1.折半查找定义
折半查找(Binary Search)技术,又称为二分查找。它的前提是线性表中的记录必须是关键码有序(通常从小到大有序),线性表必须采用顺序存储。折半查找的基本思想是:在有序表中,取中间记录作为比较对象,若给定值与中间记录的关键字相等,则查找成功;若给定值小于中间记录的关键字,则在中间记录的左半区继续查找;若给定值大于中间记录的关键字,则在中间记录的右半区继续查找。不断重复上述过程,直到查找成功,或所有查找区域无记录,查找失败为止。
2.折半查找算法
一个有序表数组{0,1,16,24,35,47,59,62,73,88,99},除0下标外共10个数字。对它进行查找是否存在62这个数。折半查找算法如下所示:
/*折半查找*/
int Binary_Search(int *a,int n,int key)
{
int low,high,mid;
low=1; //定义最低下标为记录首位
high=n; //定义最高下标为记录末位
while(low<=high)
{
mid=(low+high)/2; //折半
if(key<a[mid]) //若查找值比中值小
high=mid-1; //最高下标调整到中位下标小一位
else if(key>a[mid]) //若查找值比中值大
low=mid+1; //最低下标调整到中位下标大一位
else
return mid; //若相等则说明mid即为查找到的位置
}
return 0;
}上述代码的具体执行流程
1.程序开始运行,参数a={0,1,16,24,35,47,59,62,73,88,99},n=10,key=62,第3~5行,此时low=1,high=10,如下图所示:

2.6~15行循环,进行查找
3.第8行,mid计算得到5,由于a[5]=47 < key,所以执行了第12行,low=5+1=6,如下图所示:
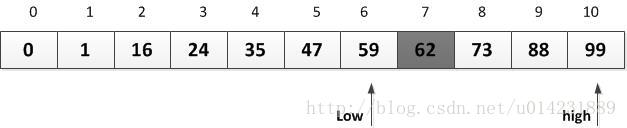
4.再次循环,mid=(6+10)/2=8,此时a[8]=73>key,所以执行第10行,high=8-1=7,如下图所示:

5.再次循环,mid=(6+7)/2=6,此时a[6]=59 < key,所以执行12行,low=6+1=7,如下图所示:
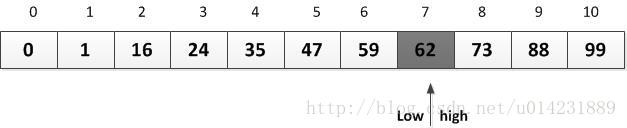
6.再次循环,mid=(7+7)/2=7,此时a[7]=62=key,查找成功,返回7。
3.折半查找实现(Java)
实现的目录结构

折半查找类
package com.red.binary.search;
public class BinarySearch {
public int binarySearch(int[] arr, int key) {
int low = 0;
int high = arr.length-1;
while(low<=high) {
int middle = (low+high)/2;
if(arr[middle]==key) {
return middle;
}else if(arr[middle] > key) {//如果中间值大于key,则说明要在中间值左边去找key,即high=middle-1
high = middle-1;
}else {
low=middle+1;
}
}
return -1;
}
}测试类
package com.red.binary.search;
public class BinarySearchTest {
public static void main(String[] args) {
int[] arr = new int[]{1,16,24,35,47,59,62,73,88,99};
BinarySearch bs = new BinarySearch();
int search = bs.binarySearch(arr, 62);
System.out.println("key所在位置:" + search);
}
}输出结果
key所在位置:6
4.折半查找复杂度分析
该算法的效率非常高,但到底高多少?关键在于此算法的时间复杂度分析。首先,我们将这个数组的查找过程绘制成一棵二叉树,如下图所示,从图上就可以理解,如果查找的关键字不是中间记录47的话,折半查找等于是把静态有序查找表分成了两棵子树,即查找结果只需要找其中的一半数据记录即可,等于工作量少了一半,然后继续折半查找,效率当然是非常高了。

根据二叉树的性质,具有n个结点的完全二叉树的深度为
不过由于折半查找的前提条件是需要有序表顺序存储,对于静态查找表,一次排序后不再变化,这样的算法已经比较好了。但对于需要频繁执行插入或删除操作的数据集来说,维护有序的排序会带来不小的工作量,那就不建议使用。