Multi-field Categorical Data会有多种不同的字段,比如:[Weekday=Wednesday, Gender=Male, City=London,…],那这样我们就比较难识别这些特征之间的关系。给大家举例一个直观的场景:比如现在有一个凤凰网站,网站上面有一个迪斯尼广告,那我们现在想知道用户进入这个网站之后会不会有兴趣点击这个广告,类似这种用户点击率预测在信息检索领域就是一个非常核心的问题。普遍的做法就是通过不同的域来描述这个事件然后预测用户的点击行为,而这个域可以有很多。那么什么样的用户会点击这个广告呢?我们可能猜想:目前在上海的年轻的用户可能会有需求,如果今天是周五,看到这个广告,可能会点击这个广告为周末做活动参考。那可能的特征会是:[Weekday=Friday, occupation=Student, City=Shanghai],当这些特征同时出现时,我们认为这个用户点击这个迪斯尼广告的概率会比较大。
传统的做法是应用One-Hot Binary的编码方式去处理这类数据,例如现在有三个域的数据X=[Weekday=Wednesday, Gender=Male, City=Shanghai],其中 Weekday有7个取值,我们就把它编译为7维的二进制向量,其中只有Wednesday是1,其他都是0,因为它只有一个特征值;Gender有两维,其中一维是1;如果有一万个城市的话,那City就有一万维,只有上海这个取值是1,其他是0。
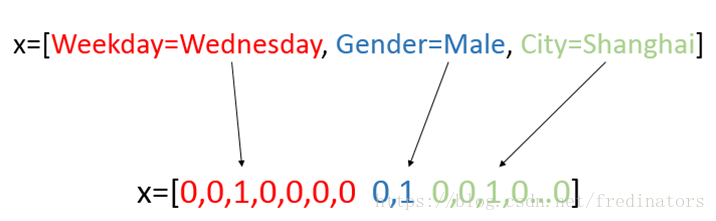
那最终就会得到一个高维稀疏向量。但是这个数据集不能直接用神经网络训练:如果直接用One-Hot Binary进行编码,那输入特征至少有一百万,第一层至少需要500个节点,那么第一层我们就需要训练5亿个参数,那就需要20亿或是50亿的数据集,而要获得如此大的数据集基本上是很困难的事情。
FM、FNN以及PNN模型
因为上述原因,我们需要将非常大的特征向量嵌入到低维向量空间中来减小模型复杂度,而FM(Factorisation machine)——最有效的embedding model:
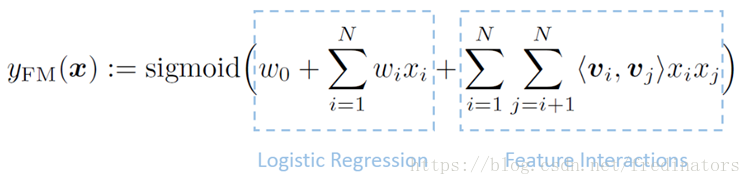
第一部分仍然为Logistic Regression,第二部分是通过两两向量之间的点积来判断特征向量之间和目标变量之间的关系。比如上述的迪斯尼广告,occupation=Student和City=Shanghai这两个向量之间的角度应该小于90,它们之间的点积应该大于0,说明和迪斯尼广告的点击率是正相关的。这种算法在推荐系统领域应用比较广泛。
那我们就基于这个模型来考虑神经网络模型,其实这个模型本质上就是一个三层网络:
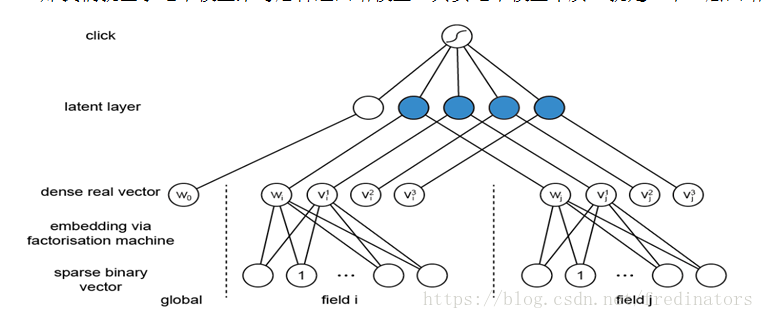
它在第二层对向量做了乘积处理(比如上图蓝色节点直接为两个向量乘积,其连接边上没有参数需要学习),每个field都只会被映射到一个low-dimensional vector,field和field之间没有相互影响,那么第一层就被大量降维,之后就可以在此基础上应用神经网络模型。
我们用FM算法对底层field进行embeddding,在此基础上面建模就是FNN(Factorisation-machinesupported Neural Networks)模型:

模型底层先用FM对经过one-hot binary编码的输入数据进行embedding,把稀疏的二进制特征向量映射到dense real 层,之后再把dense real 层作为输入变量进行建模,这种做法成功避免了高维二进制输入数据的计算复杂度。
那我们把这些模型应用到iPinYou数据集上,模型效果如下所示:
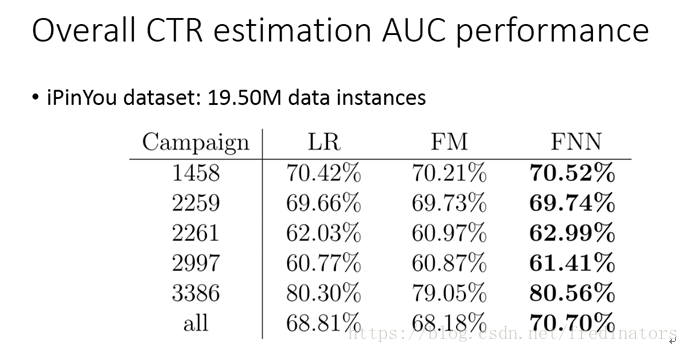
那我们可以看出FNN的效果优于LR和 FM 模型。我们进一步考虑FNN与一般的神经网络的区别是什么?大部分的神经网络模型对向量之间的处理都是采用加法操作,而FM 则是通过向量之间的乘法来衡量两者之间的关系。我们知道乘法关系其实相当于逻辑“且”的关系,拿上述例子来说,只有特征是学生而且在上海的人才有更大的概率去点击迪斯尼广告。但是加法仅相当于逻辑中“或”的关系,显然“且”比“或”更能严格区分目标变量。
所以我们接下来的工作就是对乘法关系建模。可以对两个向量做内积和外积的乘法操作:
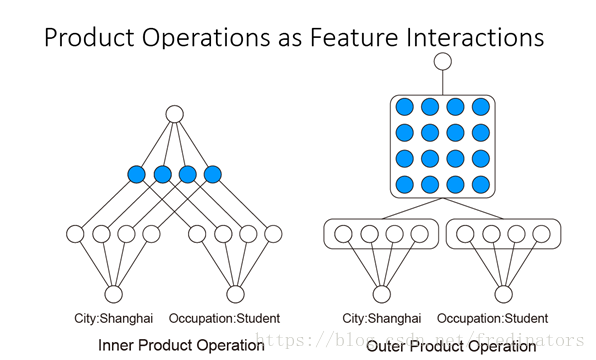
可以看出对外积操作得到矩阵而言,如果该矩阵只有对角线上有值,就变成了内积操作的结果,所以内积操作可以看作是外积操作的一种特殊情况。通过这种方式,我们就可以衡量两个不同域之间的关系。
在此基础之上我们搭建的神经网络如下所示:
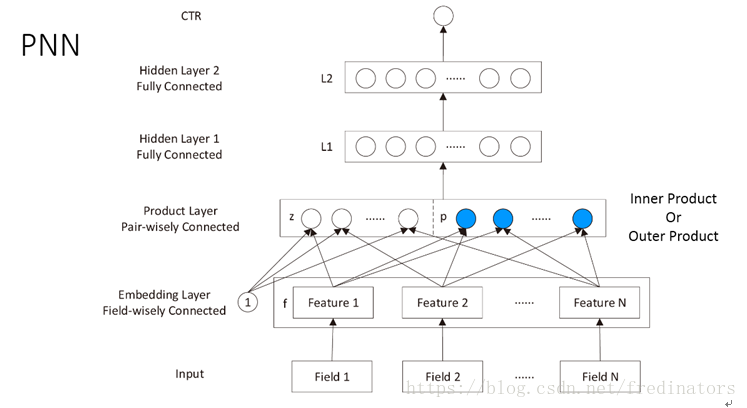
首先对输入数据进行embedding处理,得到一个low-dimensionalvector层,对该层的任意两个feature进行内积或是外积处理就得到上图的蓝色节点,另外一种处理方式是把这些Feature直接和1相乘复制到上一层的Z中,然后把Z和P接在一起就可以作为神经网络的输入层,在此基础上我们就可以应用神经网络去模型了。
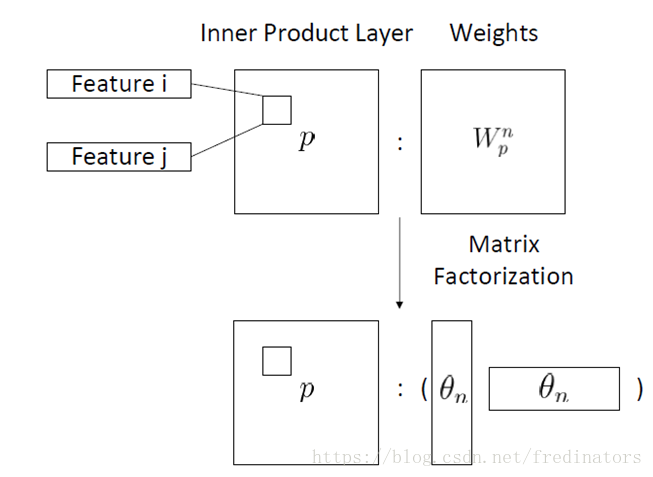
那么对特征做内积或是外积处理就会产生一个复杂度的问题:假设有60个域,那么把这些feature做内积处理,就会产生将近1000多个元素的矩阵(),如此就会产生一个很大的weight矩阵,那我们需要学习的参数就很多,那我们的数据集可能就满足不了这个要求。那接下来的做法就是:由于weight矩阵是个对称阵,我们可以用factorization来处理这个对称阵,把它转换为一个小矩阵乘以这个小矩阵的转置,这样就会大大减少我们所需要训练的参数:
我们应用的比较算法有:LR (Logistic regression)、FM(Factorisation machine)、FNN(Factorisation machinesupported neural network)、CCPM(Convolutional click prediction model)、PNN-I(Inner product neuralnetwork)、PNN-II(Outer product neural network)、PNN-III(Inner&outerproduct ensembled neural network)
测试了最佳的隐层层数,隐层层数并不是越多越好,层数过多的模型会出现过拟合效应,这个隐层数是跟数据集大小相关,一般而言数据集越大所需要的隐层就越多,我们这里模型显示的最佳隐层是3层:
对比了不同隐层节点的Activation Functions的效果,结果发现tanh 和 relu明显优于sigmoid。
深度学习在多字段分类数据集上也能取得显著的应用效果;
通过内积和外积操作找到特征之间的相关关系;
在广告点击率的预测中,PNN效果优于其他模型。