1.决策树简介
决策树算法是一种分类学习算法

一颗决策树包含一个根节点,若干个内部节点以及若干个叶节点
叶节点对应决策结果;其他节点对应于一个属性测试
从根节点到每个叶子节点路径对应了一个判定测试序列
决策树学习目标:产生一颗泛化能力强,处理未见示例能力强的决策树
算法如下所示:

1.当前结点包含样本属于同一类别时,无需划分
2. 当前节点属性集为空,或所有样本所有属性取值相同,将节点标记为叶节点,类别设定为该节点所含样本最多的类别
3.当前节点包含样本结合为空,标记为叶节点,将类别设定为其父节点所含样本最多的类别
2.划分选择
2.1 信息增益
每个节点有多个属性,选取划分属性,使得系统的信息增益最大。
假定当前样本D中第k类占比为pk,则当前样本的信息熵为:
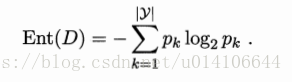
信息熵越小,则集合纯度越高。
属性a的取值有a1,a2..av,其中属性av取值在样本总数中占Dv,则由于属性a划分而引起的集合信息增益为:

则要寻找使得集合信息增益最大的属性划分:

2.2增益率
增益率定义如下:其中IV(a)为属性a的固有值,表示属性a的取值多少。即增益率试图选择属性a取值最少的属性来划分

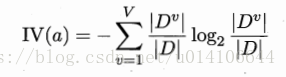
2.3 基尼指数
从D中随机选取两个,不同类的概率,即基尼指数越小,则表示系统纯度越高。
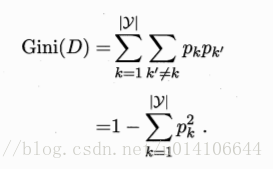
属性a的基尼指数:
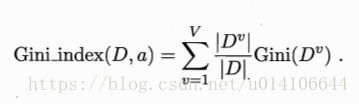
选取使得基尼指数最小的属性作为划分属性:
3.剪枝处理
为了防止过拟合,一般进行剪枝处理:预剪枝与后剪枝
预剪枝:在进行节点划分时,进行估计,如划分能够带来泛化性能提高则进行划分,否则不划分。
降低了过拟合以及训练测试时间,可能带来欠拟合的风险
后剪枝:先生成完整决策树,然后由底向上,考虑非叶子结点,若合并子节点到父节点能够提高泛化性能,则去除该分支,进行合并。
后剪枝欠拟合风险小,但是时间开销大。
以《j机器学习》西瓜数据为例:
西瓜数据样本,训练集与测试集

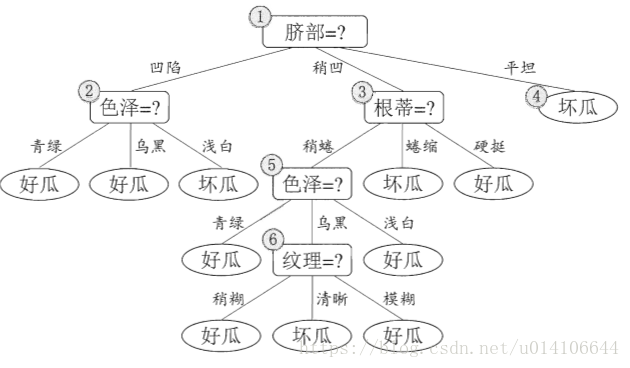
未剪枝决策树:
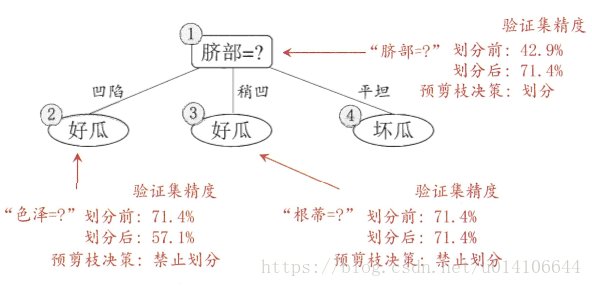
预剪枝决策树:
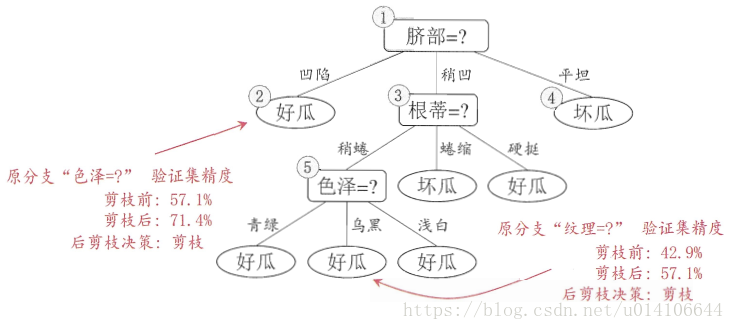
后剪枝决策树:
4.连续属性与缺失值
4.1当属性为连续属性时,属性取值是无限的。
样本集D,连续属性a,属性a在D中出现数值为a1,a2...an升序排列,取候选划分属性集合为:

样本集D基于划分点t划分后的信息增益为,选取使信息增益最大的属性t作为划分属性
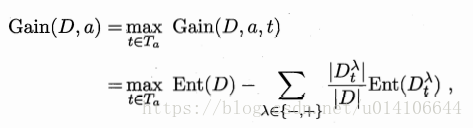
4.2缺失值处理
训练集D 属性a D' 表示D中在属性a上没有缺失的样本子集 属性a的取值为a1, a2...av
Dv' 在D'中属性a上取值为av的样本集合 Dk'表示D'中第k类的样本集合
为每个样本赋值一个初始权重wx

p表示属性a无缺失样本占总样本的比重
pk‘表示无缺失样本中第k类所占比重
rv'表示无缺失样本中属性取值为av的样本所占的比重
信息增益计算如下:
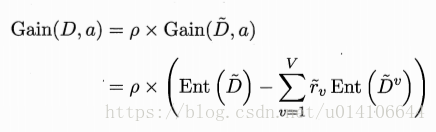

1. 当属性值缺失时,使用属性a未缺失的样子集合计算该属性信息增益
2. 样本x在属性a上取值已知,则直接划分到相应属性取值中去来计算,且样本权值为wx
当样本在属性a上未知时,将样本划分到所有子节点,且样本权值在属性a取值为av的子节点权值调整为rv'*wx,将同一个样本以不同概率划分为不同子节点中。