1、决策树是数据挖掘最常用的一个算法,也是最基本的算法之一,它的概念也非常简单
决策树是通过一系列规则对数据进行分类的过程。它提供一种在什么条件下会得到什么值的类似规则的方法。
2、决策树种类:分类树 | 回归树
分类树对离散变量做决策树。
回归树对连续变量做决策树。
2、决策树的学习过程
(1)特征选择
(2)决策树构成
(3)剪枝
这是大概的一个说法吧
———————————————————————————————————
下面介绍决策树ID3算法
———————————————————————————————————
ID3算法最早是由罗斯昆(J. Ross Quinlan)于1975年在悉尼大学提出的一种分类预测算法,算法的核心是“信息熵”。ID3算法通过计算每个属性的信息增益,认为信息增益高的是好属性,每次划分选取信息增益最高的属性为划分标准,重复这个过程,直至生成一个能完美分类训练样例的决策树。
决策树是对数据进行分类,以此达到预测的目的。该决策树方法先根据训练集数据形成决策树,如果该树不能对所有对象给出正确的分类,那么选择一些例外加入到训练集数据中,重复该过程一直到形成正确的决策集。决策树代表着决策集的树形结构。
决策树由决策结点、分支和叶子组成。决策树中最上面的结点为根结点,每个分支是一个新的决策结点,或者是树的叶子。每个决策结点代表一个问题或决策,通常对应于待分类对象的属性。每一个叶子结点代表一种可能的分类结果。沿决策树从上到下遍历的过程中,在每个结点都会遇到一个测试,对每个结点上问题的不同的测试输出导致不同的分支,最后会到达一个叶子结点,这个过程就是利用决策树进行分类的过程,利用若干个变量来判断所属的类别。
ID3算法信息论的基础:
(1)、首先我们要先明白信息熵,这是概率论中的知识,我们不妨把信息熵理解成某种特定信息的出现概率
若待分类的事物可能划分在N类中,分别是x1,x2,……,xn,每一种取到的概率分别是P1,P2,……,Pn,那么X的熵就定义为:
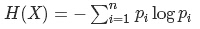
H(X)的值越小(也就是树的结构越简单),则X的纯度越高
(2)、条件熵
假设有随机变量(X,Y),其联合概率分布为:P(X=xi,Y=yi)=pij,i=1,2,⋯,n;j=1,2,⋯,m
则条件熵(H(Y∣X))表示在已知随机变量X的条件下随机变量Y的不确定性,其定义为X在给定条件下Y的条件概率分布的熵对X的数学期望:
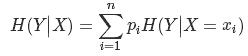
(3)信息增益
信息增益表示得知特征X的信息后,而使得Y的不确定性减少的程度(信息增益越大,代表X的纯度越高)定义为: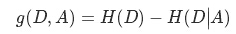
ID3算法对可选取值数目较多的属性有所偏好,为了减少这种偏好可能带来的影响,我们可以用C4.5决策树算法,关于4.5我会在下一章做个总结。
关于伪代码,我直接上西瓜书的图了:

