从AlexNet开始(一)
不可否认,深度学习的热潮正是由2012年AlexNet的出现而引发的,因此,学习AlexNet网络的结构,对于CNN的学习与理解是不可或缺的。在本篇博客中,将会对AlexNet的论文进行翻译与解读,并在下一篇博客中试图使用ALexNet的网络构建思想去建立一个简单的CNN模型用来对CIFAR-10数据集进行分类。
AlexNet论文题目:
ImageNet Classification with Deep Convolution Neural Networks
Prologue 序言
在序言的第一句,Alex就是一句长长的吐槽,吐槽Yann LeCun大佬的论文被CV的顶会拒收了仅仅因为Yann LeCun使用了神经网络。事实上,在那个时代,神经网络是一种被研究机器学习的大佬们所看不起的算法模型,那时人们认为计算机视觉系统需要充分理解任务的类型并由人对系统进行细致地调整,而仅仅简单地输入大量图片与标签,利用神经网络对数据进行特征归纳与分类的方法是行不通的。
在序言的最后,Alex说出了一句非常经典的话:
For deep neural networks to shine, they needed far more labeled data and hugely more computation.
这句话也正是神经网络和Deep Learning经过数十年的发展终于迎来井喷式发展的原因——互联网带来的海量数据与半导体行业的高速发展。
The Architecture 结构
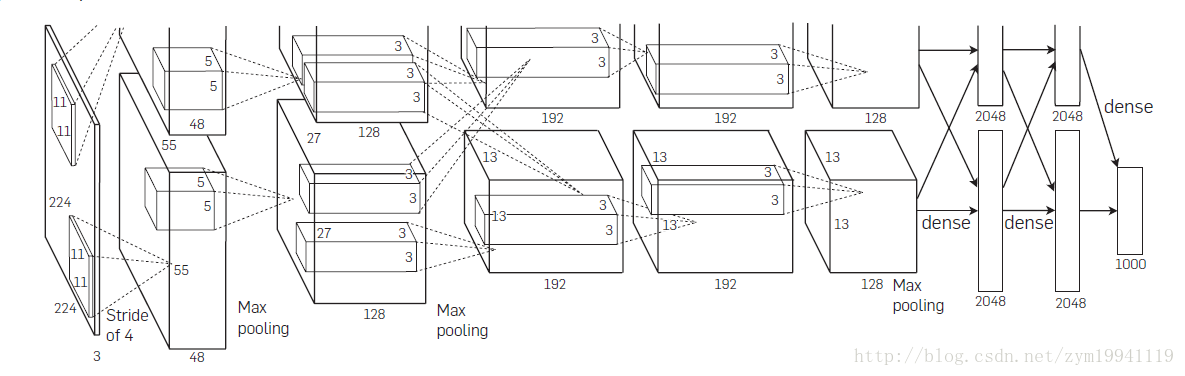
AlexNet的结构如上图所示,共包含了8个学习层——5个卷积层与3个全连接层,相比于之前的LeNet-5网络,AlexNet有以下几个创新的结构:
Rectified Linear Unit nonlinearity
也就是现在被广泛使用的ReLU激活函数,在过去,神经网络的激活函数通常是sigmoid或者tanh函数,这两种函数最大的缺点就是其饱和性,当输入的x过大或过小时,函数的输出会非常接近+1与-1,在这里斜率会非常小,那么在训练时引用梯度下降时,其饱和性会使梯度非常小,严重降低了网络的训练速度。
而ReLU的函数表达式为max(0, x),当x>0时输出为x,斜率恒为1,在实际使用时,神经网络的收敛速度要快过传统的激活函数数十倍。
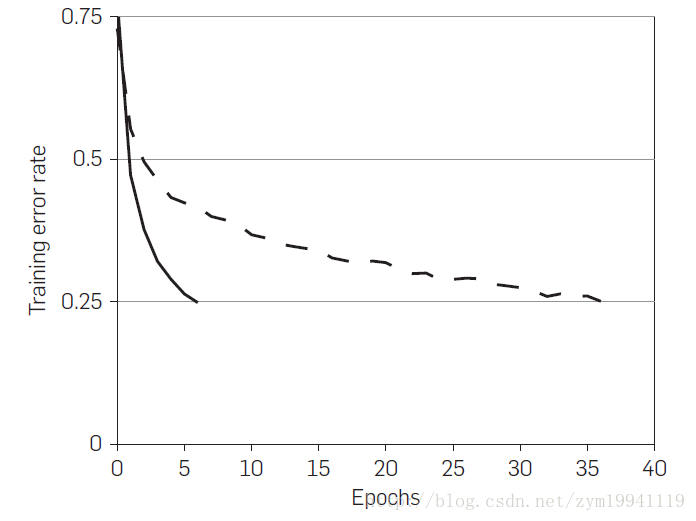
对于一个四层的神经网络,利用CIFAR-10数据集进行训练,使用ReLU函数达到25%错误率需要的迭代数是tanh函数所需迭代数的六分之一。而对于大型的数据集,使用更深的神经网络,ReLU对训练的加速更为明显。
Training on multiple GPUs
不多说,利用多个GPU进行分布式计算
Local response normalization
在使用饱和型的激活函数时,通常需要对输入进行归一化处理,以利用激活函数在0附近的线性特性与非线性特性,并避免饱和,但对于ReLU函数,不需要输入归一化。然而,Alex等人发现通过LRN这种归一化方式可以帮助提高网络的泛化性能。LRN的公式如下:
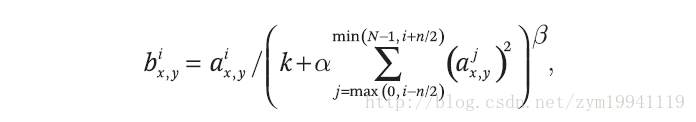
LRN的作用就是,对位置(x, y)处的像素计算其与几个相邻的kernel maps的像素值的和,并除以这个和来归一化。kernel maps的顺序可以是任意的,在训练开始前确定顺序即可。其中的k, N, α, β都是超参数,论文中给出了所用的值为k=2, N=5, α=10e-4, β=0.75。在AlexNet中,LRN层位于ReLU之后。在论文中,Alex指出应用LRN后top-1与top-5错误率分别提升了1.4%与1.2%。
Hinton等人认为LRN层模仿生物神经系统的侧抑制机制,对局部神经元的活动创建竞争机制,使得响应比较大的值相对更大,提高模型泛化能力。但是,后来的论文比如Very Deep Convolution Networks for Large-Scale Image Recognition(也就是提出VGG网络的文章)中证明,LRN对CNN并没有什么作用,反而增加了计算复杂度,因此,这一技术也不再使用了。
Overlapping pooling
池化层是CNN中非常重要的一层,可以起到提取主要特征,减少特征图尺寸的作用,对加速CNN计算非常重要,然而通常池化的大小与步进被设置为相同的大小,当池化的大小大于步进时,就成为了overlapping pooling,这也是AlexNet中使用的池化技术。论文中提到,使用这种池化可以一定程度上减小过拟合现象。
Overall architecture
这部分讲了AlexNet的整体结构,如前图所示。全连接的最后一层是softmax层,共有1000个输出。计算的过程分成两部分是因为这两部分是在两块GTX580上计算的。
ReLU在每个卷积层和全连接层后。LRN层在第一个和第二个卷积层之后。Max-pooling层在两个LRN层与第四个卷积层之后。
卷积的维度不再赘述,看图就好。
Reducing Overfitting 减少过拟合
AlexNet中有六千万个参数,也非常容易产生过拟合现象,而AlexNet中采用了两种方式来对抗过拟合。
Data augmentation
对抗过拟合最简单有效的办法就是扩大训练集的大小,AlexNet中使用了两种增加训练集大小的方式。
- Image translations and horizontal reflections. 对原始的256x256大小的图片随机裁剪为224x224大小,并进行随机翻转,这两种操作相当于把训练集扩大了32x32x2=2048倍。在测试时,AlexNet把输入图片与其水平翻转在四个角处与正中心共五个地方各裁剪下224x224大小的子图,即共裁剪出10个子图,均送入AlexNet中,并把10个softmax输出求平均。如果没有这些操作,AlexNet将出现严重的过拟合,使网络的深度不能达到这么深。
- Altering the intensities of the RGB channels. AlexNet对RGB通道使用了PCA(主成分分析),对每个训练图片的每个像素,提取出RGB三个通道的特征向量与特征值,对每个特征值乘以一个α,α是一个均值0.1方差服从高斯分布的随机变量。
Dropout
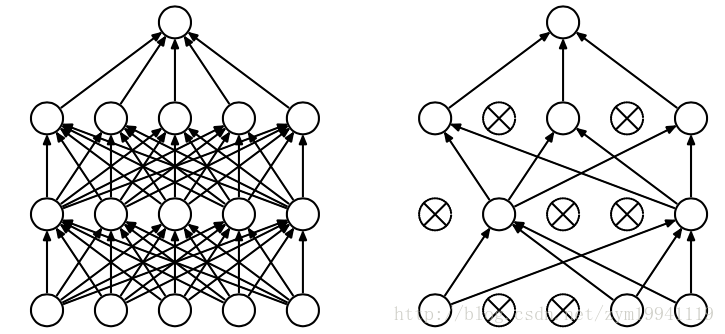
Dropout是神经网络中一种非常有效的减少过拟合的方法,对每个神经元设置一个keep_prob用来表示这个神经元被保留的概率,如果神经元没被保留,换句话说这个神经元被“dropout”了,那么这个神经元的输出将被设置为0,在残差反向传播时,传播到该神经元的值也为0,因此可以认为神经网络中不存在这个神经元;而在下次迭代中,所有神经元将会根据keep_prob被重新随机dropout。相当于每次迭代,神经网络的拓扑结构都会有所不同,这就会迫使神经网络不会过度依赖某几个神经元或者说某些特征,因此,神经元会被迫去学习更具有鲁棒性的特征。如下图所示:
在AlexNet中,在训练时,每层的keep_prob被设置为0.5,而在测试时,所有的keep_prob都为1.0,也即关闭dropout,并把所有神经元的输出均乘以0.5,保证训练时和测试时输出的均值接近。当然,dropout只用于全连接层。
没有dropout,AlexNet网络将会遭遇严重的过拟合,加入dropout后,网络的收敛速度慢了接近一倍。
Details of Learning 学习中的细节
AlexNet使用了mini-batch SGD,batch的大小为128,梯度下降的算法选择了momentum,参数为0.9,加入了L2正则化,或者说权重衰减,参数为0.0005。论文中提到,这么小的权重衰减参数几乎可以说没有正则化效果,但对模型的学习非常重要。
每一层权重均初始化为0均值0.01标准差的高斯分布,在第二层、第四层和第五层卷积的偏置被设置为1.0,而其他层的则为0,目的是为了加速早期学习的速率(因为激活函数是ReLU,1.0的偏置可以让大部分输出为正)。
学习速率初始值为0.01,在训练结束前共减小3次,每次减小都出现在错误率停止减少的时候,每次减小都是把学习速率除以10 。
Alex共在包含120万图片的ImageNet测试集中训练了90个epoch,在2块GTX580 3GB上训练 了5-6天。
End 结束语
这是一篇早就想写一直没写的博客,一是因为元旦出去玩了一周,二是因为刚开始学习tensorflow没多久,调参也没有经验,之前训练的神经网络一直有问题,经历了蛮多磕磕绊绊,比如sess.run()中没有run train_op,导致global_steps一直为0,网络没有训练等等。
接下来的计划是这样:开始训练ResNet,博客的话下一篇将会介绍下最近搞的用来对CIFAR-10分类的小网络,然后会再写一篇VGG的论文理解、一篇ResNet的论文理解,然后就是如何实现ResNet了。慢慢来吧~
转载:https://blog.csdn.net/zym19941119/article/details/78982441