论文地址:2108.08121.pdf (arxiv.org)![]() https://arxiv.org/pdf/2108.08121.pdf
https://arxiv.org/pdf/2108.08121.pdf
主要贡献
- 论文为VidSGG提出了一种新的检测到跟踪范式,称为目标自适应上下文聚合网络(TRACE)。这个新的透视图将用于关系预测的上下文建模与复杂的低级实体跟踪解耦。
- TRACE作为一种纯帧级的VidSGG框架,在捕获时空上下文信息进行关系识别方面比以往的方法更加模块化,并在Action Genome数据集上获得了最好的性能。
- 在TRACE中,论文提出了一种自适应结构,称为层次关系树(HRTree)。通过使用HRTree,可以在候选对象之间有效地聚合上下文信息。
场景图生成方法
- 视频级场景图:需要根据关系的精确时间边界,提前准确地将长视频修剪成短片段(如30帧)。这个设置不能很容易地适应未裁剪视频中的真实的VidSGG,因为由于时间的模糊,裁剪是困难和主观的。
- 帧级场景图:图在帧级定义,在短片段中,关系会随着时间的变化而变化;更加灵活,可以利用时间关联跟踪相邻结果,很容易地生成视频级的场景图。

网络结构

模型的输入是一个密集采样短剪辑视频及其中心帧,利用一个3D CNN提取视频的时间特征,一个2D CNN提取中心帧表示,以及一个对象检测网络用于对象候选对象及其视觉特征。基于这些低级的可视化表示,TRACE通过HRTree构建、上下文聚合、关系分类和可选的时间关联等模块简化了VidSGG管道。
首先,在中心帧中检测对象。使用二维CNN提取中心帧的空间特征,使用三维CNN提取剪辑中的时间特征。此外,将静态对象特征与词嵌入相结合,用于后续块。其次,构建了层次关系树(HRTree),以紧凑高效的方式组织可视化关系候选;接着,我们在HRTree的帮助下以相对低的内存成本进行目标自适应上下文特征聚合。具体来说,论文设计了一个用于融合时间特征的时间注意模块。然后,一个定向空间聚合模块负责传播上下文信息。最后,使用一个分类模块来推断每个候选关系的关系类。
HRTree的构造
关系候选组织的层次关系树(HRTree)是以一种分层的自底向上的方式构建的。HRTree中的叶节点表示在中心框架中检测到的对象。非叶节点是从它们的子节点派生出来的,并表示它们的复合关系。具体来说,HRTree是基于空间接近性的渐进方式构建的。给定一层节点的空间坐标,使用高斯核函数计算每个节点的成对相似度之和:
其中 编码节点
的相对位置信息,
表示空间坐标。在得到一层节点的得分后,根据得分对节点进行排序,并选择其中的一部分作为中心。然后,其他节点被合并到最接近它们的中心,通过它们的空间联合来测量。因此,更新后的中心形成当前层的父层,这个过程会重复,直到剩下一个节点。欧几里得距离是用来衡量距离的。
对于每一层中心的选择,如下图所示,有两种实现方案:
- 从最高分到最低分,每隔一个节点选择一个节点作为中心。
- 我们将节点的数量固定为其子节点总数的一半。然后,我们从得分最高的部分中选取一半的节点,从得分最低的部分中选取其余的节点作为中心。

在示例中,可视关系候选的数量是O(n),这意味着与之前的全连通图相比,关系候选的数量大大减少,从而为上下文聚合节省了更多的计算和内存开销。
目标自适应上下文聚合
时间融合模块
- 对于每个非叶节点,即关系候选节点,我们从3D CNN特征图中提取与该关系候选节点对应的特征表示。
- 它的实现方式是先将候选边界框沿时间不断拉伸,形成一个管。然后,我们利用标准RoI Align操作,在每个时间点与管中对应的盒子提取一个特征。生成的跨时间特征用于当前候选关系的时间信息聚合,论文提出了两种融合时间信息的方法。
- (1)如下图所示,以空间特征作为查询,将多头注意力机制应用于这些时间特征。它本质上是3D特征的加权和,权重是基于2D特征自适应学习的。

- (2)如下图所示,对3D骨干输出进行时间差分操作提取运动特征,并采用简单的平均池化操作进行时间融合。

空间传播模块
空间传播模块本质上是基于HRTree的空间上下文聚合机制。具体来说,其采用了一种group tree-GRU方案进行双向传播的上下文聚合:
HRTree中节点的特征在特征维度上被划分为多个组。然后,将每组中的特征输入到独立的tree-GRU中。在每个tree-GRU中,首先执行自底向上的特征聚合。然后进行自顶向下的特征细化,相当于一个普通的GRU。随后,应用多层感知器(MLP)对特征进行拼接,得到上下文化特征。
论文实验观察到该空间传播模块可以有效地聚合空间上下文信息进行关系识别。
分类头模块
如下图所示,分类头负责关系推断。它由四个分支组成,每个分支提供一个结果。分类的最终分数是它们的和。
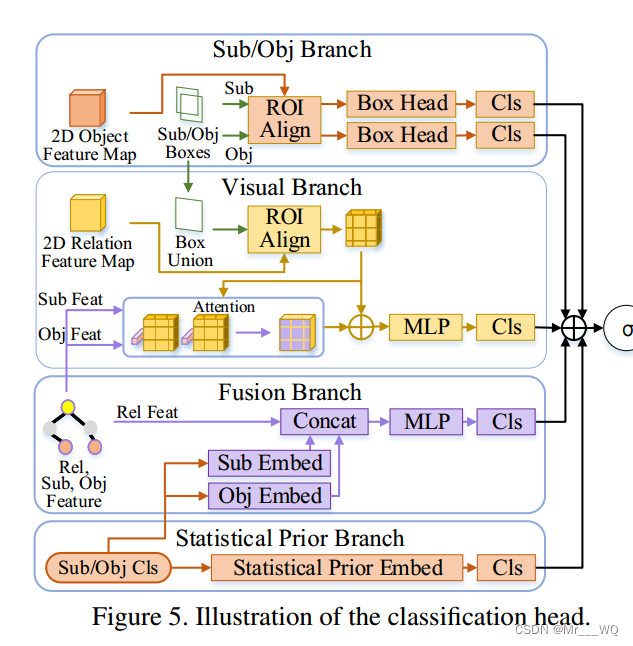
视觉分支
通过将ROI Align应用于二维CNN骨干输出,并结合成对对象建议,生成关系特征图。在得到各个关系特征图后,主体和客体的特征向量对其降维版本执行注意力机制。
具体来说,首先由特征图与每个像素上的特征向量的余弦相似度生成得分图,然后由特征图与后softmax得分图之间的元素积导出注意力图,使用注意力图和特征图进行分类。
融合分支
论文首先将主题和对象分类分数输入到词嵌入块中。然后,将嵌入的特征向量与来自分类器的空间传播模块的上下文化关系特征连接起来。主客体的级联向量对应的上下文化关系特征属于它们在HRTree中的最小公共祖先。
主/客体分支
采用和论文《Graphical Contrastive Losses for Scene Graph Parsing》相同的主体客体结构。
统计优先分支
用主体客体分类统计作为输入。
时间链接模块
将帧级场景图融合到视频级结果的时间链接策略,具体如下图所示:

- 首先将长视频片段划分为重叠的视频片段(如每段30帧,每段15帧),然后对每段进行跟踪。从跟踪中获得的目标轨迹用于这种链接。
- 对于一个视频片段,使用帧级场景图对四分之一的帧进行采样以进行链接。如果一个三元组只出现在一个帧中,则直接用它的预测得分来计数。对于在多个框架中具有相同预测类别的三元组,如果他们的主体和对象分别属于相同的轨迹,则对三元组进行一次计算,并将其得分相加。
- 就整个视频而言,两个相邻片段之间的三元组只有在它们的预测类别相同且它们的主体/客体轨迹的vIoU超过0.5的阈值时才有关联。视频级别的分数可以是平均或最高。作为一个贪心的方式,在组合过程中的得分高的三元组优先于其他三元组。
实验
数据集
- ImageNet-VidVRD (VidVRD):为每个帧标记时空注释标签。经过转换后,每帧中关系和对象的平均数量分别为9.7和2.5,每个对象对中的关系数量平均约为2.0。
- Action Genome (AG):预处理后,每帧的关系数和对象数平均分别为7.3和3.2,每个对象对中的关系数量平均为3.3个。此外,AG中主体边界框与客体边界框重叠的三元组数超过85%。
评估指标
- ImageNet-VidVRD (VidVRD):使用关系检测的Recall和mAP来评估模型。并考虑关系标记。此外,对每对对象保持前20个预测关系以供评估。将预测框视为命中的阈值设置为0.5。
- Action Genome (AG):采用三种模式来评价AG:场景图检测(SGDet)、场景图分类(SGCls)和谓词分类(PredCls)。传统评估指标是
,但由于关系分布的不平衡,还引入了
、
和
,由于存在多重关系,限制每一对对象只能预测一个三元组的图约束在这里并不适用。此外,为了避免预测随机击中真实三元组的情况,每对对象只允许对应的k个预测,并且k设置为6或7。
损失函数
采用关系的二元交叉熵和对象的交叉熵的加权和,其中关系的权重为1.0,对象的权重为0.5。
训练及测试
- 目标检测器:Faster R-CNN,backbone:ResNet。
- 利用2D ResNet50提取中心帧上的关系特征,利用I3D ResNet50预处理Kinetics数据集,提取时间信息。
- 训练TRACE时,冻结主干中用于对象特征提取的所有层。
- 目标检测后保留前100个目标建议,每帧使用IoU为0.5的NMS。由于AG中大多数物体都是相互接触的,所以只对SGDet用重叠的包围框预测成对关系。
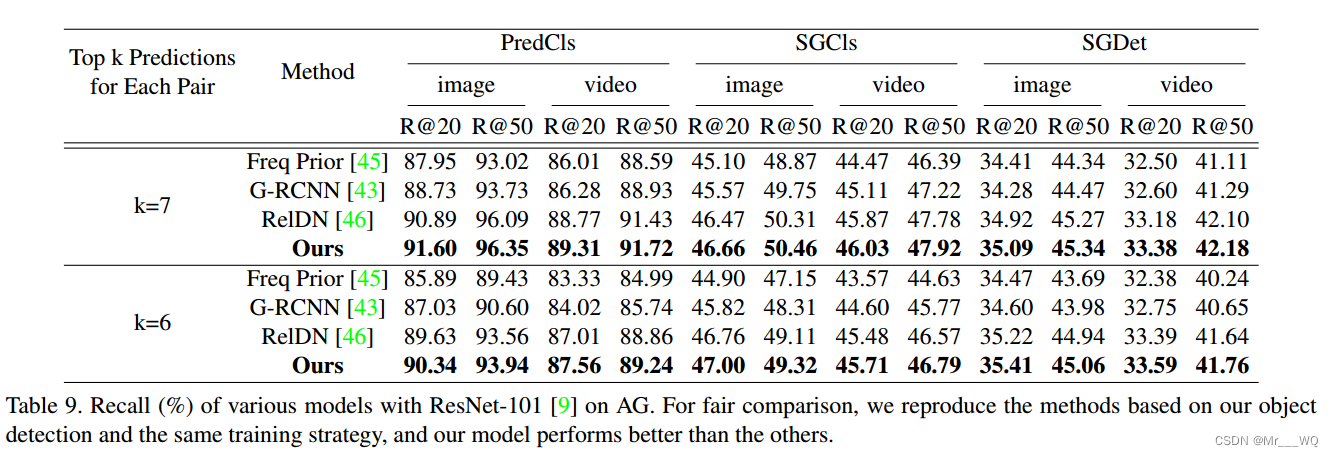
AG数据集性能比较
总结
在本文中,提出了一个用于帧级VidSGG的模块化框架,称为目标自适应上下文聚合网络(TRACE)。为了自适应、高效地获取时空上下文信息,设计了一种新的层次关系树来指导时间注意融合和空间信息传播。该方法与简单的时间关联策略相结合,产生了模块化视频级VidSGG基线,在ImageNet-VidVRD的视频级指标下,无需使用复杂的跟踪功能,即可获得最佳性能。对于纯框架级别的VidSGG任务,TRACE仍然在Action Genome的基准上取得了SOTA。