
首先明确是分类而不是回归
逻辑回归的名字中虽然带有回归两个字,不过这是一个并不是一个回归算法,而是一个分类算法,他是在线性回归的基础上加入了sigmoid函数,将线性回归的结果输入至sigmoid函数中,并且设定一个阈值,如果大于阈值为1,小于阈值为0
sigmoid 函数:
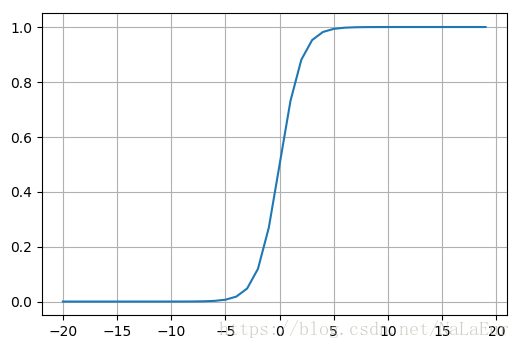
在图中我们可以看到 x -> -∞ 时 y 趋向与0,反之趋向于 1
def sigmoid (x):
return (1 / (1 + np.exp (-x)))逻辑回归的推导过程
准备公式:
sigmoid函数 :
预测函数 :
用概率的形式表示时间是否发生:
在样本 x 的条件下 y = 1 的概率 :
在样本 x 的条件下 y = 0 的概率 :
上面两个公式合并:
通过最大似然函数求损失函数
这里在x 和 y 上的上标标忘了打了,用来表示第i个数据
损失函数 :
在这里我们发现损失函数是一个恒正的函数,所以我们使用梯度上升算法,这个和梯度下降算法并没有什么区别
梯度上升迭代函数 : 
偏导函数,为了推导方便,暂时省略求和计算
偏导公式进行链式分解:
上面三式综上:
综上可以得
程序实现:
def gradAscent(dataMatIn, classLabels):
dataMatrix = np.mat(dataMatIn) #转换成numpy的mat
labelMat = np.mat(classLabels).transpose() #转换成numpy的mat,并进行转置
m, n = np.shape(dataMatrix) #返回dataMatrix的大小。m为行数,n为列数。
alpha = 0.001 #移动步长,也就是学习速率,控制更新的幅度。
maxCycles = 500 #最大迭代次数
weights = np.ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights) #梯度上升矢量化公式
error = labelMat - h
weights = weights + alpha * dataMatrix.transpose() * error
return weights.getA() #将矩阵转换为数组,返回权重数组