文章列表
1.TensorFlow入门深度学习–01.基础知识. .
2.TensorFlow入门深度学习–02.基础知识. .
3.TensorFlow入门深度学习–03.softmax-regression实现MNIST数据分类. .
4.TensorFlow入门深度学习–04.自编码器(对添加高斯白噪声后的MNIST图像去噪).
5.TensorFlow入门深度学习–05.多层感知器实现MNIST数据分类.
6.TensorFlow入门深度学习–06.可视化工具TensorBoard.
7.TensorFlow入门深度学习–07.卷积神经网络概述.
8.TensorFlow入门深度学习–08.AlexNet(对MNIST数据分类).
9.TensorFlow入门深度学习–09.tf.contrib.slim用法详解.
10.TensorFlow入门深度学习–10.VGGNets16(slim实现).
11.TensorFlow入门深度学习–11.GoogLeNet(Inception V3 slim实现).
…
TensorFlow入门深度学习–08.AlexNet(对MNIST数据分类)
Hinton的学生Alex Krizhevsky于2012年提出了深度卷积神经网络模型AlexNet,它可以算是LeNet的一种更深更宽的版本。AlexNet在CNN中首次成功应用了ReLUctant、Dropout和LRN等Trick,同事AlexNet也使用了GPU进行运算加速。AlexNet包含了6亿3000万个连接,6000万个参数和65万个神经元,拥有5个卷积层,其中3个卷积层后面连接了最大池化层,最后还有3个全连接层。AlexNet以显著的优势赢得了ILSVRC2012比赛,top5的错误率降低至16.4%,相比第二名26.2%的错误率有巨大的提升。AlexNet可以说是神经网络在低谷期后的第一次发声,确立了深度学习(深度卷积网络)在计算机视觉的统治地位,同时也推动了深度学习在语言识别、自然语言处理、强化学习等领域的扩展。AlexNet相较于Lenet主要的技术创新点如下:
(1).使用ReLU作为激活函数,验证了其效果在较深的神经网络上超过了Sigmoid,解决了Sigmoid在网络较深时的梯度弥散问题。
(2).训练时使用Dropout随机忽略部分神经元,避免模型过拟合。AlexNet中在最后几个全连接层中使用了Dropout。
(3).使用重叠的最大池化。最大池化可以避免平均池化的模糊化效果。重叠池化即指池化步长小于池化核的尺寸,这样池化层的输出层之间会有重叠和覆盖,提升了特征的丰富性。
(4).提出LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强模型的泛化能力。
(5).使用CUDA加速深度卷积网络的训练。
(6).数据增强。随机地从256*256的原始图像中截取224*224大小的区域(以及水平weibo used翻转的镜像),相当于增加了(256-224)2=2048倍的数据量。训练数据的增加进一步减轻过拟合现象,提升泛化能力。预测时,提取4个角加中间共5幅图像并左右镜像共10张图,对预测结果取均值。此外,AlexNet中还对对象的RGB数据进行PCA处理,并对主成分做了一个标准差为0.1的高斯扰动,增加了一些噪声,这个Trick可以让错误率在下降1%。
AlexNet有5个卷积层、3个池化层、2个LRN层以及3个全连接层,2个LRN层分别出现在第1个及第2个卷积层后,而最大池化层出现在两个LRN层及最后一个卷积层后,由于AlexNet提出时用了两个GPU,隐藏下图所示的AlexNet网络结构中分成了两部分,现在GPU性能提升,显存可以放下全部模型参数,因此只考虑一块GPU的情况。
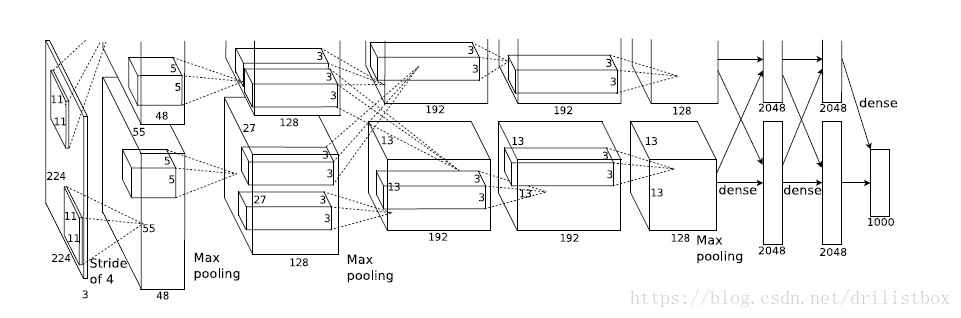
AlexNet每层超参数大小及所需算力如下图所示。

可以发现,前几层(卷积层)的计算量都很大,但其参数数量都很小;而全链接层计算量小(这也有前面卷积和下采样提取高纬特征的贡献),但其参数数量特别大。即卷积层通过较小的参数即可有效的提取各类特征。
Params = (filter_height*filter_width*in_channels + 1) *out_channels
FLOPS:每秒浮点运算次数,每秒峰值速度
FLOPS = out_height* out_width*Params
第1层为输入层,输入图像大小为227*227*3
第2层为卷积层,输入图像大小为227*227*3,卷积核尺寸为11*11*3,步长为4,pad为0,有96个卷积核,第2层的参数及算力大小各是:
Params = (11*11*3+1)*96/1000=35 k
FLOPS = ((227-11+2*0)/4+1)2* Params=102584384=102584384/1000/1000=105M
第2层为LCR层,输出图像大小不变:55*55*96
第3层为下采样层,采样尺寸为3*3,步长为2,第三层的输出图像的大小是:
((55-3)/2+1)2*96=27*27*96
第4层为卷积层,注意AlexNet将第4层分为两部分来计算,那么每个部分输入图像大小为27*27*(96/2),卷积核尺寸为5*5*(96/2),步长为1,pad为2,单个部分有128个卷积核,两个部分就有256,第4层的单个部分参数数量及算力大小各是:
Params = (5*5*96/2+1)*128/1000=153 k
FLOPS = ((27-5+2*2)/1+1)2* Params=112M
第5层为LCR层,单个部分输出图像大小不变:27*27*256
第6层为下采样层,采样尺寸为3*3,步长为2,第三层单个部分的输出图像的大小是:
((27-3)/2+1)2*128=13*13*128
第7层为卷积层,注意AlexNet将第7层分为两部分来计算,并且第7层每个部分的输入来自上面第6层两个部分的下采样的输出,那么每个部分输入图像大小为13*13*(128*2),卷积核尺寸为3*3*128,步长为2,pad为1,有192个卷积核,第7层的单个部分参数数量及算力大小各是:
Params = (3*3*256+1)*192/1000=442 k
FLOPS = ((13-3+2*1)/1+1)2* Params=74M
第8层为卷积层,注意AlexNet将第8层分为两部分来计算,并且第8层每个部分的输入来自上面第7层单独部分的卷积输出,那么每个部分输入图像大小为13*13*192,卷积核尺寸为3*3*192,步长为2,pad为1,有192个卷积核,第8层的单个部分参数数量及算力大小各是:
Params = (3*3*192+1)*192/1000=332k
FLOPS = ((13-3+2*1)/1+1)2* Params=561k
第9层为卷积层,注意AlexNet将第9层分为两部分来计算,并且第9层每个部分的输入来自上面第8层单独部分的卷积输出,那么每个部分输入图像大小为13*13*192,卷积核尺寸为3*3*192,步长为2,pad为1,有128个卷积核,第9层的单个部分参数数量及算力大小各是:
Params = (3*3*192+1)*128/1000=221k
FLOPS = ((13-3+2*1)/1+1)2* Params=374k
第10层为下采样层,采样尺寸为3*3,步长为2,第三层单个部分的输出图像的大小是:
((13-3)/2+1)2*128=6*6*128
第10层为全连接层,输入数据来自上面第9层2个部分的卷积输出,并reshape为一维向量,于是输入向量维度大小为6*6*128*2=9216,第10层全连接层的节点数为4096,权重向量大小为9216*4096,那么第10层的所有参数数量及算力大小各是:
Params = (9216*4096+1)/1000/1000=37M
FLOPS = 1* Params=37M
第11层为全连接层,该层权重向量大小为4096*4096,那么第10层的所有参数数量及算力大小各是:
Params = (9216*4096+1)/1000/1000=16M
FLOPS = 1* Params=16M
第12层为全连接层,该层权重向量大小为4096*1000,那么第10层的所有参数数量及算力大小各是:
Params = (1000*4096+1)/1000/1000=4M
FLOPS = 1* Params=4M
【代码主要来自TensorFlow的开源实现】
首先是引入程序中会用到的系统库
from datetime import datetime
import math
import time
import tensorflow as tf设置batch_size为32,num_batches为100,即总共测试100批小批批数为32的数据。
batch_size=32
num_batches=100定义一个显示每层结构的参数以便将来复用,包括层名以及层中超参数的维数
def print_activations(t):
print(t.op.name, ' ', t.get_shape().as_list())接下来设计AlexNet的网络结构,首先定义AlexNet网络前向计算的函数inference。它接收images作为输入,以最后一个下采样层及超参数为返回值。由于inference函数较大,包含了多个卷积层、下采样层、全连接层等,因此下面将其按层拆开来说明:
首先是第一层,卷积层conv1,引入作用域name_space,通过with tf.name_scope(‘conv1’) as scope:将该scope内生成的Variable自动命名为conv1/xxx,以便于区分不同全集成之间的组件。然后定义该卷积层中具体的卷积核、偏置项、激活函数,采用tf.truncated_normal阶段的正态分布函数(标准差为0.1)初始化卷积核的参数kernel,卷积核尺寸为11*11,颜色通道为3,卷积核个数为64,然后利用tf.nn.conv2d实现输入图像image与卷积核kernel的卷积运算,卷积核在图像维度上的移动步长stride为4*4,卷积方式padding为SAME(即可以填充边界外的点)。将卷积核偏置项biases全置为0,利用tf.nn.bias_add实现卷积输出与偏置项相加获得加权输入,最后采用激活函数tf.nn.relu实现对加权输入的非线性处理,再利用print_activations函数将卷积层名称及参数结构打印出来,并将卷积核及偏置项添加进parameters这个list中。
def inference(images):
parameters = []
# conv1
with tf.name_scope('conv1') as scope:
kernel = tf.Variable(tf.truncated_normal([11, 11, 3, 64], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(images, kernel, [1, 4, 4, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope)
print_activations(conv1)
print_activations(kernel)
parameters += [kernel, biases]第一个卷积层后再添加lrn层对前面卷积层输出conv1进行LRN处理(不过LRN层对模型训练的效果提升并不明显,且会使前馈和反馈的速度大大下降,目前仅有AlexNet使用),然后再用最大池化层对LRN处理后的结果进行最大池化,其中池化尺寸设为3*3,取样步长为2*2,padding模式设为valid,即采样不能超过输入项边界。并将pool层的名称及参数维数打印了出来。
lrn1 = tf.nn.lrn(conv1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='lrn1')
pool1 = tf.nn.max_pool(lrn1,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID')
print_activations(pool1)继续定义卷积层,第2个卷积层conv2,该卷积层与第1个卷积层的定义几乎一致,除了超参数维度设定不一致:卷积核尺寸为5*5,颜色通道为64,卷积核个数为192,卷积核在图像上移动的步长为1*1,卷积方式padding为SAME
with tf.name_scope('conv2') as scope:
kernel = tf.Variable(tf.truncated_normal([5, 5, 64, 192], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[192], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv2)对卷积层输出conv2进行lrn处理,并进行下采样,过程参数设置均匀前面一样
lrn2 = tf.nn.lrn(conv2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='lrn2')
pool2 = tf.nn.max_pool(lrn2,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool2')
print_activations(pool2)然后再引入第3层卷积层conv3,该卷积层与第1个卷积层的定义几乎一致,除了超参数维度设定不一致:卷积核尺寸为3*3,颜色通道为192,卷积核个数为384
with tf.name_scope('conv3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 192, 384],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv3 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv3)第3个卷积层后直接定义第4个卷积层,该卷积层与第1个卷积层的定义几乎一致,除了超参数维度设定不一致:卷积核尺寸为3*3,颜色通道为384,卷积核个数为256
with tf.name_scope('conv4') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 384, 256],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv3, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv4 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv4)第4个卷积层后直接定义第5个卷积层,该卷积层与第1个卷积层的定义几乎一致,除了超参数维度设定不一致:卷积核尺寸为3*3,颜色通道为256,卷积核个数为256
with tf.name_scope('conv5') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 256],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv4, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv5 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv5)第5个卷积层conv5后定义一个最大值池化层,池化尺寸设为3*3,取样步长设为2*2
pool5 = tf.nn.max_pool(conv5,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool5')
print_activations(pool5)TensorFlow实现 :https://pan.baidu.com/s/14A91inmZmSC55dgDv8ZZ3Q