AI学习一直在继续。
最近研究了机器学习中的经典算法——决策树,决策树主要用于分类,通过对样本的各个属性进行判断,最终对属性做出决策。可以通过各属性,画出最终的决策树。
决策树的生成是一个递归的过程,有以下三种情况:
(1)当前节点包含的样本全属于一个类别,无需划分;
(2)当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;
(3)当前节点包含的样本集合为空,不能划分;
决策树算法中较为基础的为ID3算法,ID3算法主要是通过信息增益对决策树进行划分,下面介绍信息增益的概念。
信息增益(information gain)
信息熵(information entropy)是度量样本集合纯度最常见的一种指标。假定当前样本集合D中第k类样本所占的比例为,则D的信息熵定义为
的值越小,则D的纯度越高。
信息增益则是数据集划分前和划分后信息熵发生的变化,数据划分前信息熵是固定的。
信息增益 = 划分前的信息熵 - 划分后的信息熵
假定离散属性a有V个可能的取值{},若使用a来对样本集D进行划分,则会产生V个分支节点,其中第V个分支节点包含了D中所有在属性a上取值为
的样本,记为
。于是可计算出用属性a对样本集D进行划分所获取的信息增益
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的纯度提升最大,因此,可用信息增益来进行决策树的划分属性选择。
下面以西瓜数据集举例说明决策树的生成。
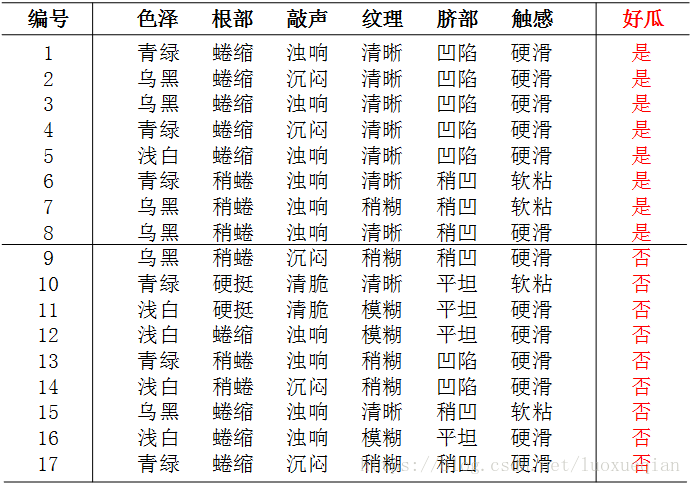
划分前的信息熵为
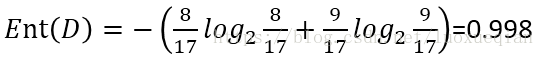
以色泽为例,它有三个取值{青绿、乌黑、浅白},对该属性进行划分,可得到3个子集。D1(色泽=青绿),D2(色泽=乌黑),D3(色泽=浅白)
划分后的信息熵为
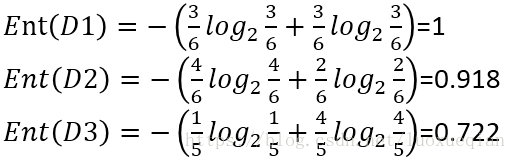
则信息增益为
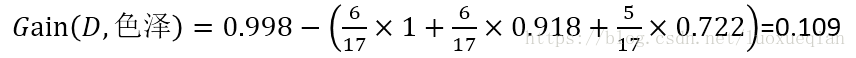

因此选择“纹理”作为根节点
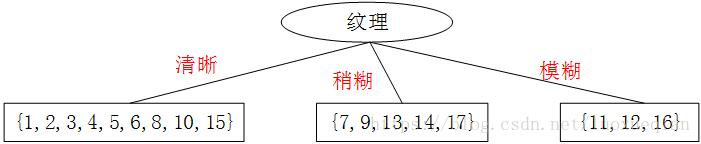
以此类推,当(纹理=清晰)时,分别有属性{色泽、根部、敲声、脐部、触感},来计算左边子树。
以{纹理=清晰}为例,做进一步划分。该结点包含的样本集D为{1,2,3,4,5,6,8,10,15},属性包括{色泽,根部,敲声,脐部,触感}
分别计算出信息增益为:

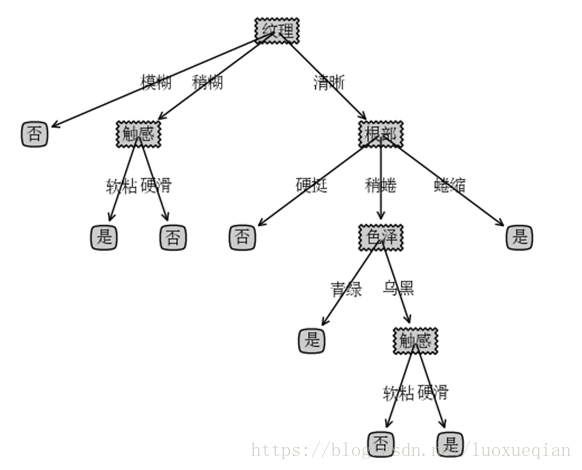
可以看出“色泽”,“脐部”,“触感”3个属性均取得了最大的信息增益,可任意选取其中之一作为属性划分。最终可得到有图的决策树。测试时则根据提供西瓜的上述属性,可判断西瓜的好坏。
最终画出的决策树如下
ID3算法优点:
1)简单直观,生成的决策树很直观。
2)基本不需要预处理,不需要提前归一化,处理缺失值。
局限性:
1)决策树算法非常容易过拟合,导致泛化能力不强。
2)决策树会因为样本发生一点点的改动,就会导致树结构的剧烈改变。