Sequential Matching Network A NewArchitecture for Multi-turn Respomse Selection in Retrieval-Based Chatbots 论文实现
论文链接:
https://arxiv.org/abs/1612.01627
论文目的:
多轮QA response候选集匹配
重要问题:
1、 在context中寻找匹配response的关键信息。
2、 在utterance间建立关系。(如问答的语序关系等)
SMN的整体思路:
1、 对于每一个上下文中的utterance匹配一个response,将匹配信息编码为向量。
2、 对于匹配信息向量在时序上的关系进行建模。(通过建立word-word 相似阵(word embedding) seq-seq相似阵(hidden state fromgru 在两个水平上进行特征匹配)),使用卷积及pooling进行特征提取得到新的匹配向量。
3、 匹配向量进入另一个gru来计算匹配得分,计算隐状态的变换,并使用交叉熵做response关于utterance的二分类。
这里“隐状态”的线性变换,文中提出了三种可能的选择,分别为最后一个隐状态、所有隐状态的线性变换、隐状态的attension。并在文后的实验结果中指出在使用gru进行特征提取的情况下三者的差距不大。
模型示意图:
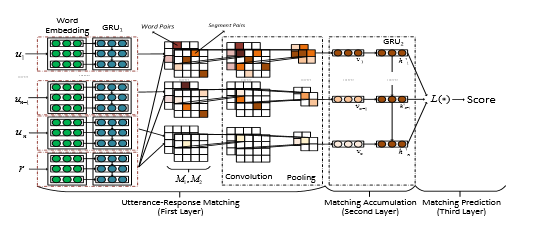
数据说明:
实测数据使用的是文中的豆瓣数据集
https://www.dropbox.com/s/90t0qtji9ow20ca/DoubanConversaionCorpus.zip?dl=0
其已经完成了数据集的分割及打标签的工作,在实际操作时仅需要进行编码即可。
数据处理(简单)实现:
from collections import Counter
from functools import reduce
def data_process():
train_cnt = Counter()
line_cnt = 0
with open(r"DoubanConversaionCorpus/DoubanConversaionCorpus/train.txt", encoding="utf-8") as f:
while True:
line = f.readline().strip()
if line:
line_split = line.split("\t")
label = line_split[0]
s_list = line_split[1:-1]
response = line_split[-1]
line_word_list = reduce(lambda x, y: x+y, map(lambda seg: seg.split(" ") ,s_list + [response]))
train_cnt.update(line_word_list)
line_cnt += 1
if line_cnt % 10000 == 0:
print(line_cnt)
else:
print("train read end")
break
line_cnt = 0
with open(r"DoubanConversaionCorpus/DoubanConversaionCorpus/test.txt", encoding="utf-8") as f:
while True:
line = f.readline().strip()
if line:
line_split = line.split("\t")
label = line_split[0]
s_list = line_split[1:-1]
response = line_split[-1]
line_word_list = reduce(lambda x, y: x+y, map(lambda seg: seg.split(" ") ,s_list + [response]))
train_cnt.update(line_word_list)
line_cnt += 1
if line_cnt % 10000 == 0:
print(line_cnt)
else:
print("test read end")
break
word2idx = dict((word, idx) for idx, word in enumerate(train_cnt.keys()))
with open("word2idx.pkl", "wb") as f:
import pickle
pickle.dump(word2idx, f)
line_cnt = 0
with open("train_idx.txt", "w") as o:
with open(r"DoubanConversaionCorpus/DoubanConversaionCorpus/train.txt", encoding="utf-8") as f:
while True:
line = f.readline().strip()
if line:
line_split = line.split("\t")
label = line_split[0]
s_list = line_split[1:-1]
response = line_split[-1]
req_line = str(label) + "\t" + "\t".join(map(lambda seg: " ".join(map(lambda x: str(word2idx[x]) ,seg.split(" "))) ,s_list + [response]))
req_line += "\n"
o.write(req_line)
line_cnt += 1
if line_cnt % 10000 == 0:
print(line_cnt)
else:
print("train write end")
break
line_cnt = 0
with open("test_idx.txt", "w") as o:
with open(r"DoubanConversaionCorpus/DoubanConversaionCorpus/test.txt", encoding="utf-8") as f:
while True:
line = f.readline().strip()
if line:
line_split = line.split("\t")
label = line_split[0]
s_list = line_split[1:-1]
response = line_split[-1]
req_line = str(label) + "\t" + "\t".join(map(lambda seg: " ".join(map(lambda x: str(word2idx[x]) ,seg.split(" "))) ,s_list + [response]))
req_line += "\n"
o.write(req_line)
line_cnt += 1
if line_cnt % 10000 == 0:
print(line_cnt)
else:
print("test write end")
break
if __name__ == "__main__":
data_process()
在这里实现的版本用lstm代替了第一层于utterance中提取特征的gru,用BasicRNNCell代替了第二层gru,对于第二层rnn产生的隐状态也是采用关于序列方向取平均之后进入softmax层。采取这些替换的原因是采取原文模型设计时收敛较慢,根据下面的代码改回原文模型实现也是比较简单的。
采取上述模型设定后,有可能在后期训练产生过拟合现象,顾添加了l2正则及dropout,这里正则的采取影响较为温和,droput keep的概率去除的信息较大为0.5,实际操作时可能考虑适当减少dropout产生的信息损失。(如果对这个模型的调优有什么好的意见,欢迎指出)
实现上用了一些mask操作来处理变长输入问题, 也使用 tf.map_fn 进行了一些统一的映射处理(可能会造成部分性能损失)。
模型构建:
import tensorflow as tf
import numpy as np
import pickle
with open("word2idx.pkl", "rb") as f:
word2idx = pickle.load(f)
def data_generator(type = "train", batch_num = 64, utterance_max_len = 50, response_max_len = 100,
max_u_num = 10):
times = 0
start_idx = 0
s_array = np.full(shape=[batch_num, max_u_num, utterance_max_len], fill_value=len(word2idx))
r_array = np.full(shape=[batch_num, response_max_len], fill_value=len(word2idx))
y_array = np.full(shape = [batch_num], fill_value=0)
u_slice_array = np.zeros(shape=[batch_num])
u_len_array = np.zeros(shape=[batch_num, max_u_num])
r_len_array = np.zeros(shape=[batch_num])
with open("{}_idx.txt".format(type)) as f:
while True:
line = f.readline().strip()
if line:
line_split = line.split("\t")
label = line_split[0]
s_list = line_split[1:-1]
response = line_split[-1]
line_word_list = list(map(lambda seg: list(map(int ,seg.split(" "))) ,s_list + [response]))
s_list = line_word_list[:-1]
response = line_word_list[-1]
for u_idx, u, in enumerate(s_list):
if u_idx == max_u_num:
break
u = u[:utterance_max_len]
for uwidx, w in enumerate(u):
s_array[start_idx][u_idx][uwidx] = w
u_len_array[start_idx][u_idx] = len(u)
response = response[:response_max_len]
for rwidx, w in enumerate(response):
r_array[start_idx][rwidx] = w
r_len_array[start_idx] = len(response)
y_array[start_idx] = int(label)
u_slice_array[start_idx] = min(max_u_num, len(s_list))
start_idx += 1
if start_idx == batch_num:
yield s_array, r_array, y_array, u_slice_array ,u_len_array, r_len_array
start_idx = 0
times += 1
#print("times {}".format(times))
if times == 1e10:
print("will return in {}".format(type))
return
else:
return
class SMN(object):
def __init__(self, utterance_max_len = 50, response_max_len = 100, vocab_size = int(1e4), word_embedding_dim = 100,
u_r_gru_size = 100, m_a_gru_size = 100,
cnn_filter_sizes = [3, 4, 5], num_filters = 3,
q_dim = 100, batch_num = 64, l2_punishment_param = 0.1):
self.utterance_max_len = utterance_max_len
self.response_max_len = response_max_len
self.vocab_size = vocab_size
self.word_embedding_dim = word_embedding_dim
self.batch_num = batch_num
self.l2_punishment_param = l2_punishment_param
self.drop_prob = tf.placeholder(dtype=tf.float32, shape=[])
# network parameter
self.u_r_gru_size = u_r_gru_size
self.m_a_gru_size = m_a_gru_size
self.cnn_filter_sizes = cnn_filter_sizes
self.num_filters = num_filters
self.q_dim = q_dim
self.s = tf.placeholder(tf.int32, [None, None, utterance_max_len])
self.r = tf.placeholder(tf.int32, [None, response_max_len])
self.y = tf.placeholder(tf.int32, [None])
self.u_slice_input = tf.placeholder(tf.int32, [None])
self.u_len_input = tf.placeholder(tf.int32, [None, None])
self.r_len_input = tf.placeholder(tf.int32, [None])
#[batch_size, slice_max]
self.u_slice_mask = tf.sequence_mask(self.u_slice_input)
# model construct
self.model_construct()
def model_construct(self):
batch_v = self.utterance_response_matching_layer()
self.matching_accumulation_layer(batch_v)
self.train_op = tf.train.AdamOptimizer(0.001).minimize(self.total_loss)
def cnn_layer(self, M, h_size = 3, max_pool_size = 2):
# Create a convolution + maxpool layer for each filter size
pooled_outputs = []
for i, filter_size in enumerate(self.cnn_filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# Convolution Layer
filter_shape = [filter_size, h_size, 1, self.num_filters]
W = tf.get_variable(
shape=filter_shape,dtype=tf.float32,initializer=tf.initializers.random_normal(),
name="cnn_W_{}".format(filter_size)
)
b = tf.get_variable(
shape=[self.num_filters], dtype=tf.float32, initializer=tf.initializers.constant(1.0),
name= "cnn_b_{}".format(filter_size)
)
conv = tf.nn.conv2d(
M,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Maxpooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, max_pool_size, max_pool_size, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_final_shape = pooled.get_shape()
final_size = int(pooled_final_shape[-1]) * int(pooled_final_shape[-2]) * int(pooled_final_shape[-3])
pooled_outputs.append(tf.reshape(pooled, [-1, final_size]))
return tf.concat(pooled_outputs, -1)
def single_slice_fn(self, elem):
elem_true_num = tf.reduce_sum(tf.cast(elem, tf.int32))
mask_slice = tf.boolean_mask(self.batch_v, elem)
req = tf.concat([mask_slice, tf.zeros([self.max_mask_num - elem_true_num, self.q_dim], dtype=tf.float32)], axis = 0)
return req
def utterance_response_matching_layer(self):
with tf.name_scope("word_embedding"):
self.Word_Embed = tf.Variable(
tf.random_normal(shape=[self.vocab_size, self.word_embedding_dim]),
dtype=tf.float32
)
# [None, utterance_max_len
flatten_s = tf.boolean_mask(self.s, self.u_slice_mask)
max_mask_num = tf.reduce_max(self.u_slice_input)
self.max_mask_num = max_mask_num
r_for_slice = tf.reshape(tf.tile(self.r, [1, max_mask_num]), [-1, max_mask_num, self.response_max_len])
# [None, response_max_len]
flatten_r = tf.boolean_mask(r_for_slice, self.u_slice_mask)
flatten_s_lookup = tf.nn.embedding_lookup(self.Word_Embed, flatten_s)
flatten_r_lookup = tf.nn.embedding_lookup(self.Word_Embed, flatten_r)
sum_mask_num = tf.reduce_sum(self.u_slice_input)
flatten_concat = tf.slice(tf.concat([tf.reshape(flatten_s_lookup, [-1, self.utterance_max_len * self.word_embedding_dim]),
tf.reshape(flatten_r_lookup, [-1, self.response_max_len * self.word_embedding_dim])], axis=-1), [0, 0], [sum_mask_num, -1],
name="M1_input")
def gen_M1(input):
'''
:param u_input: [u_len, embed_dim]
:param r_input: [r_len, embed_dim]
:return:
'''
u_input = tf.reshape(tf.slice(input, [0], [self.utterance_max_len * self.word_embedding_dim]), [self.utterance_max_len, self.word_embedding_dim])
r_input = tf.reshape(tf.slice(input, [self.utterance_max_len * self.word_embedding_dim], [self.response_max_len * self.word_embedding_dim]),
[self.response_max_len, self.word_embedding_dim])
return tf.matmul(u_input, tf.transpose(r_input, [1, 0]), name="M1")
batch_M1_list = tf.map_fn(gen_M1, flatten_concat)
u_r_gru_cell = tf.contrib.rnn.LSTMCell(self.u_r_gru_size,
initializer = tf.contrib.layers.xavier_initializer(uniform=False))
flatten_u_len = tf.squeeze(tf.boolean_mask(self.u_len_input, self.u_slice_mask))
# s_outputs [sum_mask_num, utterance_max_len, hidden_size]
s_outputs, _ = tf.nn.dynamic_rnn(
cell=u_r_gru_cell,
dtype=tf.float32,
sequence_length=flatten_u_len,
inputs=flatten_s_lookup)
r_len_for_slice = tf.tile(tf.expand_dims(self.r_len_input, 1), [1, max_mask_num])
flatten_r_len = tf.boolean_mask(r_len_for_slice, self.u_slice_mask)
# r_outputs [sum_mask_num, response_max_len, hidden_size]
r_outputs, _ = tf.nn.dynamic_rnn(
cell=u_r_gru_cell,
dtype=tf.float32,
sequence_length=flatten_r_len,
inputs=flatten_r_lookup)
M2_input = tf.concat([s_outputs, r_outputs], axis=1, name="M2_input")
A = tf.Variable(
tf.random_normal(shape=[self.u_r_gru_size, self.u_r_gru_size]),
dtype=tf.float32
)
def gen_M2(input):
u_input = tf.slice(input, [0, 0], [self.utterance_max_len, -1])
r_input = tf.slice(input, [self.utterance_max_len, 0], [self.response_max_len, -1])
return tf.matmul(tf.matmul(u_input, A), tf.transpose(r_input, [1, 0]))
batch_M2_list = tf.map_fn(gen_M2, M2_input)
# [sum_mask_num, utterance_max_len, response_max_len]
batch_M1 = tf.expand_dims(batch_M1_list, -1)
batch_M2 = tf.expand_dims(batch_M2_list, -1)
with tf.variable_scope("cnn_layer", reuse=tf.AUTO_REUSE):
M1_cnn_output = self.cnn_layer(batch_M1)
M2_cnn_output = self.cnn_layer(batch_M2)
M1_M2_cnn_output = tf.concat([M1_cnn_output, M2_cnn_output], axis=-1)
W1 = tf.Variable(tf.random_normal(shape=[int(M1_M2_cnn_output.get_shape()[-1]), self.q_dim]), name="W1")
b1 = tf.Variable(tf.constant([1.0] * self.q_dim), name="b1")
batch_v = self.before_softmax = tf.nn.xw_plus_b(M1_M2_cnn_output, W1, b1)
self.batch_v = batch_v
cumsum_mask_num_second = tf.cumsum(self.u_slice_input)
cumsum_mask_num_first = tf.slice(tf.concat([tf.constant([0]), cumsum_mask_num_second], axis=0), [0], [self.batch_num])
cumsum_seq_mask_first = tf.cast(tf.sequence_mask(cumsum_mask_num_first, maxlen=sum_mask_num), tf.int32)
cumsum_seq_mask_second = tf.cast(tf.sequence_mask(cumsum_mask_num_second, maxlen=sum_mask_num), tf.int32)
cumsum_seq_mask = tf.cast(cumsum_seq_mask_second - cumsum_seq_mask_first, tf.bool)
# [batch_size, max_mask_num, q_dim]
batch_v = tf.map_fn(self.single_slice_fn, cumsum_seq_mask, dtype=tf.float32)
return batch_v
def matching_accumulation_layer(self, batch_v):
m_a_gru_cell = tf.contrib.rnn.BasicRNNCell(self.m_a_gru_size, activation = tf.nn.relu)
m_a_outputs, m_a_final_state = tf.nn.dynamic_rnn(
cell=m_a_gru_cell,
dtype=tf.float32,
sequence_length=self.u_slice_input,
inputs=batch_v)
m_a_final_state = tf.reduce_mean(m_a_outputs, axis=1)
m_a_final_state = tf.nn.dropout(m_a_final_state, keep_prob=self.drop_prob)
W2 = tf.Variable(tf.random_normal(shape=[int(m_a_final_state.get_shape()[-1]), 2]), name="W2")
b2 = tf.Variable(tf.constant([1.0] * 2), name="b2")
self.before_softmax = tf.nn.xw_plus_b(m_a_final_state, W2, b2)
self.loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=tf.one_hot(self.y, depth=2, dtype=tf.float32),
logits=self.before_softmax))
trainable_variables = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)
self.l2_loss = None
for ele in trainable_variables:
if self.l2_loss is None:
self.l2_loss = tf.nn.l2_loss(ele)
else:
self.l2_loss += tf.nn.l2_loss(ele)
self.total_loss = self.l2_punishment_param * self.l2_loss + self.loss
self.pred = tf.cast(tf.argmax(tf.nn.softmax(self.before_softmax), axis=-1), tf.int32)
self.acc = tf.reduce_mean(tf.cast(tf.equal(self.pred, self.y), tf.float32))
@staticmethod
def train():
batch_size = 64
smn= SMN(vocab_size=len(word2idx) + 1 ,batch_num=batch_size)
step = 0
epoch = 0
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
train_gen = data_generator(type="train")
test_gen = data_generator(type="test")
while True:
try:
s_array, r_array, y_array, u_slice_array ,u_len_array, r_len_array = train_gen.__next__()
except:
print("epoch {} end".format(epoch))
epoch += 1
train_gen = data_generator(type="train")
_, loss, acc = sess.run([smn.train_op, smn.loss, smn.acc
], feed_dict={
smn.s: s_array,
smn.r: r_array,
smn.y: y_array,
smn.u_slice_input: u_slice_array,
smn.u_len_input: u_len_array,
smn.r_len_input: r_len_array,
smn.drop_prob: 0.5
})
if step % 1 == 0:
print("train loss:{} acc:{}".format(loss, acc))
if step % 10 == 0:
try:
s_array, r_array, y_array, u_slice_array ,u_len_array, r_len_array = test_gen.__next__()
except:
print("test end")
test_gen = data_generator(type="test")
loss, acc = sess.run([smn.loss, smn.acc], feed_dict={
smn.s: s_array,
smn.r: r_array,
smn.y: y_array,
smn.u_slice_input: u_slice_array,
smn.u_len_input: u_len_array,
smn.r_len_input: r_len_array,
smn.drop_prob: 1.0
})
print("test loss:{} acc:{}".format(loss, acc))
step += 1
if __name__ == "__main__":
SMN.train()