决策树算法主要分为三类:
ID3、C4.5、CART算法
以ID3算法为例:
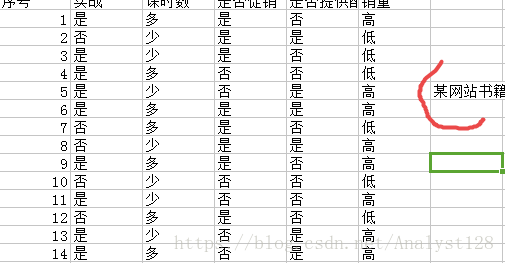
对上表某图书销量进行预测.
思考:建立测试模型,各个变量数据权重?数据的转化?
重点在于:计算各个信息熵(数据预处理),可参考百度百科内容
决策树算法模块:
关注点:对数据需要进行预处理,转化为结构化数据,然后进行分析处理,信息熵的计算,权重大小的比较
数据的预处理模块:
#数据的处理模块
fname="C:/Users/Administrator/Desktop/pandashesuanfa/lesson.csv"
df=pd.read_csv(fname) #备注:需要将csv文件转为utf-8格式再进行读取文件
#print(df)
x=df.iloc[:,1:5].as_matrix() #提取变量值,并转化为数组
y=df.iloc[:,5].as_matrix() #等价于df.iloc[:,5:6]
for i in range(0,len(x)): #遍历所有数据
for j in range(0,len(x[i])):
thisdata=x[i][j]
if(thisdata=="是" or thisdata=="多" or thisdata=="高"):
x[i][j]=int(1) #1的类型转为整型
else:
x[i][j]=int(-1)
for i in range(0,len(y)):
thisdata=y[i]
if(thisdata=="高"):
y[i]=1
else:
y[i]=-1
'''
容易错的地方:直接拿数据进行训练
原因dtype=object类型不对,
首先应该转化格式,将x,y转化为数据框,然后转化为数组并指定格式
'''
xf=pd.DataFrame(x)
yf=pd.DataFrame(y)
x2=xf.as_matrix().astype(int)
y2=yf.as_matrix().astype(int)建立决策树模块:
#建立决策树
from sklearn.tree import DecisionTreeClassifier as DTC
dtc=DTC(criterion="entropy")
dtc.fit(x2,y2)
#方法一:通过代码实现输出预测结果数据,如下
import numpy as np
x3=np.array([[1,-1,-1,1],[1,1,1,1,],[-1,1,-1,1],[-1,-1,1,1]]) #预测四个数据的销量高低
rst=dtc.predict(x3) #利用决策树的方法predict进行计算
print(rst) #得出[ 1 1 -1 -1]四个预测结果:高,高,低,低
'''
#方法二:可视化决策树,人工根据决策树图形进行分析预测结果
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
with open("tree.dot","w") as file: #以写入的方式创建并打开
file=export_graphviz(dtc,feature_names=["shizhan","keshishu","chu3333xiao","ziliao"],out_file=file)
'''
输出结果:[ 1 1 -1 -1]:高、高、低、低完整代码如下:
#决策树ID3算法
import pandas as pd
'''
fname="C:/Users/Administrator/Desktop/pandashesuanfa/lesson1.xls"
df=pd.read_excel(fname)
编译通过
'''
fname="C:/Users/Administrator/Desktop/pandashesuanfa/lesson.csv"
df=pd.read_csv(fname) #备注:需要将csv文件转为utf-8格式再进行读取文件
#print(df)
x=df.iloc[:,1:5].as_matrix() #提取变量值,并转化为数组
y=df.iloc[:,5].as_matrix() #等价于df.iloc[:,5:6]
for i in range(0,len(x)): #遍历所有数据
for j in range(0,len(x[i])):
thisdata=x[i][j]
if(thisdata=="是" or thisdata=="多" or thisdata=="高"):
x[i][j]=int(1) #1的类型转为整型
else:
x[i][j]=int(-1)
for i in range(0,len(y)):
thisdata=y[i]
if(thisdata=="高"):
y[i]=1
else:
y[i]=-1
'''
容易错的地方:直接拿数据进行训练
原因dtype=object类型不对,
首先应该转化格式,将x,y转化为数据框,然后转化为数组并指定格式
'''
xf=pd.DataFrame(x)
yf=pd.DataFrame(y)
x2=xf.as_matrix().astype(int)
y2=yf.as_matrix().astype(int)
#建立决策树
from sklearn.tree import DecisionTreeClassifier as DTC
dtc=DTC(criterion="entropy")
dtc.fit(x2,y2)
#方法一:通过代码实现输出预测结果数据,如下
import numpy as np
x3=np.array([[1,-1,-1,1],[1,1,1,1,],[-1,1,-1,1],[-1,-1,1,1]]) #预测四个数据的销量高低
rst=dtc.predict(x3) #利用决策树的方法predict进行计算
print(rst) #得出[ 1 1 -1 -1]四个预测结果:高,高,低,低
'''
#方法二:可视化决策树,人工根据决策树图形进行分析预测结果
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
with open("tree.dot","w") as file: #以写入的方式创建并打开
file=export_graphviz(dtc,feature_names=["shizhan","keshishu","chu3333xiao","ziliao"],out_file=file)
'''