本文在CIFAR-10数据集上举例。CIFAR-10的训练集有50000张32*32*3的图片,包括10个类别。因此形成一个32*32*3 = 3072维的样本空间,此空间中其中包括50000个样本点。
一个机器学习(包括深度学习)多分类器的生命周期包括3大模块:
1.Score Function:
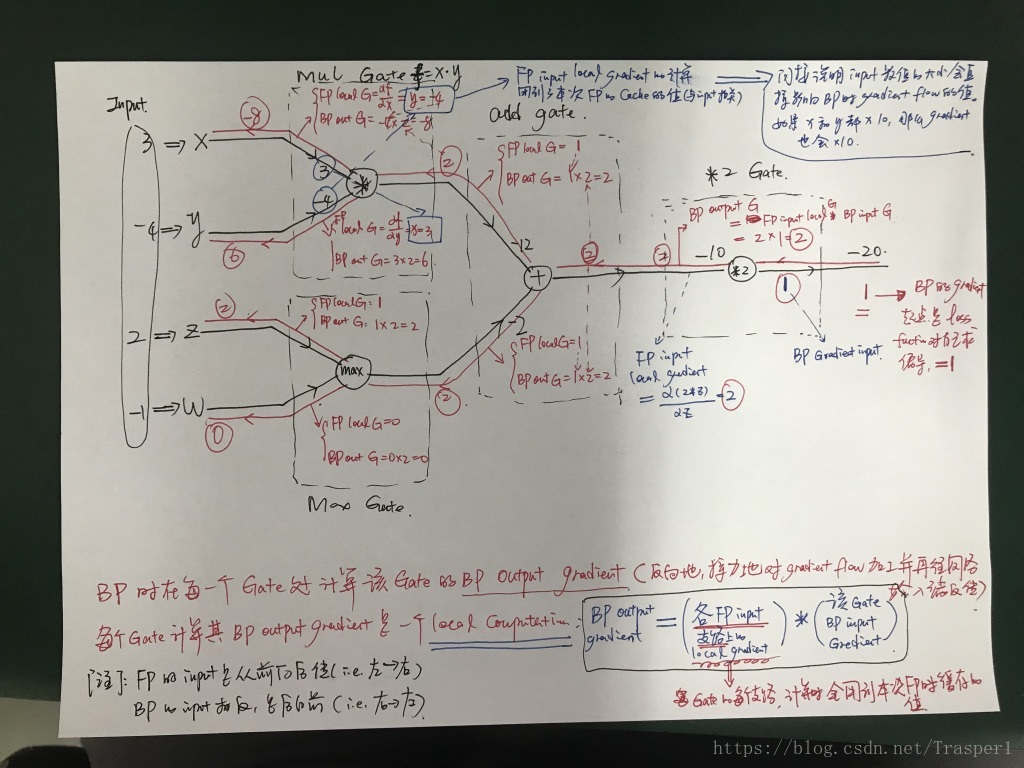
将3072维的input xi转化成一个10维的classfication score vector。这个模块可以plug in包括线性分类器、Neural Network, CNN, RNN等等。score function就是一个mapping,把高维input vector map到想要的低维输出空间上去。linear classifier用matrix multiplication完成了这个mapping,而NN、CNN、RNN则是用多个连接主义的matrix mul、filtering等操作来实现这个mapping。
(1)线性分类器:f(x) = W * x + b:
这里W是10 * 3072 维的matrix,x是3072 * 1维的一个input image flattened vector,b是10 * 1 维的scalar bias values。对于此线性分类器的训练,就是在学习W和b。当W和b训练完成固定之后,分类的test过程就是很简单的矩阵乘法(和加法)。
那么如何理解线性分类器呢?换言之,如何理解由W完成一次matrix multiplication就可以实现分类呢?W又有什么物理意义呢?
i. W的ensemble理解:
10*3072的W可以理解为10个1*3072维的row vector,每个row vector是CIFAR-10 10中类别中一类的打分器。每个row vector对应最终10*1维输出中的一维,即某个1*3072 vector of W 乘以 xi输出一个scalar value,这个实数就是该样本xi属于这个row vector对应类别的classification score。换言之,W * xi的矩阵乘法而不是向量乘法,是一中并行计算的模式,一次性完成10个类别的打分。
那么,W的每个row vector中的3072个数字又各自有什么意义呢?当将row vector与xi(3072 * 1)这个flattened image vector进行dot-product时,是对位相乘再相加:其中k = (1,2,。。。,10),i属于(1,50000),j属于(1,3072)。第k个row vector Wk的3072个数中的每一个对应着input image vector 3072个数字中的每一个。即,输入图像的每一个pixel location的每一个color channel(RGB)上的取值(itensity value)都对应一个专属于它的w,这个w表达出分类器对这个pixel location的这个color channel(RGB)上的取值(itensity value)的“喜欢程度”。当w大于0时,表示分类器喜欢这个pixel location的这个color channel上的取值(一定是正值,所以乘积为正)喜欢,且w越大越喜欢,喜欢的物理意义就是有更大的正的乘积值在最终求sum时会有更大的contribution,得到更高的分类得分。反之,w小于0则意味着分类器不喜欢这个pixel上这个颜色有值。3072个小w各司其职监控表达着自己对自己所看护的pixel颜色的态度,通过乘积来表达态度。而最后的求sum,就是3072个小w(pixel-wise classifier)的ensemble,一次voting。
举例来看,假设Wk是对ship这个类别的分类器。那么Wk的3072个数中对应input图片边缘pixel的Blue channel的小w应该有较大的正值,因为ship图片往往会在边沿显示蓝色的水,因此ship W classifier会对这样的图片打出高分。从这个角度讲,虽然讲32*32*3的input图片faltten成3072d的vector,但图像中的spatail info还是能够在vector的sequence信息中得以部分保留。
ii. W的template matching理解:
因为同样是3072维,Wk可以看做是input image vector的一个template。即,3072个中的每一个小w时对其对应pixel位置的对应color channel的一个“模仿”。这其实与第一种理解中“喜欢”的概念异曲同工:即,如果小w喜欢x在这个位置这个颜色的值,那么小w就会给出正值,越喜欢正值越大。而小w的这个正值,既可以理解为是w的权值,也可以直接理解为是tempalte W对应位置对应颜色上的itensity value。这样一来,这个dot-product就从ensemble voting变成了template matching,即用dot-product来衡量input图像xi与ship模板Wk的similarity,这个similarity score就是分类score。

如上图所示是CIFAR-10上10个类别的template(即将Wi∈[3072, 1], i = 1, ...., 10个weight vectorde-flattened回32 * 32 * 3后得到的weight image,maybe rescale by * 255 element-wise)。
(2)NNs、CNN、RNN:
同样是一个mapping,只是用了不同的工具和手段,此处不赘述。
2. Loss Function:
在map到的低维期待输出的空间比较预测输出与Ground truth之间的差别。在本例中就是用linear classifier输出的10dim分类score与该样本GT的10dim one-hot encoding的score进行比对打分。
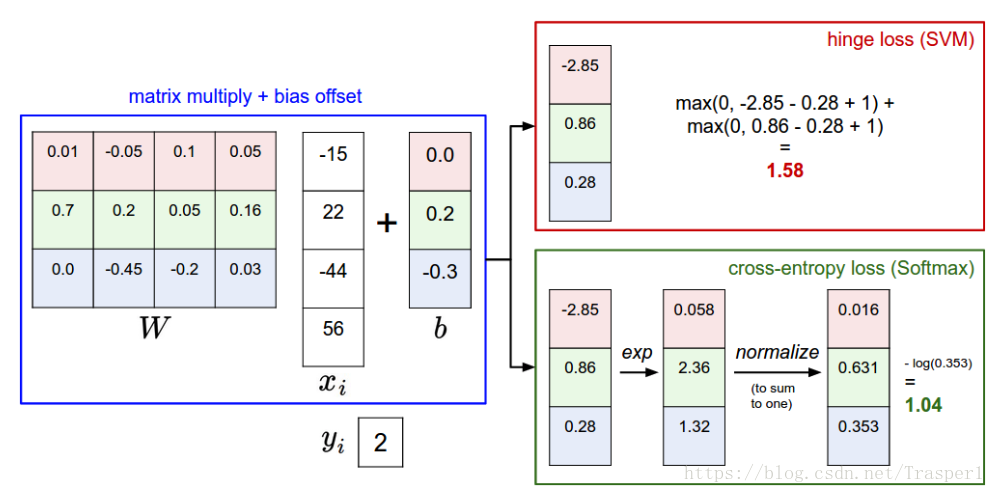
(1)SVM+Hinge Loss:
SVM是最常用的多分类器之一。与传统意义上的矩阵乘法的线性分类器不同,SVM是一个optimal margin classifer,即求得3072dim样本空间中的一组分类hyper-plane(HP,共10个,每个HP是一个3072维的vector来表示,即一个3072维空间中的单位向量、一个基)。接的过程用到了拉格朗日算子转化拉格朗日型,再求其dual problem。最终求得的3072dim HP其实一个由50000个样本中极少量个support vector(与HP最近的、functional margin = 1的样本点)的线性组合。(,i是所有的样本 = 50000,α是拉格朗日算子,只有当xi是SV时,α不等于0)。所以,在SVM测试时,就是把输入的新的3072dim的iamge vector与HP做vector multiplication
, 即test sample与SV两两计算dot-product。这个计算內积的步骤可以用kernel来代替。任意一个对称的、自相关矩阵半正定的函数都可以是kernel fucntion。每个kernel function implicitly将3072dim的样本空间映射到一个更高维的RKHS再生核希尔伯特空间中去,这个转换可能是非线性的,但是某些低维空间中不可分的问题,在高维空间中可分。
Hinge loss是一个中marginal loss,大概理解就是对于ship这一类,将样本的所有非ship类的socre与ship score求距离,如果距离大于margin(pre-defined,常常=1),那么max()operation就会取0;如果小于margin,max()就会取小于的那部分值。所有非ship类别求和。Hinge loss的特性就是只要某个样本的某个非ship分类足够好,对这一类的区辩力超过了margin的约束(即个非ship类打的分足够低),那么这一类就不产生loss。过关即可,不锱铢必较。
(2) Softmax classfier + Cross-Entropy loss:
Softmax是一个函数的名字,这个函数起的作用和logistic regression中logistic(sigmoid)function一样,都是将score funciton的raw output score squash或者转化成特定范围的值(0/1之间,或者一个add-to-1的prob distribution)(注,binary softamx classifier = logistic regression)。
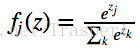
其中zj是对目标类的(j类 = ship)的raw score打分。fj(z)则是softmax函数output的j类的得分。Softmax其实完成了两个操作:1. 将原先的score function raw output(在这里raw output被理解为log probability,所以求exp之后就变成了probability)转化成probability;2. 再将10类的probability normalzied使得10类的socre add-to-1,变成一个10分类的probability distribution。
对raw score output施加softmax操作的目的是使用Cross Entropy Loss。Cross entropy是信息论中的概念,是用来衡量两个probability distribution相似度的指标。显然,每个样本的one-hot encoding GT vector是一个完美的01值得probability distribution(add-to-1),所以要用softmax将raw output classfication scores也转化成一个prob idstribution。
Cross-entropy: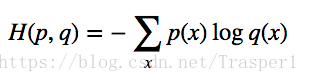

(3)SVM & Softmax classifier:
3. Optimization:GD+BP
BP(chain rule复合函数求导)是计算score function中从后到前所有wi关于loss function的偏导的方法。计算所得的所有wi关于loss的偏导组成的vector就是此次GD update的下降方向(加负号)。
在计算得到loss之后,下一步就是通过不断iteratively地微调W使得loss越来越低。训练(学习)就是在学习一组使得loss最小的最优W。loss function可以看做是定义在30720维(W参数量 = 10 * 3072)parameter空间上的函数(每一组W是这个高维空间上的一个点),w是自变量,x是fixed的定量(在执行每次BP时,x的值fix在本次FP时的值)。所以优化就是在30720高维parameter空间中找到loss function这个曲面上的最低点(linear score function的loss 函数在W空间的曲面是bowl-like,因为loss是convex;NN则是非convex,loss的曲面是多峰多谷的)。
选择的优化算法是gradient descent(当然,convex loss function的优化可以选择现成的优化器)。GD的核心思想是iteratively tiny update and tweak,每次update选择W在当前位置朝着负梯度方向微调。根据update的频次和梯度计算用到的样本数目不同,GD又分为GD、SGD、mini-batch GD。
在运行GD算法时,计算score fucntion在当前状态下的全部W的偏导vector是核心,因为这个偏导的vector就是梯度下降的方向(加负号)。计算W(海量chained up参数)vector的方法是Back-propagation,即计算score function从后到前所有wi相对于最后loss fucntion的偏导。
整个score function(Neural Network)可以看做是多个模块化的gate(比如Add、Multiply、Max等gate)相chain所得。BP的过程中可以以每个gate为单元进行由后向前的gradient的加工和继续向网络前端传。