}}_{k|k}^i)^2+(\dot{z}_k-\hat{\dot{z}}_{k|k}^i)^2} Velocity RMSE(x^)=M1i=1∑M(x˙k−x˙^k∣ki)2+(y˙k−y˙^k∣ki)2+(z˙k−z˙^k∣ki)2
ANEES(average normalized estimation error square), n n n 为状态维数, P k ∣ k i \mathbf{P}_{k|k}^i Pk∣ki为第 i i i次仿真滤波器输出的估计协方差
ANEES ( x ^ ) = 1 M n ∑ i = 1 M ( x k − x ^ k ∣ k i ) ′ ( P k ∣ k i ) − 1 ( x k − x ^ k ∣ k i ) \text{ANEES}(\hat{x})=\frac{1}{Mn}\sum_{i=1}^{M}(\mathbf{x}_k-\hat{\mathbf{x}}_{k|k}^i)'(\mathbf{P}_{k|k}^i)^{-1} (\mathbf{x}_k-\hat{\mathbf{x}}_{k|k}^i) ANEES(x^)=Mn1i=1∑M(xk−x^k∣ki)′(Pk∣ki)−1(xk−x^k∣ki)
3.2 跟踪轨迹
三维跟踪轨迹:
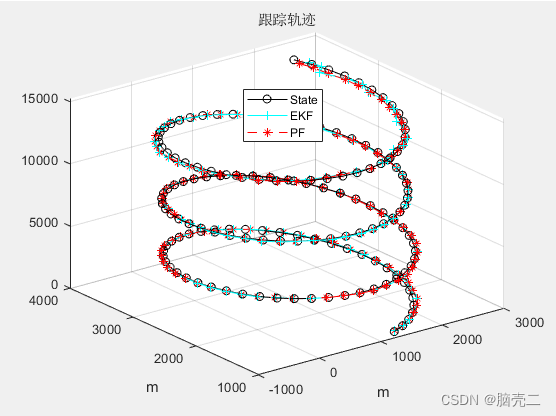
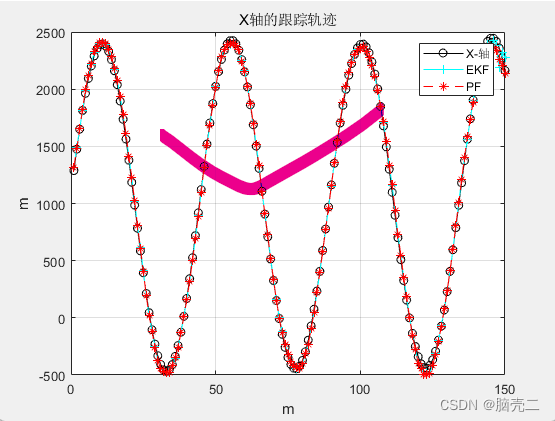
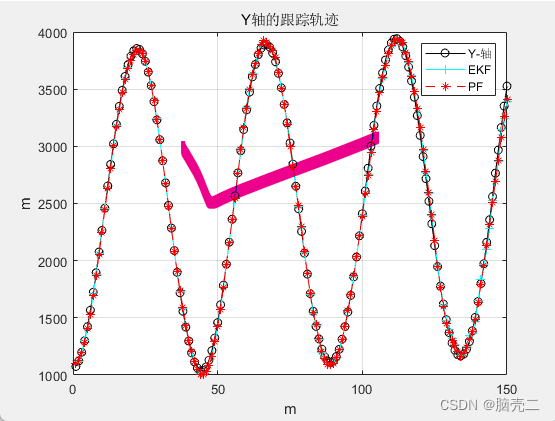
3.3 跟踪误差
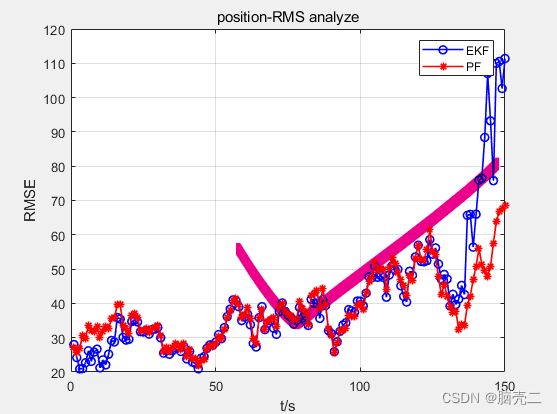
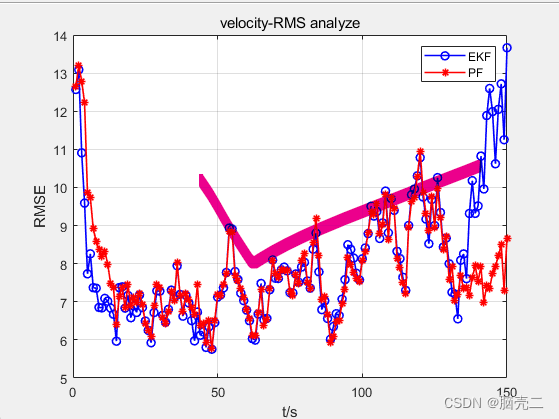
四、部分代码
对于该博客跟踪代码以及问题探讨可以联系:WX:ZB823618313
对于其他跟踪定位问题的代码及探讨也可以联系
代码:系统重采样 (systematic resampling)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 系统重采样子函数
% 输入参数:weight为原始数据对应的权重大小
% 输出参数:outIndex是根据weight筛选和复制结果
function outIndex = systematicR(weight);
N=length(weight);
N_children=zeros(1,N);
label=zeros(1,N);
label=1:1:N;
s=1/N;
auxw=0;
auxl=0;
li=0;
T=s*rand(1);
j=1;
Q=0;
i=0;
u=rand(1,N);
while (T<1)
if (Q>T)
T=T+s;
N_children(1,li)=N_children(1,li)+1;
else
i=fix((N-j+1)*u(1,j))+j;
auxw=weight(1,i);
li=label(1,i);
Q=Q+auxw;
weight(1,i)=weight(1,j);
label(1,i)=label(1,j);
j=j+1;
end
end
index=1;
for i=1:N
if (N_children(1,i)>0)
for j=index:index+N_children(1,i)-1
outIndex(j) = i;
end;
end;
index= index+N_children(1,i);
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%