前言
一、机器学习中分类和预测算法的评估,那么是根据哪些因素来评估一个算法的好坏和优越:
- 准确性
- 速度
- 强壮行
- 可规模性
- 可解释性
决策树-监督学习
决策树是一个类似于流程图的树结构:每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布,树的最顶层是根结点。
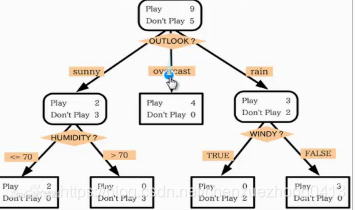
决策树的优缺点
优点:直观,便于理解,小规模数据集有效
缺点:处理连续变量不好,类别较多时,错误增加的比较快,可规模性一般
案例:
import pandas as pd
# 数据读取
iris_data = pd.read_csv('iris.data')
iris_data.columns = ['sepal_length_cm', 'sepal_width_cm', 'petal_length_cm', 'petal_width_cm', 'class']
#
a = iris_data.head()
print(a)
from sklearn.cross_validation import train_test_split
from sklearn.tree import DecisionTreeClassifier
all_inputs = iris_data[['sepal_length_cm', 'sepal_width_cm',
'petal_length_cm', 'petal_width_cm']].values
all_classes = iris_data['class'].values
(training_inputs, testing_inputs, training_classes, testing_classes) = train_test_split(all_inputs, all_classes, train_size=0.75, random_state=1)
#创建模型
decision_tree_classifier = DecisionTreeClassifier()
# 在训练集上训练分类器
decision_tree_classifier.fit(training_inputs, training_classes)
# 使用分类准确性验证测试集上的分类器
decision_tree_classifier.score(testing_inputs, testing_classes)
输出结果:0.97368421052631582
完整代码我这里就不贴了。。。到时我会上传到github! (__) 嘻嘻……
