Label
经典决策树:单棵树的ID3、C4.5、CART
决策树组合:基于bagging与boosting思想,出现了
随机森林(random forest)
极端随机树(ET)
梯度提升决策树(Gradient Boosting decision tree,GBDT)
XGB
LGB
最初的决策树(单棵,根节点+内部节点+叶节点,不断细分)
eg.以大米种类的分类问题为例
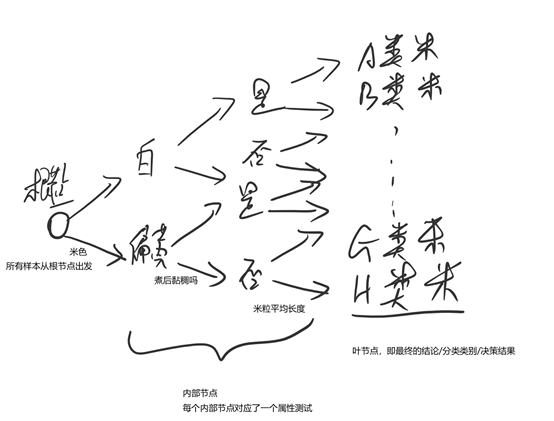
每一条从根节点到叶节点的路径均对应了一种可能的样本
上面的内部节点有三个——”米色“、”黏稠“、”米粒长度“,上面的顺序是一个例子,但也可以有其他的判断顺序。问题来了,这些内部节点中,先判断哪个再判断哪个怎么定才能实现最佳的效果(快速、判得准)。抽象化,就是决策树怎么生长的问题。
一般地,决策树的学习过程分为3个部分
1、特征选择
特征选择是指从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准,从而衍生出不同的决策树算法。
2、决策树生成
根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。 树结构来说,递归结构是最容易理解的方式。
3、剪枝
决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。
对于单棵树,按照特征选择的评估标准的不同有不同的算法,经典的有ID3、C4.5、CART三种,这三种算法都是基于信息论的。
ID3:
先引入信息熵与信息增益。
信息熵就是香农熵(自信息),针对分类系统而言
Shannon Entropy =
上面,N是最终的类别数目,pi是第i类别的概率。
信息增益是针对某个特征而言的:对于一个特征k∈[1~M],有ta没ta时系统的香农熵之差即为该特征的信息增益。(一个实例:https://blog.csdn.net/fly_time2012/article/details/70210725)
注:除去某个特征,样本集分为m个(m是该特征可能取值数),计算各个子集的香农熵,再加权平均即为除去该特征之后样本的香农熵。
而ID3的思想就是每次选择当前特征时,计算所有特征的信息增益,然后选择信息增益最大的特征作为当前节点的特征。(等价于选取删去后子样本集的香农熵最小的特征,香农熵越小说明样本集越纯)
C4.5:
ID3有个缺点,就是当某个特征取值很多时,那么每个特征对应的样本数可能很少,此时该特征增益会很大,ID3会认为这个特征很适合作为节点,但实际上该节点分支太多,模型的泛化能力有限,不适合作为判断的节点。
为解决这个问题,C4.5算法提出了新的指标——信息增益率,即信息增益与分裂信息值之比。(类似标幺化的概念)
和ID3的不同就在于,每个节点处按照信息增益率最大选取特征。
CART:
C4.5解决了一个问题,但是还是要注意到①C4.5、ID3的计算过程涉及到对数运算,相比多项式计算的计算量要大很多。
CART引入了基尼系数这个概念。(基尼系数可以看作是对熵的一个近似)
基尼系数:从某个样本集中随机取出某个类别样本并将其错误归类的概率。
Gini = Σpi(1-pi),i∈(1,N),N为类别数。pi为随机从样本集中抽取一个样本,该样本为i类别的概率。
CART算法的思想就是,在每一个节点,看哪一个特征去掉后样本集的基尼系数最小,就选哪个特征作为当前节点的判断依据。(基尼系数越小则样本集越纯)
另一方面,CART树是二叉树,不同于ID3、C4.5是多叉树。举个例子,有个特征有(A\B\C)三种可能,则ID3、C4.5算法会在某个节点分出A、B、C三条树枝,而CART算法则会先在A、BC/B、AC/C、AB三种可能中进行选择,假设选了A、BC,则下一个节点再形成B、C的二叉树,即一个特征用多个节点来进行描述,每个节点是二叉树。
在计算机中,二叉树的运算效率要高很多。
| 算法 |
支持模型 |
树结构 |
特征选择 |
连续值处理 |
缺失值处理 |
剪枝 |
| ID3 |
分类 |
多叉树 |
信息增益 |
不支持 |
不支持 |
不支持 |
| C4.5 |
分类 |
多叉树 |
信息增益比 |
支持 |
支持 |
支持 |
| CART |
分类,回归 |
二叉树 |
基尼系数,均方差 |
支持 |
支持 |
支持 |
单棵的决策树容易出现过拟合的现象,泛化能力有限。这时就出现了集成学习(从一颗决策树扩展到一群决策树,后者中单独一颗效果可能不咋地,但是合起来的组合效果要胜过单棵决策树)。大白话就是三个臭皮匠顶一个诸葛亮。
根据组合算法的不同就形成了不同的决策树类算法,常用的包括RF(random forest,随机森林)、ET(extremely randomized tree,极端随机树)、GBDT(gradient boost decision tree,梯度提升决策树)、XGB(extreme gradient boost)和LGB(light gradient boost)等。
组合的算法各种各样,其基本思想主要为bagging和boosting两类。
bagging,有放回、等权重地均匀采样
boosting,每一轮迭代的训练集不变,但是采样权重回根据上一轮预测结果发生改变。分类误差越大则下一轮迭代的采样权重越大。(即重点学习上一次错误分类的样本)
一句行话:bagging可以减小variance,boosting可以减小bias。
bagging是均匀采样,那么有![]() ,因为Xi与X同分布。减小方差的实质是通过拉近训练集与验证集的分布来减小过拟合的程度。可以并行生成随机树,速度快。
,因为Xi与X同分布。减小方差的实质是通过拉近训练集与验证集的分布来减小过拟合的程度。可以并行生成随机树,速度快。
boosting是有选择地重点采样,抽取的样本不独立,故无法减小方差,其本质是用贪心算法来不断减小损失函数(即预测结果与实际结果的距离)从而减小偏差。减小偏差的具体体现就是减小欠拟合的程度。理论上boosting只能穿行生成,因为本次权重依赖于上一次结果。
bagging策略的典型代表就是random forest,该算法同时对样本和特征进行bagging得到若干决策树,最后将各决策树组合到一起。
p.s.随机森林的生成过程
~从原始样本中采用有放回抽样的方法选取n个样本;
~对n个样本选取a个特征中的随机k个,用建立决策树的方法获得最佳分割点;
~重复m次,获得m个决策树;
~对输入样例进行预测时,每个子树都产生一个结果,采用多数投票机制输出。
与之类似的是ET,也有随机的味道,但不是bagging的随机采样,该算法取所有样本与特征,但不同于ID3、C4.5、CART等对决策顺序进行最优排序,而是随机生成决策顺序得到若干决策树并组合。
boosting策略的典型代表是gbdt,每一轮迭代中样本的选择权重是不均匀的,取决于上一轮迭代的预测结果。
xgb是对gbdt的优化改进:1、目标函数中加入了正则项来控制模型的复杂度,替代原来的剪枝方法。2、利用了one-hot编码等情况中的特征稀疏性。(仅对特征值为非缺失值的样本的特征进行遍历)3、支持列抽样(同random forest)。4、数据事先排序并按block结构保存,有利于并行运算(树的生成还是串行的,这里说的并行计算指并行计算各个特征的增益或是基尼系数)。除此之外,xgb还通过一种可并行的近似直方图算法来高效生成候选的分割点。5、对损失函数进行了优化,gbdt只用到了其一阶导数信息,而xgb同时用到其一阶导与二阶导。
lgb则是在xgb基础上进一步改进,加快了训练速度(非常快),减小了内存的使用量。
1、内存需求小:xgb使用基于pre-sorted的决策树算法,而lgb使用基于histogram的决策树算法。histogram算法占用的内存很小:pre-sorted需要两倍数据大小的内存空间,一半用于数据(float32),一半用于存放排好序的索引,而histogram不需要存放索引,且特征值只需要存放离散后的值,用uint8即可,故内存需求仅为pre-sorted的1/8。
2、计算速度快:决策树算法的主要操作包括“寻找分割点”与“数据分割”两步,pre-sorted算法和histogram算法在“寻找分割点”上的时间复杂度是一致的;但是在“数据分割”上histogram要快,histogram所有特征共享一张索引,而pre-sorted一个特征对应一张索引,若集合level-wise,pre-sorted也可以共用一张索引,但是会带来很多随机访问的问题,速度仍不及histogram。此外,histogram算法还减少了计算分割点增益的次数。
3、通信代价小:histogram算法的通信代价远远小于pre-sorted,可用于分布式计算。
但是,histogram不能找到很精确的分割点,训练误差不如pre-sorted算法,可以说是牺牲一定精度来换取速度。需要指出的是,这种粗犷的分割相当于自带正则效果,所以测试集的误差两种决策树算法差距不大。
4、除此之外,lgb使用带最大深度限制的leaf-wise(按叶子生长)来替代leval-wise(按层生长)策略,由原来的对一层中所有叶子进行分裂变为对一层中分裂增益最大的叶子进行分裂。leaf-wise易发生过拟合,需要限制最大深度配合。
5、lgb还使用了直方图做差加速。(一个叶子的直方图可以由其父节点直方图与兄弟的直方图做差得到)。