目录
dense evaluation & multi-crop evaluation
感想
这篇文章在网络结构上没有太大的创新点。但提出了 “ small filter 同样能提取重要特征” 和 “deep network 的重要性”。
论文链接
文章讲解
参考:https://www.datalearner.com/blog/1051559048634862
VGGNet(Visual Geometry Group)是 2014 年又一个经典的卷积神经网络。VGGNet 最主要的目标是试图回答“如何设计网络结构”的问题。随着AlexNet 提出,很多人开始利用卷积神经网络来解决图像识别的问题。一般的做法都是重复几层卷积网络,每个卷积网络之后接一些池化层,最后再加上几个全连接层。而 VGGNet 的提出,给这些结构设计带来了一些标准参考。
在 VGGNet 的论文中,作者主要探究了卷积网络深度的影响。其最主要的贡献是使用较小的卷积核,但较深的网络层次来提升深度学习的效果。在此之前,有很多研究者利用如较小的 receptive window size 和步长等技巧来提升网络效果。而在这边文章中,作者的主要目标是探索深度学习深度的影响。作者固定了网络中其他的参数,通过缓慢的增加网络的深度来探索网络的效果。
先前的网络使用的接受野都是较大的。例如 AlexNet 的第一层使用的是 11x11、步长为 4 的卷积核扫描。而 VGGNet 全部使用很小的 3x3、步长为 1 的卷积核来扫描输入。可以看到,如果将两个这样的卷积核堆起来,和 5x5 的卷积核效果一样,如果是三个堆叠,其效果等同于 7x7。
这里解释一下,“堆叠”的意思是先用 3x3 扫描一次,再用 3x3 对结果继续扫描一次。所以,加入输入的长为 n,那么 3x3 扫描一次的结果是 (n-3)/1+1 = n-2,再扫描一次就是 (n-2-3)/1+1=n-4。如果卷积核是 5x5,那么扫描一次n的输入就是 (n-5)/1+1 = n-4。其结果是一样的。VGGNet 思想就是用更小更深的卷积核代替大的卷积核。
关于卷积核维度计算参考:深度学习卷积操作的维度计算
作者是这样解释为什么使用 3 个 3x3 卷积核堆叠代替一个 7x7 的卷积核的:首先,使用更深的层可以使得函数具有更好的分辨能力;其次,通过这样做也可以减少参数。例如,假设输入是 C 个通道的 3x3 的矩阵,那么堆叠 3 次 3x3 的卷积网络的参数是
,而使用一个 7x7 的卷积核的参数是
。
在之前的论文中,也有人使用了较小的卷积核,但是他们的网络都比 VGGNet 的网络深度浅。
网络结构

PyTorch 框架的代码实现
https://chsasank.github.io/vision/_modules/torchvision/models/vgg.html
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfg = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}疑问
dense evaluation & multi-crop evaluation
参考:https://www.jianshu.com/p/5412d1dec69d
1. dense evaluation
它的设计非常巧妙,并不需要我们显式的在缩放后的图像上 crop 出224*224的图像。而是直接将缩放后的图像输入,再通过将最后的三层全连接层表达为卷积层的形式,来实现在缩放后的图像上密集 crop 的效果。最后将结果平均得到最终的分类结果。
为什么全连接层可以转变为卷积层的形式?
假设一个神经网路前面都是卷积层,后面跟着三层全连接层 f1、f2 和 f3,每个全连接层神经元的个数分别为 n1、n2 和 n3,且经过前面所有的卷积层之后,得到的是 m*m 的 C 个通道的 feature map。一般来说,进入全连接层之前,我们应该首先将这个 feature map 展成一维向量,再与 f1 全连接层相连接。但是实际上,我们可以将 f1 层看作是卷积核大小为 m*m,通道数为 n1 的卷积层,这样卷积后得到的输出是 1*1*n1 的(不加padding),效果和全连接层一样。然后,再将 f2 层看作是卷积核大小为 1*1,通道数为 n2 的卷积层;将f3层看作是卷积核大小为 1*1,通道数为 n3 的卷积层......道理同f1层一样。
这么做为什么能起到密集 crop 的效果?
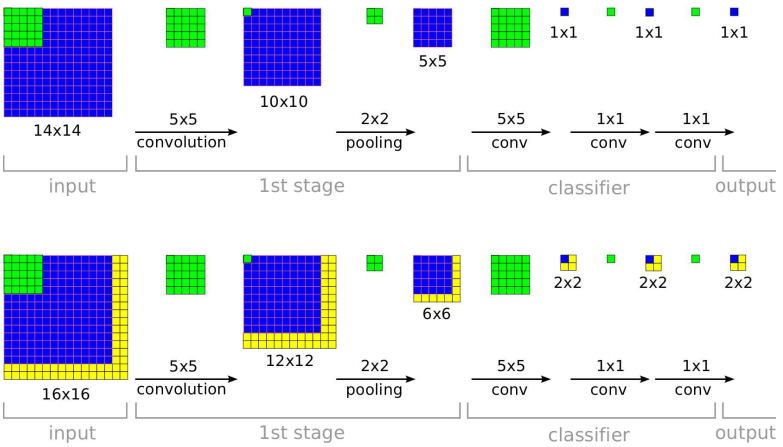
如下图所示 (图片来自于论文 Overfeat),假设训练时网络接受的图像大小是 14*14,最后输出的是它所属的类别。假设测试时缩放后的图片大小为 16*16,在将全连接层转变成卷积层后 ,我们将这个缩放后的图像直接输入给网络,而不是 crop 出 14*14 的大小,可以发现,最后得到的是 4 个结果而不是它上面所示的 1 个。其实这 4 个结果分别相当于在缩放后的图像上 crop 出左上、右上、左下、右下 4 个 14*14 图像的分类结果。然后将多个位置的结果取平均作为整个图像的最终结果。相比于在缩放后的图像上 crop 出多个图像后再分别放入网络进行分类,这种操作省去了许多重复性的运算,所有的卷积操作只需要做一遍即可。值得注意的是,在这个例子中,相当于每滑动两个像素 crop 一个图像,这是因为中间有一个步长为 2 的 2*2 的 pooling 操作。所以有时当pooling 操作较多时,这种方法可能反而没有直接多次 crop 得到的结果精细。
2、 multi-crop evaluation
在 GoogleLeNet 中描述的详细过程如下:将图片缩放到不同的 4 种尺寸(纵横比不变,GoogleLeNet 使用的 4 种尺寸为:缩放后的最短边长度分别为:256, 288, 320 和 352)。对于得到的每个尺寸的图像,取左、中、右三个位置的正方形图像(边长就是最短边的长度。对于纵向图像来说,则取上、中、下三个位置),因此每个尺寸的图像得到 3 个正方形图像;然后再在每个正方形图像的 4 个 crop 顶点和中心位置处 crop 出 224*224 的图像,此外再加上将这个正方形图像缩放到 224*224 大小的图像,因此每个正方形图像得到 6 个224*224 的图像;最后,再将所有得到的 224*224 的图像水平翻转。因此,每个图像可以得到 4*3*6*2=144 个 224*224 大小的图像。将这些图像分别输入神经网络进行分类,最后取平均,作为这个图像最终的分类结果。