人体姿态作为合成 token —— CVPR2023
摘要: 人体姿态常由身体关节的坐标向量或其热图embedding表示。虽然数据易于处理,但由于身体关节间缺乏依赖建模,即使是不现实的姿态也被接受。本文提出了一种结构化表示:Pose as Compositional Tokens(PCT),以探索关节依赖性,PCT 由M个离散的 token 表示一个姿态,每个token 都表征一个具有几个相互依赖关节的子结构(见图1)。这种合成设计能以低成本实现微小的重建误差,然后将姿态估计视作一项 分类任务。具体而言,学习一个分类器来预测图像中M个token的类别。 一个预训练的 decoder 网络在无需后处理的情况下从 token 中恢复姿态。实验表明,PCT 在遮挡情况下的性能更佳,在普通情况下能实现相较现有方法更好或相当的结果。

文章目录
1. Introduction
近几年的人体姿态工作关注网络结构(如 HRNet,VitPose等)、训练方法(如弱监督,无监督,半监督等)以及融合策略,这些工作显著提高了姿态估计方法在公共数据集上的准确性。但具有挑战性的遮挡情况仍是一个悬而未决的问题,阻碍了姿态估计在实践中的应用。
无论是用坐标向量还是用热图embedding表示关节,关节都被独立处理,这忽略了身体关节间的依赖性,因此,如图2所示,在遮挡情况下会估计出不切实际的姿态。人体可以通过可见关节和视觉特征来预测完整姿态,一些工作引入树或图结构来建模关节间依赖性,但手工设计的规则通常会对依赖关系做不切实际的假设,使其无法代表复杂的模式。

本工作尝试无需任何假设,在表示阶段的早期,学习关节间的依赖关系。我们最初的想法是学习一组逼真的原型姿态,并用最接近的原型来表示每个姿态,虽然这样能保证所有姿态是真实的,但需要大量的原型模型将量化误差降低到一个合理的水平,这对算力的要求很高,因此,我们提出了一个分离的表示:PCT。
图3所示为 PCT 表示的两个stage:
- stage1 学习一个组合encoder 将一个姿态转换为M个token features,每个token feature编码一个姿态的子结构(图1为子结构实例)。然后这些token被一个共享的codebook量化,因此,一个姿态就能被M个分离的 index 简单表示。codebook 的空间足够大以精确表示所有姿态。我们通过最小化重构误差来联合学习 encoder、codebook 和 decoder。
- stage2 将人体姿态估计cast为一个分类任务:给定图像,预测M个token的类别,decoder 网络从中恢复姿态。PCT表示有一些优点:① 首先,关节间的依赖性由 token 建模,有助于避免估计不切实际的姿态,定性实验结果表明(图2 bottom),即使大部分身体部位被遮挡,也可能获得合理估计。② 其次,它无需任何像热图那样减少量化误差的高代价后处理模块,如UDP(The devil is in the details)。③ 它为2D和3D姿态提供了统一的表示。(此外,离散表示也可能促进其与其他离散模态(如文本和语音)的交互,但这并不是这项工作的重点。)

我们在5个2D姿态估计基准数据集上广泛评估了我们的方法,结果与目前的 sota 方法相比有过之而无不及。而且,其能更好的应对遮挡关节,验证了其依赖建模能力的优势。我们的方法在3D姿态估计H36M数据集上实现了与使用简单架构的 sota 方法相当的精度,这表明该方法具有广泛的适用性。
2. Related works
2.1. Pose representations
Coordinates. 坐标法虽然效率高,但因为其难以学习高度非线性的mapping,因此其精度不如热图法。一些工作通过关注关节周围的局部特征来改进它们。残差对数似然估计RLE提出了一种新的回归范式来捕捉潜在的输出分布。MDN引入了用于回归的混合密度网络。最近,transformer 由于其捕获long-range 信息的能力,给坐标法带来了显著改进。
Heatmap. 热图表示具有强大的定位和泛化能力,自引入以来就一直独占鳌头。许多后续工作致力于不断改进热图法,包括提出强大的网络来更准确地估计热图、引入注意力算子、减少量化误差、与坐标法融合、细化结果、利用其他任务、利用大型 unlabelled 数据集。但热图法需要下采样操作,因此在解码时会引起量化误差。此外,热图无法建模关节相关性。
Discrete bins. 最近的工作[A unified sequence interface for vision tasks,Is 2d heatmap representation even necessary for human pose estimation,Unified-io: A unified model for vision, language, and multi-modal tasks]提出将单个 pixel 划分为多个 bins,从而实现 sub-pixel 定位精度。每个关节的水平坐标和垂直坐标被分别量化为离散的类。与我们的工作类似,他们也将人体姿态估计cast 为一项分类任务,但独立处理姿态的每个坐标,这不同于我们的结构化表示。
2.2. Modeling joint dependency
由于人体具有关节结构,因此许多工作试图建模关节依赖性,以帮助解决 low-level 的模糊性,但绝大部分工作都关注于建模而非表示,而本工作着重关注于表示。
Pictorial structures. 一些工作提出使用可变形模型,基于解剖先验(例如肢体长度)来明确考虑身体关节间的关系。但它们有三个缺点:① 首先,他们通常对关系做出强有力的假设,例如两个关节间偏移的高斯分布,使他们无法表示复杂的模式。② 其次,他们仍需要先从图像中独立检测身体关节,并在此基础上使用依赖先验来获得最合理的配置。然而,在有严重遮挡的杂乱场景中,第一步已经非常困难了。③ 他们无法用深度网络进行端到端训练。
Implicit modeling. 最近的基于深度学习的方法通过在关节之间传播视觉特征来隐式建模依赖性。例如,Chu等人引入了几何变换 kernel 来融合不同通道的特征,不同通道表示不同关节的特征。Wang等人使用图卷积网络 refine 由热图法得到的姿态估计。此外,Chen等人提出学习姿态鉴别器,以排除不现实的姿态估计,并推动预测器学习具有合理结构的姿态。Li等人明确学习每个关节的 type embedding,并应用 transformer 对关节间的关系进行建模,不过从表示的角度来看,他们仍独立处理每个关节,并预测每个关节的热图。
我们的 PCT 表示在三个方面与之前的方法不同:① 首先,关节依赖性在表示中由 token 提前编码(改变 token 的状态会改变相应的子结构,而不是单个关节),相比之下,其他三种表示分别处理每个关节。② 其次,子结构是从训练数据中自动学习的,因此不会做出任何不切实际的假设,实验表明,这种方法具有处理遮挡歧义的强大能力。③ 第三,显示强加关节依赖,而非通过隐式特征传播,后者仍会在遮挡(或其他挑战性场景)情况下进行不切实际的姿态估计。
3. Pose as Compositional Tokens
3.1节描述如何学习 codebook 和 encoder/decoder 网络。3.2节解释PCT如何在人体姿态估计任务中使用。
3.1. Learning compositional tokens
G ∈ R K × D G∈R^{K×D} G∈RK×D是原始姿态,K是身体关节数量,D是每个关节的维度,对于2D姿态估计 D=2。我们学习一个 compositional encoder: f e ( ⋅ ) f_e(·) fe(⋅) 将一个姿态转换为 M 个 token features:

每个token feature t i ∈ R H t_i∈R^H ti∈RH 近似对应于姿态的子结构,该子结构包含几个相互依赖的关节。图1所示为一些学习的示例。注意,这个表示有许多冗余,因为不同的token可能有重叠的关节。冗余度使其对单个遮挡关节具有鲁棒性。
图3(c)显示了encoder网络结构,每个身体关节先喂给一个 linear projection 层去提高特征维度,然后特征再喂给一系列 MLP-Mixer blocks来深度融合不同关节特征。最后,通过对所有关节上的特征应用 linear projection 来提取M个 token features。
与 [Neural discrete representation learning] 一样,通过一个 codebook C = ( c 1 , . . . , c V ) T C=(c_1,...,c_V)^T C=(c1,...,cV)T,(V表示 codebook entries 数量)定义一个隐式 embedding space。使用 embedding space 通过最近邻查找来量化每个token,如以下等式所示:

使用 q ( t i ) q(t_i) q(ti)来表示对应codebook entry 的索引,然后,将量化的 tokens ( c q ( t 1 ) , c q ( t 2 ) , ⋅ ⋅ ⋅ , c q ( t M ) cq(t_1), cq(t_2),···,cq(t_M) cq(t1),cq(t2),⋅⋅⋅,cq(tM))喂给 decoder 网络以恢复原始姿态:

decoder 除了使用只有一个 block 的较浅 MLP Mixer 网络之外,网络结构与 encoder 网络的顺序相反。
通过最小化训练集上的以下loss来联合学习 encoder 网络,codebook 和 decoder 网络:

遵循[Neural discrete representation learning]中使用的优化策略来处理量化步骤中的 broken gradients 问题,并且使用先前 的 token features 的指数移动平均 (EMA) 来更新 codebook。我们的实现中,有两个改进结果的设计:① 首先,随机 mask 一些关节,并要求模型重建它们。② 其次,将关节周围的图像特征与位置特征连接起来,以增强其识别能力。
Discussion. 我们试图解释为什么PCT能学习与姿态子结构相对应的token。在一个极端例子中,若每个 token 对应单个关节,那么需要 w×h(关节点也是以一个像素表示的,那么对于大小为256×256的图像为65536)个 codebook entries 来实现小量化误差。但我们的实验仅使用了1024个entries,这驱动模型学习比单个关节更大的结构,以提高 codebook 的效率。另一个极端例子,若让一个 token 对应于一个完整的姿态,那么只需要一个 token,而不是M个 token。但最坏情况下,为了以小误差来量化姿态,需要 ( w h ) K (wh)^K (wh)K 个codebook entries。相反,我们的方法驱动模型将一个姿态划分为多个基本子结构,并且可以用一个共享的 set 来描述这些基本子结构的可能的配置。
Relation to VQ-VAE. PCT表示法的灵感来自 VQ-VAE [Neural discrete representation learning],主要区别在于,VQ-VAE将定义明确的规则数据(例如,分辨率为16×16的图像 patch)视为 token。但对于人体姿态,我们通过合成encoder 和 codebook 共享方案实现PCT自动学习有意义的子结构作为token。此外,编码器和解码器的网络结构是专门针对人体姿态设计的,不同于VQ-VAE。
3.2. Human Pose Estimation
利用学习的 codebook 和 decoder,我们将人体姿态估计作为一项分类任务。如图3所示,给定 cropped 图像 I,简单预测M个 token 的类别,并将这些 token 喂给 decoder 以恢复姿态。使用 backbone 来提取图像特征X,并设计以下分类头。
Classification head: 先使用两个基本的残差卷积块来调制 backbone 特征,然后展平特征,并通过一个 linear projection layer 来更改维度:

将一个 1-D output feature reshape 为一个矩阵 X f ∈ R M × N X_f∈R^{M×N} Xf∈RM×N,使用 4 个 MLP-Mixer block 处理 features,并且输出 token 分类的logits:

Training. 使用两个loss来训练分类头:首先,强制执行交叉熵损失:

L 表示将 GT pose喂给 encoder 获得的 gt token classes。
强制执行一个 pose reconstruction loss 来最小化预测姿态和 gt 姿态间的差异。为了让来自 decoder 网络的梯度流回分类头,将硬推理方案替换为软版本:

S ∈ R M × N S∈R^{M×N} S∈RM×N 表示线性插值 token features。然后将 token features S 喂给预学习的 decoder 以获得预测的姿态 G ^ \hat{G} G^。完整的损失函数为:
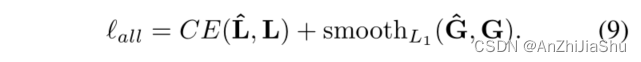
注意,解码器网络在训练期间不进行更新。
4. Experiments
4.1. Datasets and metrics
2D pose datasets: 选用 COCO、MPII、CrowdPose test set、OCHuman val set 和 test set、SyncOCC数据集*[Adafuse: Adaptive multiview fusion for accurate human pose estimation in the wild]*,SyncOCC 数据集是由 UnrealCV 生成的合成数据集,因此它提供了遮挡关节的准确位置。在COCO数据集上训练的模型应用于四个数据集,而无需重新训练。
3D pose datasets: Human3.6M dataset。
Evaluation metrics. 遵循COCO、MPII 和 Human3.6M 数据集的标准评估指标。具体而言,COCO数据集使用基于OKS的AP(平均精度)、AP50和AP75。PCKh(head-normalized probability of correct keypoint)分数用于评估MPII数据集。MPJPE(mean per joint position error)用于评估 Human3.6M 数据集。在四个遮挡数据集上,使用仅在遮挡关节上计算的基于OKS的APOC。
4.2. Implementation details
采用 top-down pipeline。训练过程中使用数据集提供的GT框,测试过程中,使用 SimpleBaseline 为COCO提供的检测结果,对于MPII数据集使用 gt box,遮挡数据集遵循常见做法。
使用在 ImageNet-1k 上用 SimMIM 预训练的Swin Transformer V2 作为 backbone。它也在具有热图监督的COCO数据集上进行训练。为节省计算成本,固定主干,只训练分类头。将基本学习率、权重衰减和 batch size 分别设置为8e-4、0.05和256。在COCO和MPII上训练了 210 个 epoch,在Human3.6M上训练 50个 eoch,使用 flip testing。
使用MMPose 提供的默认数据增强,包括 random scale (0.5, 1.5),random rotation (−40◦, 40◦),random flip (50%),grid dropout and color jitter (h=0.2, s=0.4, c=0.4, b=0.4)。还为COCO数据集额外添加了 half body augmentation。图像大小为256×256。
学习表示过程中,使用 AdamW 优化器,基本学习率分别设置为1e-2和权重衰减为0.15。对500次迭代的学习率进行 warm up,并根据余弦计划降低学习率,batch size 设置为512。2D姿态训练 50个 epoch,3D姿态估计训练20个epoch。
4.3. Results on COCO, MPII and H36M
COCO结果如表1所示:

表2,表7 所示为 MPII 数据集结果:


表3所示为 H36M 数据集结果:

4.4. Results on CrowdPose, OCHuman, SyncOCC
四个遮挡数据集的结果如表4所示,可以看出基于PCT的方法明显优于其他方法。图5为一些定性结果示例。


我们还在完全公平的环境中比较了四种表示,包括坐标、热图、discrete bins 和PCT。结果如表5所示。

4.5. Empirical analysis
Ablation study.

Token number && Codebook size.

5. Conclusion
本工作将结构化表示PCT引入人体姿态估计领域,对身体关节间的依赖性进行建模,并自动学习人体姿态的子结构。我们还在PCT表示的基础上提出了一个非常简单的姿态估计pipeline,无需任何负责的后处理,它在 5 个姿态估计基准上与 sota 方法相比有过之而无不及。离散表示也为与其他离散模态(如文本和语音)的交互开辟了道路。
未来的工作:通过在离散表示下探索其他线索来进一步减少姿态估计中的模糊性,例如,可以从周围物体等环境中对上下文进行建模。
Appendix
More visual illustrations for the sub-structures.
