《ImageNet Classification with Deep Convolutional Neural Networks》
1 文章简要介绍
背景:这篇文章是Hinton团队参加ImageNet2012比赛用的网络,这是第一次用深度网络的方法参加ImageNet比赛,效果较之前的方法获得了极大提升。这个网络又被称为Alexnet,在这个网络之后,更多优秀的网络,如VGG,ResNet被提出。而这篇文章由于其经典性,很有学习的必要。
本文的四个主要贡献是:1)在ImageNet上训练并获得了当时最好的结果。2)提出了基于GPU训练的方法,实现了网络的加速。3)针对网络结构大的特点,提出了防止overfitting的方法。4)网络结构包含五层卷积和3层全连接层,而卷积层在网络中很重要,去除卷积层将引起性能的大幅下降。
2 关于ImageNet
ImageNet是一个包含了超过1500万有标记的高分辨率图片,这些图片包含了22000种物体。这些图片从网络上搜集,通过亚马逊众包工具进行人工标注。从2010年开始,一个叫ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)的比赛开始举行。ILSVRC使用了ImageNet的一个子集,包含了1000种物体,120万训练图片,50000验证图片和15万张测试图片。
ILSVRC对结果提出了两个评判标准:Top1错误率和Top5错误率。Top1错误率是指要求分类结果概率最大的是正确答案的错误率,而Top5错误率是指分类概率前五包含正确答案的错误率。
ImageNet包含的图像分辨率各不相同。作者在这里采用下采样方法将图片变为256×256的。
3 网络结构
3.1 ReLU 激活函数
神经网络需要使用非线性激活函数,从而实现神经网络可以拟合高维非线性函数的效果。常用的激活函数是sigmoid函数和tanh函数。本文中采用的是ReLU函数,形式为
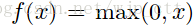
使用ReLU激活函数的优势在于可以加速计算,如图1所示,一个使用ReLU的四层卷积神经网络(实线)在CIFAR-10训练集上达到25%训练错误率的情况下比使用tanh激活函数(虚线)快6倍。
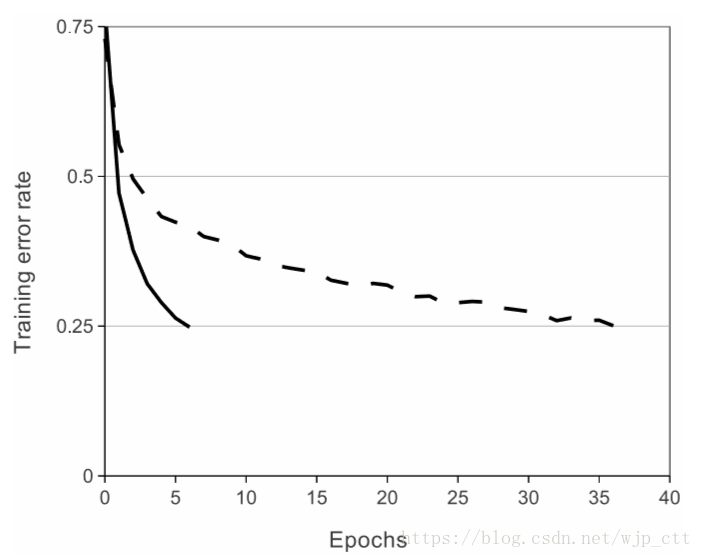
使用ReLU激活函数能提升快速性的原因在于函数无需经过复杂的指数运算。当x小于0时,结果为0;当x大于0时,结果为x本身,运算相当简单。
3.2 使用多GPU进行训练
由于120万训练样本对于GPU过于巨大,因此这里将网络分布在了两台GPU上。每个GPU负责训练网络一半的参数,同时两台GPU在特定的网络层上进行通信。如,第三层神经元以第二层上的所有神经元作为输入,第四层的神经元以第三层的相同GPU上的神经元作为输入。网络的连接方式需要用交叉验证进行研究。
3.3 局部响应归一化
由于ReLU的性质,无需进行输入正则化来防止饱和现象的出现。但使用局部响应归一化仍有助于泛化。局部响应归一化灵感来源于生物学中神经元的侧向抑制的现象。用公式表示为:
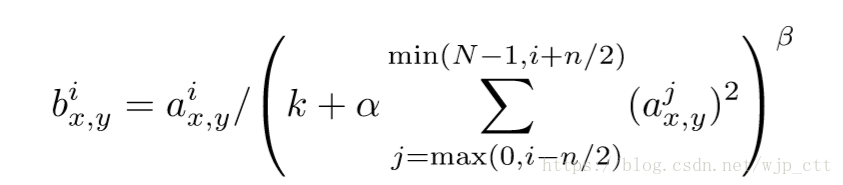
其中,是神经元i在位置归一化后的激活量,
代表了在空间相同位置的相邻神经元的数目,
是该层中所有神经元的数目。
和
是超参数,这里作者选用了
。
3.4 重叠池化
重叠池化是指池的宽度大于池的移动步长,这样池每次移动后都与上一位置有重叠。
3.5 模型基本结构
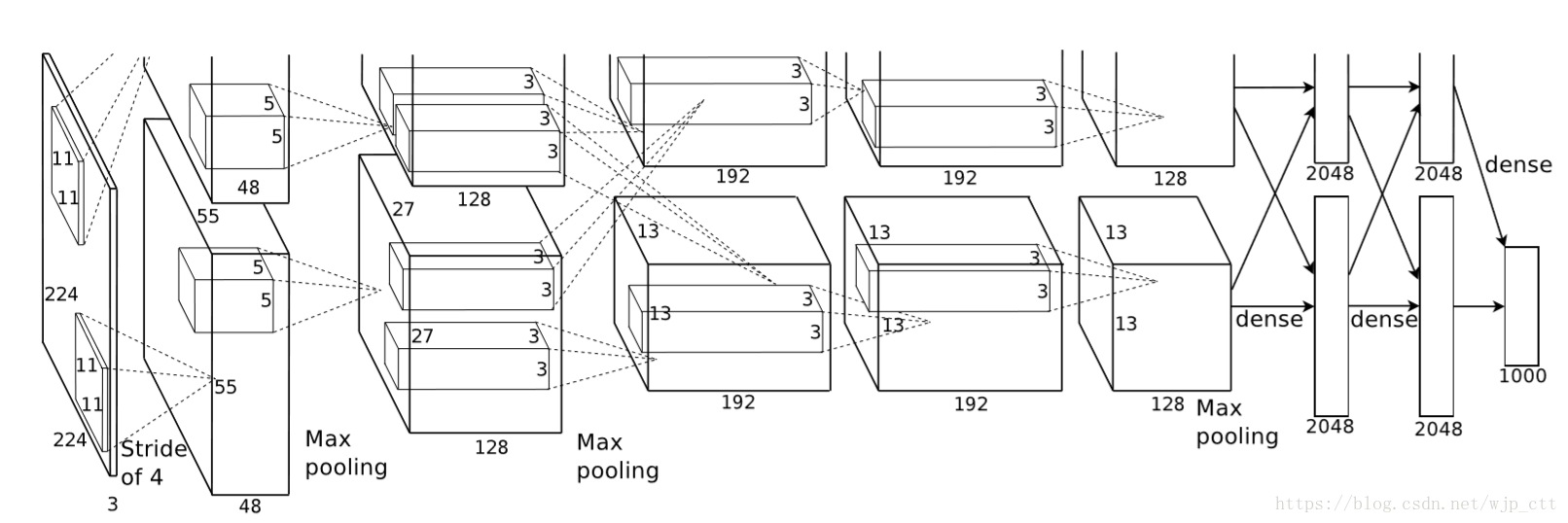
模型前五层是卷积层,后三层是全连接层。最后一个全连接层进入了包含1000个元素的softmax层,产生了在1000类物体上的概率分布。
4 防止过拟合
由于该网络中包含6000万参数,尽管训练集也很巨大,但也需要考虑将模型中引入防止过拟合的方法。
4.1 方法一:数据增强
文中采用了两种方法。第一种方法是从原始图像中截取部分,进行平移和水平翻转等操作,从而产生更多的样本。具体实现方法是从256x256大小的图片中随机采样出224x224的图片。第二种方法是改变训练图像的RGB通道的强度值。首先对ImageNet训练集上图像的RGB值进行PCA分析。然后将每张图像的三通道像素值看成一个三维向量,将这个向量上加一个以随机值乘上特征值为系数的特征向量。原像素值为,加上的值为
4.2 方法二:Dropout。
通过结合不同模型的预测结果是一种减小测试错误率的有效方法。受该想法启发,文中采用了一种叫dropout的技术,即每个隐含神经元的输出有0.5的概率为0。所以每次训练时模型拥有不同的结构,这些结构共享权重。在测试时,我们使用所有的神经元但将它们的输出乘以0.5。
5. 训练的细节
模型使用随机梯度下降法进行训练,每个batch的大小为128,weight decay(正则项之前的系数)为0.0005。权重的更新规则为:
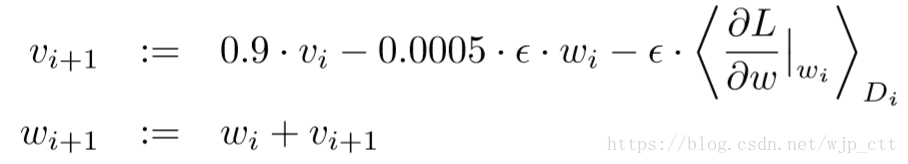
其中,是迭代次数,
是动量参数,
是学习率,
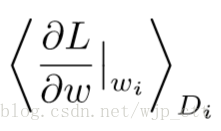
6. 讨论
网络生成的4096维特征向量,表达了物体的的特征。如果两个4096维特征向量相似(相似性可以用欧式距离衡量),则可以认为特征向量所代表的物体相似,这是对物体特征的提取,在像素维度可能两幅图像差异很大。可考虑基于4096维信息使用自编码机以进行图像搜索。
模型的改进:1)可考虑使用非监督预训练方法提升性能;2)从仿生角度出发,模仿人的颞下通路(3)用深度网络处理视频序列,由视频序列提供静态图像丢失的信息。