原始论文(NIPS 2017):https://papers.nips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
参考代码:https://github.com/jadore801120/attention-is-all-you-need-pytorch
1.Attention
2.1 Scaled Dot-Product Attention
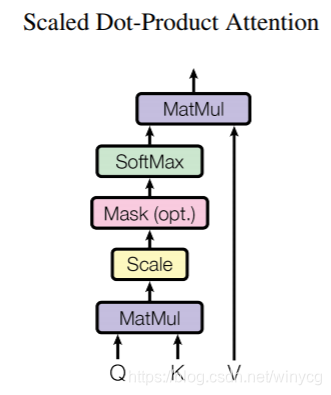
涉及到query,key和value 3个输入向量。设有 q q q个query向量,维度为 d k d_{k} dk,表示为query矩阵 Q ∈ R q × d k Q\in \mathbb{R}^{q\times d_{k}} Q∈Rq×dk。设有 k k k个key向量,维度为 d k d_{k} dk,则对应 k k k个value向量,维度为 d v d_{v} dv,将key向量和value向量包装为矩阵 K ∈ R k × d k K\in \mathbb{R}^{k\times d_{k}} K∈Rk×dk和 V ∈ R k × d v V\in \mathbb{R}^{k\times d_{v}} V∈Rk×dv。
建立每个query与每个key的全连接关系: Q K T ∈ R q × k QK^{T}\in \mathbb{R}^{q\times k} QKT∈Rq×k。防止dot-product造成的数量级过大,除以 d k \sqrt{d_{k}} dk,之后再用softmax对权重行归一化得到 s o f t m a x ( Q K T d k ) ∈ R q × k softmax(\frac{QK^{T}}{\sqrt{d_{k}}})\in \mathbb{R}^{q\times k} softmax(dkQKT)∈Rq×k。利用得到的权重对value向量进行加权平均得到最终的输出:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V ∈ R q × d v Attention(Q,K,V)=softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V\in \mathbb{R}^{q\times d_{v}} Attention(Q,K,V)=softmax(dkQKT)V∈Rq×dv
代码实现如下:
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
# 将mask掉的位置变为一个很小的1e-9值
attn = attn.masked_fill(mask == 0, -1e9)
attn = self.dropout(F.softmax(attn, dim=-1))
output = torch.matmul(attn, v)
return output, attn
2.2 Multi-head Attention
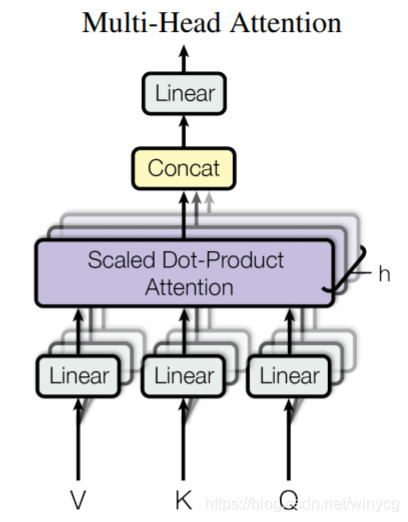
采用了多个attention head来得到输出,最后concat汇总并线性转换。输入是 Q , K , V Q,K,V Q,K,V,一共有 h h h个head,第 i i i个head的输出为:
H e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) ∈ R q × d v Head_{i}=Attention(QW^{Q}_{i},KW^{K}_{i},VW^{V}_{i})\in \mathbb{R}^{q\times d_{v}} Headi=Attention(QWiQ,KWiK,VWiV)∈Rq×dv
W i Q ∈ R d m o d e l × d k , W i K ∈ R d m o d e l × d k , W i V ∈ R d m o d e l × d v W^{Q}_{i}\in \mathbb{R}^{d_{model}\times d_{k}},W^{K}_{i}\in \mathbb{R}^{d_{model}\times d_{k}},W^{V}_{i}\in \mathbb{R}^{d_{model}\times d_{v}} WiQ∈Rdmodel×dk,WiK∈Rdmodel×dk,WiV∈Rdmodel×dv都是线性转换矩阵。在实现中, d m o d e l = d k = d v d_{model}=d_{k}=d_{v} dmodel=dk=dv。将 h h h个head得到的输出进行concat,得到 c o n c a t ( h e a d 1 , . . . , h e a d h ) ∈ R q × h d v concat(head_{1},...,head_{h})\in \mathbb{R}^{q\times hd_{v}} concat(head1,...,headh)∈Rq×hdv。采用一个线性转换矩阵 W O ∈ R h d v × d m o d e l W^{O}\in \mathbb{R}^{hd_{v}\times d_{model}} WO∈Rhdv×dmodel得到输出:
M u l t i H e a d ( Q , K , V ) = c o n c a t ( h e a d 1 , . . . , h e a d h ) W O ∈ R q × d m o d e l MultiHead(Q,K,V)=concat(head_{1},...,head_{h})W^{O}\in \mathbb{R}^{q\times d_{model}} MultiHead(Q,K,V)=concat(head1,...,headh)WO∈Rq×dmodel
代码实现:实现中也包括residual连接和最后的LayerNorm。
class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module '''
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, q, k, v, mask=None):
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
residual = q
# Pass through the pre-attention projection: b x lq x (n*dv)
# Separate different heads: b x lq x n x dv
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# Transpose for attention dot product: b x n x lq x dv
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1) # For head axis broadcasting.
q, attn = self.attention(q, k, v, mask=mask)
# Transpose to move the head dimension back: b x lq x n x dv
# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q))
q += residual
q = self.layer_norm(q)
return q, attn
2. Transformer整体架构
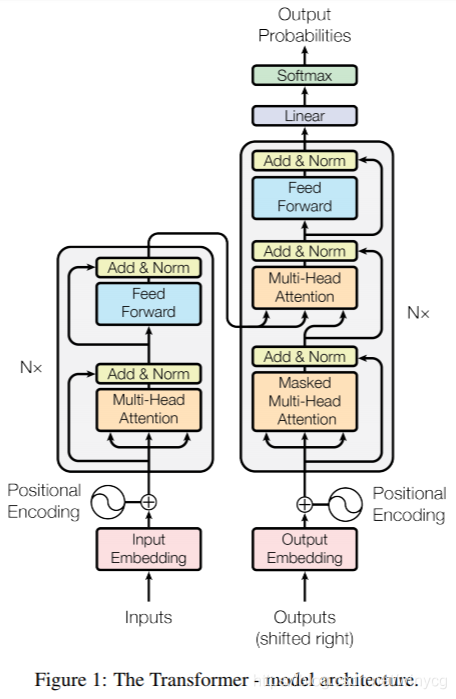
Input Embeddings
输入Input是一个句子有 n n n个单词,每一个单词的对应一个embedding向量,embedding维度为 d m o d e l d_{model} dmodel, 则输入向量的维度为 R n × d m o d e l \mathbb{R}^{n\times d_{model}} Rn×dmodel。
Positional Encoding
对进入的句子中的单词embedding添加位置信息。这里的位置编码对输入的内容是无关的,只与输入tensor的位置有关。采用不同频率的sin和cos函数:
P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
这里 p o s ∈ [ 0 , n − 1 ] pos\in [0,n-1] pos∈[0,n−1], 2 i 2i 2i和 2 i + 1 2i+1 2i+1对应 d m o d e l d_{model} dmodel中的偶数和奇数位置。任何给定的间距 k k k, P E ( p o s + k ) PE_{(pos+k)} PE(pos+k)可以被表示为关于 P E ( p o s ) PE_{(pos)} PE(pos)的线性函数。证明如下:将 1000 0 2 i / d m o d e l 10000^{2i/d_{model}} 100002i/dmodel看作常数。有关系:
s i n ( p o s + k ) = s i n ( p o s ) c o s ( k ) + c o s ( p o s ) s i n ( k ) sin(pos+k)=sin(pos)cos(k)+cos(pos)sin(k) sin(pos+k)=sin(pos)cos(k)+cos(pos)sin(k)
最终得到的位置编码与原始tensor维度一样 P E ∈ R n × d m o d e l PE\in \mathbb{R}^{n\times d_{model}} PE∈Rn×dmodel。两者直接相加作为新的输入tensor。
代码实现如下:
class PositionalEncoding(nn.Module):
def __init__(self, d_hid, n_position=200):
super(PositionalEncoding, self).__init__()
# Not a parameter
self.register_buffer('pos_table', self._get_sinusoid_encoding_table(n_position, d_hid))
def _get_sinusoid_encoding_table(self, n_position, d_hid):
''' Sinusoid position encoding table '''
# TODO: make it with torch instead of numpy
def get_position_angle_vec(position):
return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table).unsqueeze(0)
def forward(self, x):
return x + self.pos_table[:, :x.size(1)].clone().detach()
Encoder
输入首先进入Encoder层,包括了 N = 6 N=6 N=6个相同的层。每一个层包括2个子层。
- 第一个子层是multi-head attention层。在Encoder阶段, Q , K , V Q,K,V Q,K,V
3个矩阵是完全相同的,输出为 R n × d m o d e l \mathbb{R}^{n\times d_{model}} Rn×dmodel。 - 第二个子层是Position-wise Feed-Forward Networks层,实质就是2个FC层中间有一个ReLU函数。输入维度是 R n × d m o d e l \mathbb{R}^{n\times d_{model}} Rn×dmodel,中间隐藏维度为 R n × d f f \mathbb{R}^{n\times d_{ {ff}}} Rn×dff,输出维度不变为 R n × d m o d e l \mathbb{R}^{n\times d_{model}} Rn×dmodel。
Position-wise Feed-Forward Networks层代码实现如下:
class PositionwiseFeedForward(nn.Module):
''' A two-feed-forward-layer module '''
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
self.w_1 = nn.Linear(d_in, d_hid) # position-wise
self.w_2 = nn.Linear(d_hid, d_in) # position-wise
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.layer_norm(x)
return x
Encoder的整体代码如下:
class Encoder(nn.Module):
''' A encoder model with self attention mechanism. '''
def __init__(
self, n_src_vocab, d_word_vec, n_layers, n_head, d_k, d_v,
d_model, d_inner, pad_idx, dropout=0.1, n_position=200, scale_emb=False):
super().__init__()
self.src_word_emb = nn.Embedding(n_src_vocab, d_word_vec, padding_idx=pad_idx)
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position)
self.dropout = nn.Dropout(p=dropout)
self.layer_stack = nn.ModuleList([
EncoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)])
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
self.scale_emb = scale_emb
self.d_model = d_model
def forward(self, src_seq, src_mask, return_attns=False):
enc_slf_attn_list = []
# -- Forward
enc_output = self.src_word_emb(src_seq)
if self.scale_emb:
enc_output *= self.d_model ** 0.5
enc_output = self.dropout(self.position_enc(enc_output))
enc_output = self.layer_norm(enc_output)
for enc_layer in self.layer_stack:
enc_output, enc_slf_attn = enc_layer(enc_output, slf_attn_mask=src_mask)
enc_slf_attn_list += [enc_slf_attn] if return_attns else []
if return_attns:
return enc_output, enc_slf_attn_list
return enc_output,
Decoder
Decoder层,包括了 N = 6 N=6 N=6个相同的层。每一个层包括3个子层。
- 第一个子层是multi-head attention层。输入的目标tensor的 Q , K , V ∈ R m × d m o d e l Q,K,V\in \mathbb{R}^{m\times d_{model}} Q,K,V∈Rm×dmodel,这里 m m m表示目标句子的单词个数,而encoder端的输入 n n n表示输入句子的单词个数。3个矩阵是完全相同的,输出为 R m × d m o d e l \mathbb{R}^{m\times d_{model}} Rm×dmodel。
- 第二个子层是multi-head attention层。 Q ∈ R m × d m o d e l Q\in \mathbb{R}^{m\times d_{model}} Q∈Rm×dmodel是上一层输出的tensor矩阵, K , V ∈ R n × d m o d e l K,V\in \mathbb{R}^{n\times d_{model}} K,V∈Rn×dmodel是相同的,来自于encoder的矩阵,输出为 R m × d m o d e l \mathbb{R}^{m\times d_{model}} Rm×dmodel。
- 第三个子层是Position-wise Feed-Forward Networks层,实质就是2个FC层中间有一个ReLU函数。输入维度是 R m × d m o d e l \mathbb{R}^{m\times d_{model}} Rm×dmodel,中间隐藏维度为 R m × d f f \mathbb{R}^{m\times d_{ {ff}}} Rm×dff,输出维度不变为 R m × d m o d e l \mathbb{R}^{m\times d_{model}} Rm×dmodel
class Decoder(nn.Module):
''' A decoder model with self attention mechanism. '''
def __init__(
self, n_trg_vocab, d_word_vec, n_layers, n_head, d_k, d_v,
d_model, d_inner, pad_idx, n_position=200, dropout=0.1, scale_emb=False):
super().__init__()
self.trg_word_emb = nn.Embedding(n_trg_vocab, d_word_vec, padding_idx=pad_idx)
self.position_enc = PositionalEncoding(d_word_vec, n_position=n_position)
self.dropout = nn.Dropout(p=dropout)
self.layer_stack = nn.ModuleList([
DecoderLayer(d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
for _ in range(n_layers)])
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
self.scale_emb = scale_emb
self.d_model = d_model
def forward(self, trg_seq, trg_mask, enc_output, src_mask, return_attns=False):
dec_slf_attn_list, dec_enc_attn_list = [], []
# -- Forward
dec_output = self.trg_word_emb(trg_seq)
if self.scale_emb:
dec_output *= self.d_model ** 0.5
dec_output = self.dropout(self.position_enc(dec_output))
dec_output = self.layer_norm(dec_output)
for dec_layer in self.layer_stack:
dec_output, dec_slf_attn, dec_enc_attn = dec_layer(
dec_output, enc_output, slf_attn_mask=trg_mask, dec_enc_attn_mask=src_mask)
dec_slf_attn_list += [dec_slf_attn] if return_attns else []
dec_enc_attn_list += [dec_enc_attn] if return_attns else []
if return_attns:
return dec_output, dec_slf_attn_list, dec_enc_attn_list
return dec_output,
softmax层
针对decoder层的输出 ∈ R m × d m o d e l \in \mathbb{R}^{m\times d_{model}} ∈Rm×dmodel,采用一个线性转换 ∈ R d m o d e l × N _ t r g \in \mathbb{R}^{d_{model}\times N\_trg} ∈Rdmodel×N_trg,并且使用softmax归一化得到概率分布 ∈ R m × N _ t r g \in \mathbb{R}^{m\times N\_trg} ∈Rm×N_trg,表示目标句子的每一个单词位置对于目标单词库的所有单词的概率分布。最后利用 m m m个ground truth one-hot label确定CrossEntropy loss。
整体流程
class Transformer(nn.Module):
''' A sequence to sequence model with attention mechanism. '''
def __init__(
self, n_src_vocab, n_trg_vocab, src_pad_idx, trg_pad_idx,
d_word_vec=512, d_model=512, d_inner=2048,
n_layers=6, n_head=8, d_k=64, d_v=64, dropout=0.1, n_position=200,
trg_emb_prj_weight_sharing=True, emb_src_trg_weight_sharing=True,
scale_emb_or_prj='prj'):
super().__init__()
self.src_pad_idx, self.trg_pad_idx = src_pad_idx, trg_pad_idx
# In section 3.4 of paper "Attention Is All You Need", there is such detail:
# "In our model, we share the same weight matrix between the two
# embedding layers and the pre-softmax linear transformation...
# In the embedding layers, we multiply those weights by \sqrt{d_model}".
#
# Options here:
# 'emb': multiply \sqrt{d_model} to embedding output
# 'prj': multiply (\sqrt{d_model} ^ -1) to linear projection output
# 'none': no multiplication
assert scale_emb_or_prj in ['emb', 'prj', 'none']
scale_emb = (scale_emb_or_prj == 'emb') if trg_emb_prj_weight_sharing else False
self.scale_prj = (scale_emb_or_prj == 'prj') if trg_emb_prj_weight_sharing else False
self.d_model = d_model
self.encoder = Encoder(
n_src_vocab=n_src_vocab, n_position=n_position,
d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner,
n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v,
pad_idx=src_pad_idx, dropout=dropout, scale_emb=scale_emb)
self.decoder = Decoder(
n_trg_vocab=n_trg_vocab, n_position=n_position,
d_word_vec=d_word_vec, d_model=d_model, d_inner=d_inner,
n_layers=n_layers, n_head=n_head, d_k=d_k, d_v=d_v,
pad_idx=trg_pad_idx, dropout=dropout, scale_emb=scale_emb)
self.trg_word_prj = nn.Linear(d_model, n_trg_vocab, bias=False)
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
assert d_model == d_word_vec, \
'To facilitate the residual connections, \
the dimensions of all module outputs shall be the same.'
if trg_emb_prj_weight_sharing:
# Share the weight between target word embedding & last dense layer
self.trg_word_prj.weight = self.decoder.trg_word_emb.weight
if emb_src_trg_weight_sharing:
self.encoder.src_word_emb.weight = self.decoder.trg_word_emb.weight
def forward(self, src_seq, trg_seq):
src_mask = get_pad_mask(src_seq, self.src_pad_idx)
trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx) & get_subsequent_mask(trg_seq)
enc_output, *_ = self.encoder(src_seq, src_mask)
dec_output, *_ = self.decoder(trg_seq, trg_mask, enc_output, src_mask)
seq_logit = self.trg_word_prj(dec_output)
if self.scale_prj:
seq_logit *= self.d_model ** -0.5
return seq_logit.view(-1, seq_logit.size(2))
这里涉及到一个src_mask以及trg_mask用来控制 Q Q Q可以访问到的在 K , V K,V K,V中的向量。在encoder阶段,每一个单词都可以访问其他位置的任何单词,即 Q Q Q可以访问全部在 K , V K,V K,V中的向量。src_mask ∈ R n × n \in \mathbb{R}^{n\times n} ∈Rn×n为:这里取 n = 4 n=4 n=4来展示。
1 1 1 1
1 1 1 1
1 1 1 1
1 1 1 1
在decoder阶段,第一个self-attention阶段,此时 Q , K , V Q,K,V Q,K,V都是目标句子embedding,目标句子中的每一个单词只能访问该目标句子的前面时刻的单词,引入trg_mask ∈ R m × m \in \mathbb{R}^{m\times m} ∈Rm×m为:这里取 m = 4 m=4 m=4来展示。
1 0 0 0
1 1 0 0
1 1 1 0
1 1 1 1
在第二个attention阶段,目标句子中的每一个单词可以访问到输入encoder中句子的所有单词,此时的 Q Q Q是目标句子embedding, K , V K,V K,V是encoder输出的embedding,此时仍采用src_mask。
输入句子的预处理
首先需要对单词以及特殊字符编号,首先由如下规则:
0: UNK_WORD = '<unk>'
1: PAD_WORD = '<blank>'
2: BOS_WORD = '<s>'
3: EOS_WORD = '</s>'
单词库中的每一个单词都会有一个编号,UNK_WORD表示未知的单词;PAD_WORD表示用来padding的单词,用空格表示;BOS_WORD和EOS_WORD表示句子的开头和结尾。
针对输入中文句子,它是狗,分词后是[‘它’,‘是’,‘狗’],加入开头和结尾信息,变为[‘BOS’,‘它’,‘是’,‘狗’, ‘EOS’]。为了便于多个不同长度的句子集成在同一个batch中,需要对短句子的长度进行补空格,也就是padding。例如对上述句子补3个空格,变为[‘BOS’,‘它’,‘是’,‘狗’, ‘EOS’, ’ ', ’ ', ’ '], 进行编码后变为[2,376,23, 43,3,1,1,1], 这里376,23, 43分别对应‘它’,‘是’,‘狗’的数字编号。
- Encoder输入:对于padding后的输入[2,376,23, 43,3,1,1,1],去除padding得到有效的信息为[2,376,23, 43,3],也就是5个单词embeddings的tensor作为输入信息。
- Decoder输入:对于目标英文句子 It is a dog. 预处理后的有效信息为[‘BOS’,‘it’,‘is’,‘a’,‘dog’, ‘EOS’], 编码之后为trg=[2,36,253, 433,3]。对于decoder的输入trg[:-1]=[2, 36,253, 433], 对应的ground-truth是trg[:1]=[36,253, 433,3]。因为我们期望当前时刻的信息能够预测下一时刻的单词。例如,利用2得到36,利用[2,36]得到253,… 。
TEST阶段翻译句子
在test阶段,给定输入中文句子到encoder,得到输出embedding信息。在decoder输入端,给定BOS token(编号为2)以及encoder的输出信息,可以得到下一个目标单词,该单词加入到decoder的输入中。该过程直至decoder预测出EOS token(编号为3)为止。