目录
4)LightGBM (基于决策树算法的分布式梯度提升框架)
本人才疏学浅,之前一直将分类树和回归树搞混,经过资料查证最终弄明白了一点点。接下来九与大家分享一下自己的心得。
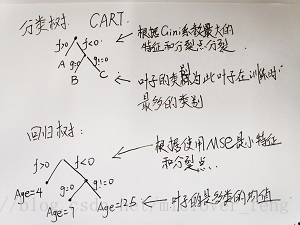
一、分类树和回归树
分类树的节点分裂:信息增益(比),Gini系数;
回归树的节点分裂:预测误差(均方误差,对数误差,指数误差)
对于回归,节点不在是类别,而是预测值,那么怎么确定?
有的是节点内样本均值,有的是最优化算出来的(XGBoost)
| ID3/C4.5决策树 | 信息熵 | |
|---|---|---|
| CART决策树 | 基尼系数 | |
| xgboost决策树 | 二阶泰勒展开 |
二、集成学习(Bagging和Boosting)
1、Bagging方法
有放回地采样同数量样本训练每个学习器, 然后再一起集成(简单投票); 学习器间不存在强依赖关系, 学习器可并行训练生成, 集成方式一般为投票; Random Forest 属于Bagging的代表, 放回抽样, 每个学习器随机选择部分特征去优化;(样本选取的随,机树中每个节点的分裂属性集合也是随机选择确定的)
2、Boosting方法
使用全部样本(可调权重)依次训练每个学习器, 迭代集成(平滑加权);学习器之间存在强依赖关系、必须串行生成, 集成方式为加权和;
1)Adaboost
属于Boosting, 采用指数损失函数替代原本分类任务的0/1损失函数;原始的AdaBoost算法是在算法开始的时候,为每一个样本赋上一个权重值,初始的时候,大家都是一样重要的。在每一步训练中得到的模型,会使得数据点的估计有对有错,我们就在每一步结束后,增加分错的点的权重,减少分对的点的权重,这样使得某些点如果老是被分错,那么就会被“重点关注”,也就被赋上一个很高的权重。然后等进行了N次迭代(由用户指定),将会得到N个简单的分类器(basic learner),然后我们将它们组合起来(比如说可以对它们进行加权、或者让它们进行投票等),得到一个最终的模型。
2)GBDT
属于Boosting的优秀代表, 对函数残差近似值进行一阶梯度下降, 用CART回归树做学习器, 集成为回归模型; GBDT(Gradient Boosting Decison Tree)中的树都是回归树,GBDT用来做回归预测,调整后也可以用于分类(设定阈值,大于阈值为正例,反之为负例),可以发现多种有区分性的特征以及特征组合。GBDT是把所有树的结论累加起来做最终结论的,GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差(负梯度),这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。 Boosting的最大好处在于,每一步的残差计算其实变相地增大了分错instance的权重,而已经分对的instance则都趋向于0。这样后面的树就能越来越专注那些前面被分错的instance。
3)Xgboost
属于Boosting的集大成者, 对函数残差近似值进行梯度下降, 用CART回归树做学习器,迭代时利用了二阶梯度信息, 集成模型可分类也可回归. 由于它可在特征粒度上并行计算, 结构风险和工程实现都做了很多优化, 泛化, 性能和扩展性都比GBDT要好。
(一)改进残差函数
不用Gini作为残差,用二阶泰勒展开+树的复杂度(正则项)
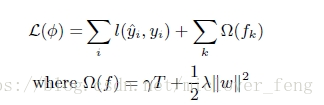
第t次的loss:
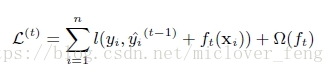
对上式做二阶泰勒展开:g为一阶导数,h为二阶导数
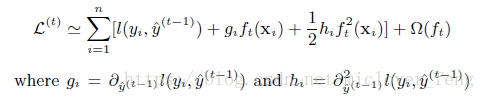
带来如下好处:1.可以控制树的复杂度;2.带有关于梯度的更多信息,获得了二阶导数;3.可以用线性分类器;
(二)采用预排序
因为每一次迭代中,都要生成一个决策树,而这个决策树是残差的决策树,所以传统的不能并行,但是陈天奇注意到,每次建立决策树,在分裂节点的时候,比如选中A特征,就要对A进行排序,再计算残差,这个花很多时间,于是陈天奇想到,每一次残差计算好之后,全部维度预先排序,并且此排序是可以并行的,并行排序好后,对每一个维度,计算一次最佳分裂点,求出对应的残差增益。于是只要不断选择最好的残差作为分裂点就可以。也就是说,虽然森林的建立是串行的没有变,但是每一颗树枝的建立就变成是并行的了,带来的好处:
1.分裂点的计算可并行了,不需要等到一个特征的算完再下一个了
2.每层可以并行:
当分裂点的计算可以并行,对每一层,比如分裂了左儿子和右儿子,那么这两个儿子上分裂哪个特征及其增益也计算好了
(三)Shrinkage(缩减)【相当于学习速率】
XGBoost在进行完一次迭代时,会将叶子节点的权值乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。(GBDT也有学习速率)
(四)列抽样
XGBoost借鉴了随机森林的做法,支持列抽样,不仅防止过拟合,还能减少计算。Xgboost类似于gbdt的优化版,不论是精度还是效率上都有了提升。与gbdt相比,具体的优点有:损失函数是用泰勒展式二项逼近,而不是像gbdt里的就是一阶导数;对树的结构进行了正则化约束,防止模型过度复杂,降低了过拟合的可能性;节点分裂的方式不同,gbdt是用的gini系数,xgboost是经过优化推导后的
4)LightGBM (基于决策树算法的分布式梯度提升框架)
lightGBM 与 XGBoost的区别:
(一)切分算法(切分点的选取)
XGBoost使用的是pre-sorted算法(对所有特征都按照特征的数值进行预排序,基本思想是对所有特征都按照特征的数值进行预排序;然后在遍历分割点的时候用O(#data)的代价找到一个特征上的最好分割点最后,找到一个特征的分割点后,将数据分裂成左右子节点。优点是能够更精确的找到数据分隔点;但这种做法有以下缺点:
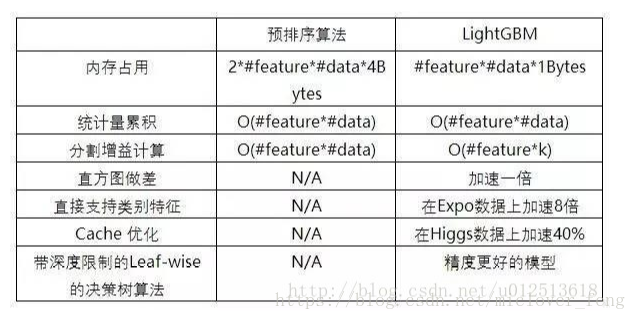
1)空间消耗大,需要保存数据的特征值以及特征排序的结果(比如排序后的索引,为了后续快速计算分割点),需要消耗两倍于训练数据的内存
2)时间上也有较大开销,遍历每个分割点时都需要进行分裂增益的计算,消耗代价大
3)对cache( 快速缓冲贮存区)优化不友好,在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
LightGBM使用的是histogram算法,基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点;

优点:
1)占用的内存更低,只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。
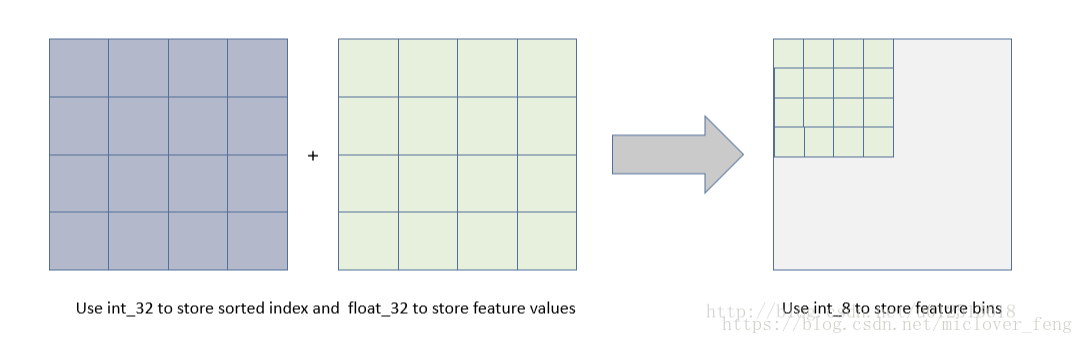
2)降低了计算的代价:预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data#feature)优化到O(k#features)。(相当于LightGBM牺牲了一部分切分的精确性来提高切分的效率,实际应用中效果还不错)
(二)决策树生长策略上:
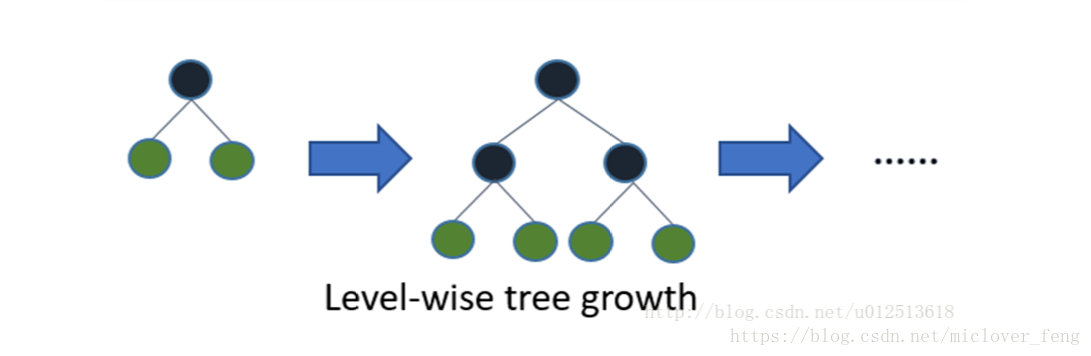
XGBoost采用的是带深度限制的level-wise生长策略,Level-wise过一次数据能够同时分裂同一层的叶子,容易进行多线程优化,不容易过拟合;但不加区分的对待同一层的叶子,带来了很多没必要的开销(因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂)
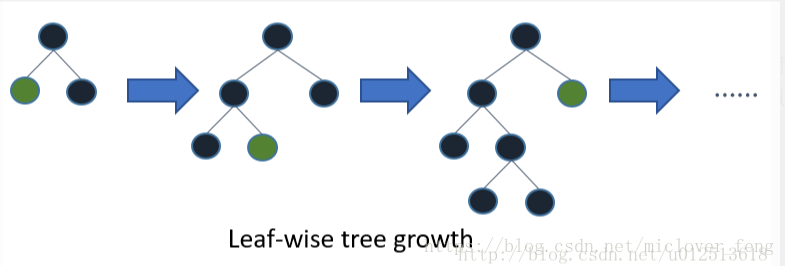
LightGBM采用leaf-wise生长策略,每次从当前所有叶子中找到分裂增益最大(一般也是数据量最大)的一个叶子,然后分裂,如此循环;但会生长出比较深的决策树,产生过拟合(因此 LightGBM 在leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合)。
(三)histogram 做差加速:
一个容易观察到的现象:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。利用这个方法,LightGBM可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。

(四)直接支持类别特征(即不需要做one-hot编码)【注:这一点十我面试宜信公司一直溜掉的一点】
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的one-hot编码特征,降低了空间和时间的效率。而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的one-hot编码展开。并在决策树算法上增加了类别特征的决策规则。在Expo数据集上的实验,相比0/1展开的方法,训练速度可以加速8倍,并且精度一致。
参考资料:
李航《统计学习方法》
http://www.cnblogs.com/jiangxinyang/p/9337094.html
https://blog.csdn.net/wjwfighting/article/details/82532847
声明:本人从互联网搜集了一些资料整理,由于查找资料太多,好多内容出处不能记得,如有侵权内容,请各位博主及时联系我,我将尽快修改,并注明出处,再次感谢各位广大博主的资料。