*此系列为斯坦福李飞飞团队的系列公开课“cs231n convolutional neural network for visual recognition ”的学习笔记。本文主要是对module 1 的part2 Linear classification: Support Vector Machine, Softmax 的翻译与学习。
KNN并不适用于图像识别,其原因在于,KNN的时间复杂度和空间复杂度都很高。(在测试阶段,我们需要将测试图像和训练集里的每一张图像进行比较。)
线性分类器
线性分类器中有两个重要的部分:判别函数( score function)用于建立数据和分类之间的对应关系,和损失函数(loss function )用于估计预测值与真实值之间的误差。线性分类器的问题可以概括为用最优化方法求取得分函数中的最佳参数的问题。何为最佳参数?就是使得损失函数最小的那组参数。
首先,我们需要定义每一类图像的判别函数,确定图像中的像素值与得分函数的映射关系。仍旧是以CIFAR-10为例,判别函数是要建立基于像素的图像和图像分类之间的映射关系,用数学的语言表示就是:
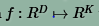
其中训练集中的每一张图片都属于集合RD,D是每一张图像的大小,每一张图象的标签都属于集合Rk,k是类别总数。线性分类器就是要建立映射函数:
f(Xi,W,b)=WXi+b
W是一个矩阵,大小为K*D,通常被称为权值(其实也是参数)。b是偏置向量,b会影响最终的输出,但并没有直接和图像Xi作用。需要注意的是:
1.W中的每一行是对一个类别的判别。
2.图像和标签是给定的,我们所要做的就是调整W和b,提高判别函数的正确率。
3.正确的分类判别函数的输出值应当高于其他不正确的判别函数的输出值。
下图是一个具体的线性分类器进行图像识别的例子:

假设上图中,猫的图像只有4个单色像素,不考虑RGB三个通道,只考虑灰度图像。我们将图像拉伸成一个列向量,与W矩阵相乘,可以看出,在上图中,猫这一类别的判别函数的权值取得并不理想,通过判别函数,电脑更倾向于认为这是一只狗而不是猫。
值得注意的是,线性分类器要计算三个颜色通道的权值总和,通过正确的设定权值参数,在图像的某个颜色通道的某个区域,分类器就可以计算出图像究竟是“像”还是“不像”某一个类别。举例来说,例如,对于“船”这个分类,如果图像的某一部分出现大量的蓝色像素,那么就可以在蓝色的通道中,设置正(positive)的权值。而在红色和绿色的通道,则设定负(negative)的权值。
将图像看作是高维空间中的一个点
既然图像可以被拉伸为高维列向量,我们不妨将图像看作是高维空间中的一个点,以CIFAR-10 数据集为例,我们可以把一副图像看成是3072(32x32x3像素)维空间中的一个点。我们无法将3072维空间可视化,但是我们可以将整个空间划分成两块。如下图所示:
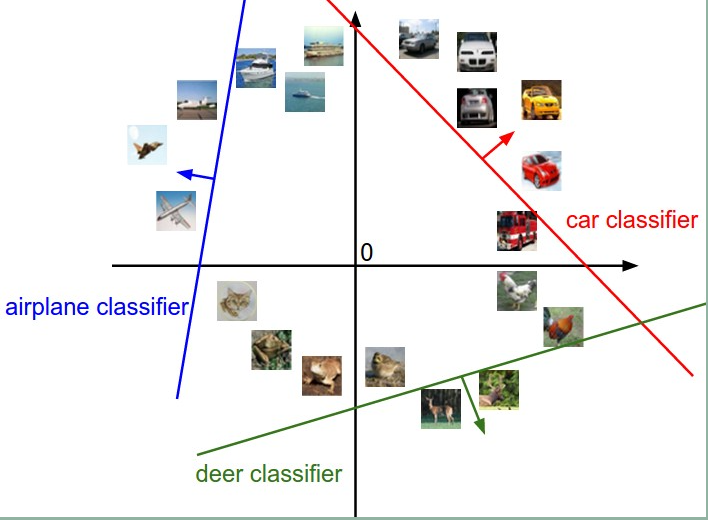
在上图中,以汽车为例,红色的直线是汽车这个类别的判别函数取值为0的空间,箭头方向表示判别函数取值增长的方向,红线右边取值为正,左边取值为负。
W中的每一行都是一个类别的判别函数。在几何上的可以做这样的解释:如果我们改变了W中的某一行,相应的判别直线就会向其他方向旋转。偏置向量b使得判别直线在高维空间中平移。如果没有偏置向量b,所有的判别直线都将通过原点。(因为Xi=0时,无论W是多少,输出函数都为0.)
线性分类器也可以看作是模板匹配。
判别函数可以看作是某个类别的模板,这个模板是通过对训练集进行机器学习后获得的。在对测试集的图像进行分类时,每一张图像和每一个类别的模板分别做内积。找出最“符合”的模板。线性分类器也可以看做是邻域分类器。不同之处在于:
1.我们不需要和训练集的每一幅图像求算距离,而是由训练集自动学习出合适的模板,再跟模板求距离。
2.求算的距离并不是欧氏距离,而是内积。

上图是线性分类器生成的模板。不出所料,船的模板有很多蓝色。马的模板有两个头,这可能是因为在训练集中,马的图像中,包含面向两个方向站立的。汽车图片面向各个方向,所以模板里围成了一个圈,模板呈现红色,这可能是由于训练集里汽车的图像红色居多。线性分类器并不能区分汽车的颜色,型号等信息,但是神经网络可以。
偏置向量处理
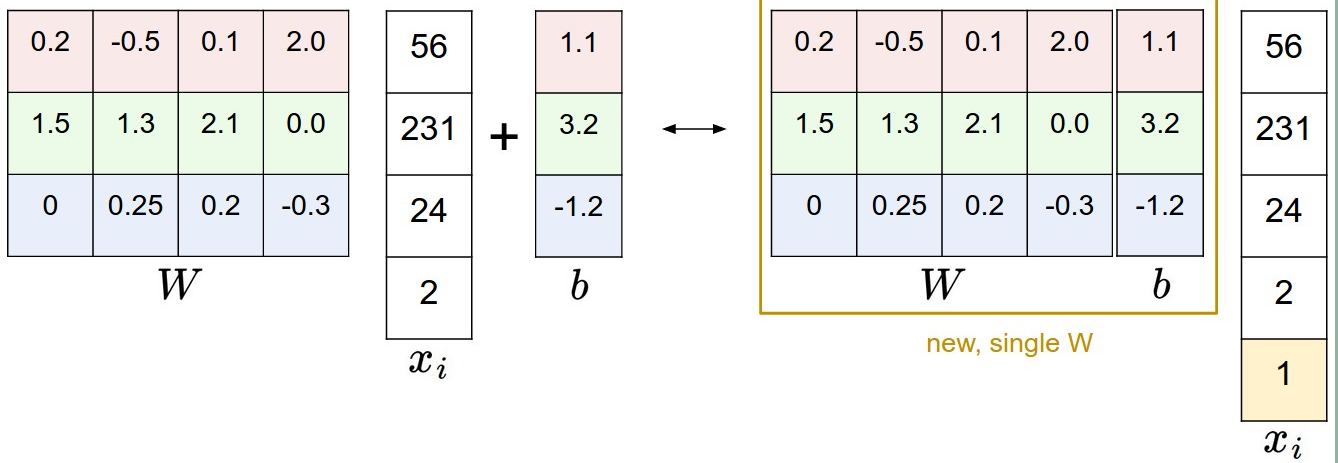
有两种处理方式:左边根据方程来,右边是在W中加上一列b,每一幅图片拉伸成列向量之后再加一行,这一行的元素是1.
图像数据预处理
在机器学习中,首先需要“将数据居中”。例如,图像的原始像素取值范围是在[0,255],应当居中调整为[-127,127],再归一化到[-1,1]区间。
损失函数
用于衡量判别函数的效果,如果判别函数效果好,损失函数的取值低,反之亦然。我们要做的就是通过调整判别函数中的权值W,减小损失函数,获得更好的判别效果。
多类别支持向量机损失(Multiclass Support Vector Machine loss)
定义式:
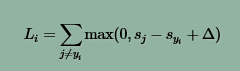
上式表示第i个样本(图像Xi,标签Yi)的损失函数,式中Sj是将图像Xi带入第j类判别函数后,得到的输出。
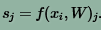
Δ是固定差值。
在几何上,损失函数的值表示样本距离边缘的程度。它用于度量判别函数的性能。

Multiclass Support Vector Machine要求对正确类别的判别函数输出值高于对错误类别图像的判别函数输出值。如果有某个类别的判别函数值落在了红色区域内,就会造成累计误差。我们需要做的,就是通过训练集调整权值W,找出满足条件并且损失函数值最小的W。
损失函数标准化
在上面的损失函数定义式中,有一个bug。如果有一个矩阵W可以使得分类器正确的分类所有的样本。所有Xi的损失函数Li都为0。此时用参数λ与W相乘得到 λW(λ>1),也使得所有损失函数都是0.所有的判别函数边界都重合。这会造成模棱两可的歧义。(当样本落在判决函数上,如何分类?)
为了解决这个歧义,我们需要修改损失函数的定义式。首先我们引入了一个新的式子,叫做惩罚( regularization penalty )

R(W)并不是关于数据的函数,而是关于权值矩阵W的函数。
修正后的损失函数有两部分组成:
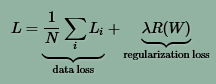
展开后,得到新的损失函数如下:
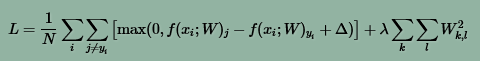
其中,N是训练样本的个数。
加入惩罚后,可以筛选出更合适的W。例如,对于样本x=[1,1,1,1],现在有两个W矩阵w1=[1,0,0,0],
w2=[0.25,0.25,0.25,0.25],与X做内积的结果都是1。进过修正之后的损失函数W1的惩罚是1,W2 的惩罚是0.25。按照新的规则,选取W2作为权值矩阵。因为W2更小,也更加离散化。这样选取出的W2可以考虑到所有方向上的情况,用它来做图像分类时,可以应对过拟合。
损失函数的python代码如下:
def L_i(x, y, W):
"""
unvectorized version. Compute the multiclass svm loss for a single example (x,y)
- x is a column vector representing an image (e.g. 3073 x 1 in CIFAR-10)
with an appended bias dimension in the 3073-rd position (i.e. bias trick)
- y is an integer giving index of correct class (e.g. between 0 and 9 in CIFAR-10)
- W is the weight matrix (e.g. 10 x 3073 in CIFAR-10)
"""
delta = 1.0 # see notes about delta later in this section
scores = W.dot(x) # scores becomes of size 10 x 1, the scores for each class
correct_class_score = scores[y]
D = W.shape[0] # number of classes, e.g. 10
loss_i = 0.0
for j in xrange(D): # iterate over all wrong classes
if j == y:
# skip for the true class to only loop over incorrect classes
continue
# accumulate loss for the i-th example
loss_i += max(0, scores[j] - correct_class_score + delta)
return loss_i
def L_i_vectorized(x, y, W):
"""
A faster half-vectorized implementation. half-vectorized
refers to the fact that for a single example the implementation contains
no for loops, but there is still one loop over the examples (outside this function)
"""
delta = 1.0
scores = W.dot(x)
# compute the margins for all classes in one vector operation
margins = np.maximum(0, scores - scores[y] + delta)
# on y-th position scores[y] - scores[y] canceled and gave delta. We want
# to ignore the y-th position and only consider margin on max wrong class
margins[y] = 0
loss_i = np.sum(margins)
return loss_i
def L(X, y, W):
"""
fully-vectorized implementation :
- X holds all the training examples as columns (e.g. 3073 x 50,000 in CIFAR-10)
- y is array of integers specifying correct class (e.g. 50,000-D array)
- W are weights (e.g. 10 x 3073)
"""
# evaluate loss over all examples in X without using any for loops
# left as exercise to reader in the assignment