1. 原理简介
1.1 因素集与评价集
- 因素集(又称“评价指标”,是我们要选取的评价对象)
上式中U称为因素集,里面含有m个待评价的对象。
例:当评价花店中某一品种的花时
U={花色,花香,样式,价格}
- 评价集(是我们给待评价对象设置的评级等级)(一般划分为3~5个等级)
上式中V称为评价集,里面含有n个评价等级。
例:当评价花店中某一品种的花时
V={很受欢迎,欢迎,一般,不受欢迎}
1.2 评价指标权重向量
概念介绍
上式中A为权重向量,里面每一个元素代表每一个待评价的指标占待评价对象的权重。
例:当评价花店中某一品种的花时
A={0.4,0.4,0.1,0.1}
表示:
花色在评价这中花的权重为0.4
花香在评价这中花的权重为0.4
样式在评价这中花的权重为0.1
价格在评价这中花的权重为0.1
确定方法(2种)
- 主观:层次分析法
- 客观:变异系数法
【主要讲解变异系数法】
上式中vi属于变异系数(可以理解为权重);si为每一个指标的标准差;xi为每一个指标的均值
1.3 模糊综合评价矩阵
概念介绍
上式中rij表示ui对vj的隶属度。
确定方法(2种)
- 相对偏差法
- 相对优属度法
【主要讲解相对偏差法】
(1)建立一个虚拟理想方案u
(2)建立相对偏差模糊矩阵R
(3)确定权重向量wi
(4)偏差加权
(5)F值综合评价
2. 相对偏差法+变异系数法 求解思路
2.1 建立虚拟矩阵
其中
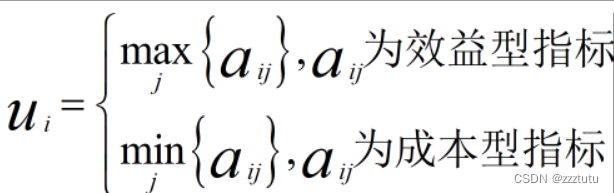
- 效益型指标:越高越好的指标
例如:收益、回报等。
- 成本型指标:越低越好的指标
例如:成本、投资费用,污染度。
2.2 建立相对偏差模糊矩阵
其中
2.3 变异系数法确定权重向量
2.4 对各方案偏差加权
2.5 用F值进行综合评价
若 ,则第i个方案排在第s个方案之前【F值越小,方案优先级越高,方案越好】
3. Matlab代码实现
题目要求是: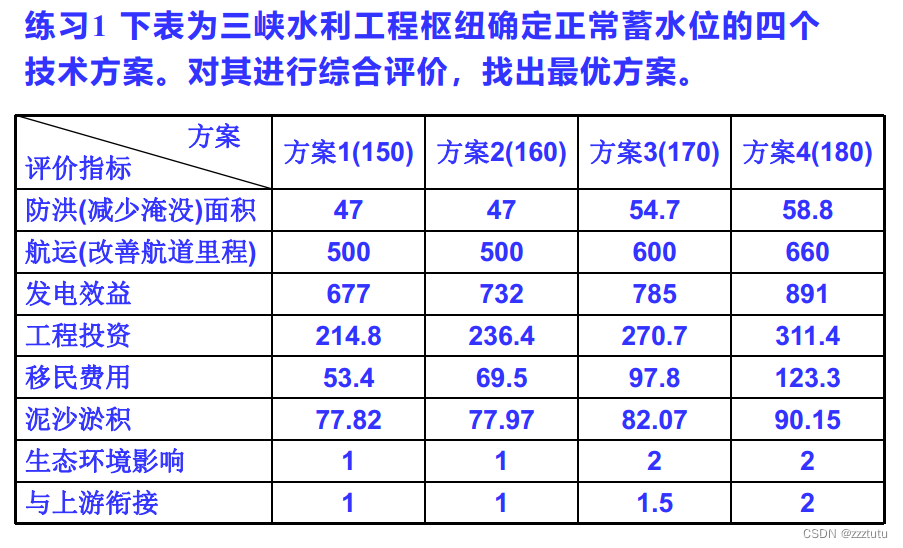
代码实现:
%相对偏差评价法
%获取数据
A = xlsread("D:\Desktop\模糊评价practice.xlsx",1,"B2:E9")
%建立虚拟理想方案[注意行列代表什么,最大最小值取行还是列]【效益型取最大,成本型取最小】
[m,n]=size(A);%找出多少行多少列
maxA = max(A,[],2);%找出几种方案的最大值
minA = min(A,[],2);%找出几种方案的最小值
G = maxA-minA;%最大值减去最小值
A1=max(A(1:3 , :),[],2);%第一行-第三行为效益型(越大越好)
A2=min(A(4:7 , :),[],2);%第四行-第七行为成本型(越小越好)
A3=max(A(8 , :),[],2);%第八行为效益型
u=[A1',A2',A3'];% u 为理想方案
%建立相对偏差模糊矩阵R
R=zeros(m,n);%将模糊综合矩阵初值设置为0
% 如下是得出模糊综合矩阵
for i=1:m
for j=1:n
R(i,j)=abs(A(i,j)-u(i))/G(j) %注意:u是索引行还是列
end
end
%利用变异系数计算权向量
x=mean(A,2);%注意:一定是计算指标集的统计量
s=std(A,0,2);
v=s ./ x;
v2=sum(v);
c=zeros(1,8);
for i=1:8
c(i)=v(i)/v2;
end
%根据F值进行综合评价(越小越好)
FF=c*R;4. 代码总结
- min,max函数求最值
% max()函数
M = max(A) 返回数组的最大元素。
%如果 A 是向量,则 max(A) 返回 A 的最大值。
%如果 A 为矩阵,则 max(A) 是包含每一列的最大值的行向量。
M = max(A,[],dim)
%返回维度 dim 上的最大元素。例如,如果 A 为矩阵,则 max(A,[],2) 是包含每一行的最大值的列向量。
M = max(A,[],2) %返回每一行的最大值,并用列向量输出
- mean函数求均值
mean(A)%返回每一列的均值
mean(A,2)%返回每一行的均值作为列向量- std函数求标准差
S = std(A) %计算每一列的标准差
S = std(A,0,2) %计算每一行的标准差