Joint Patch and Multi-label Learning forFacial Action Unit Detection
这篇文章是讲脸部动作(action units,AU)微妙,有很多意思可以解读出来。现有方法使用one-vs-all的分类方法,不能探索AU间的依赖关系。这篇文章提出的方法是多区块和多标注学习joint-patch andmulti-label learning。
PL和ML
区块学习patch learning PL是探究特征间局部依赖关系;多标注学习multi-label ML是探寻所有动作单元的强相关关系。
多数方法都是提取整张脸的特征,然后将它们组合起来。这篇是定义了一个个脸部landmark为中心的局部patches。将区块分开,就可以给它们赋予不同的权重。Multi-label就根据AUs的关系来分析特征。就最终逐渐的学习到具有区分性的特征patches,然后训练得到一个分类器。

Patchlearning
对于分块,有的将整张脸分成统一的块;有人找表情对(高兴悲伤)中的相同和特有的区块。这两种方式没有体现出区域的重要性。还有对预先定义区域的AUs进行编码。这些方法既需要严格的校准又难以得知这些AUs间的关系。
本文的PL

这篇文章使用landmark patches的方法,得到可自适应的区块。对于得到的区域,定义了一个group-wise的稀疏矩阵,其用来将变量分组。然后再确定每一组的重要性,对每一组group单独测试,然后赋予权重。
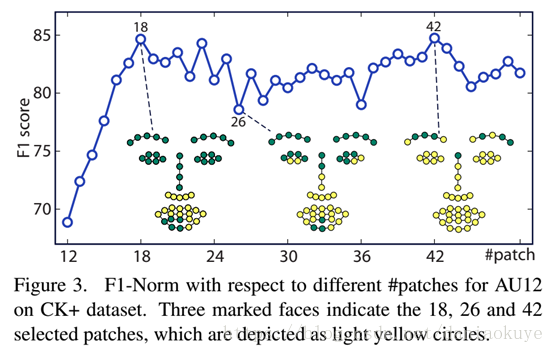
区块的数量和解析表情的表现
区块按照区块的重要性以降序排列,然后查看它们解析信息的表现能力。使用18个landmark对应的区块时,就能达到最佳效果。至于到26有些降低,作者认为是眼部的特征和上嘴唇鼻下区域是相关的,但没有有用的信息,所以轻微的下降。这就是说明了,对于一个表情来说一小组特征就足够找到这个表情特殊的地方之处了。
ML学习multi-label
是为了发现AUs同时出现的概率,亦即关系。使用协方差矩阵,任两个AU使用ground truth计算相关系数。