论文总结
本文没有提出新的方法,主要是探索了信息丢失数据增强手段的应用中存在的问题,以及能带来的提升。
之前的论文要不就是没有使用信息丢失的数据增强手段,要不就是验证了信息丢失手段在姿态检测问题上的失败。本文所做的工作就是发现了之前失败的原因,并提出了对应的解决手段-----增加训练时间周期。BlazePose中也提出了要使用信息丢失的数据增强手段,应该能说明信息丢失的数据增强是有效的。
直观上来说,增加信息丢失的数据增强手段,可以模拟各种身体自遮挡和被物体所遮挡的关键点的检测。
最后,在各种模型各种对应配置(分辨率、网络等)的实践都有提升AP的前提下,作者推荐将信息丢失作为姿态检测问题的常规数据增强手段,就和随机尺度缩放,随机旋转,随机翻转一样。
使用AID的时候,作者提供了两种训练方案:(1)double训练的epoches;(2)分为两个阶段训练:第一个阶段不使用AID,第二阶段加AID进行refine。两种方法的性能差不多。
论文介绍
外观线索和约束线索都是人体姿态检测的重要线索。作者认为,当前的训练方式,会让模型过拟合外观线索,而几乎不咋能拟合约束线索,所以导致不可见关键点的预测不好。外观线索,直观上就是没有遮挡的人的身体结构;约束线索,直观上就是各种人体结构信息啥的。而在被遮挡的情况下,外观线索丢失,约束线索就十分重要。所以作者引入信息丢失来迫使网络去学习约束线索。
尽管AID在理论上的目的是学习更多的约束信息,但如果使用和之前一样的训练方案,则几乎不会产生作用,甚至产生负作用。通过对loss和模型性能的观察,AID会使得训练变得具有挑战性。作者发现如果早期训练的时候不使用AID会有一个从易到难的过程,所以作者对应产生了两套应用AID的训练方案。
应用AID训练的loss是一定会比不应用AID的方案要高的。若直接应用AID进行训练,会造成早期训练过程中姿态检测器的性能下降,在后面会慢慢跟上,所以训练AID会需要更长的周期。作者提供了两种训练方案:(1)double训练的epoches;(2)分为两个阶段训练:第一个阶段不使用AID,第二阶段加AID进行refine。两种方法的性能差不多。
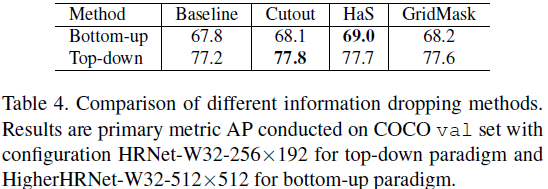
初步实验展示:对于top-down模型,CutOut带来的提升是最高的;对于bottom-up模型,则是HaS(多个区域,给概率丢失)。
实验结果
使用coco训练集的自己作为训练集,一共57k张训练图片,150k个人体实例。使用HTC作为top-down的检测器,其在80类的AP为52.9,对于human来说,AP为65.1.
COCO
在val的效果如下表所示:可以看出,使用AID在bottom-up和top-down的不同模型,不同分辨率上都有提升,大致都在0.6AP左右。如果将val分为可见关键点和不可见关键点两个子集,则从下表可以看出,AID不仅对不可见关键点的检测有提升,对可见关键点的检测也有提升。
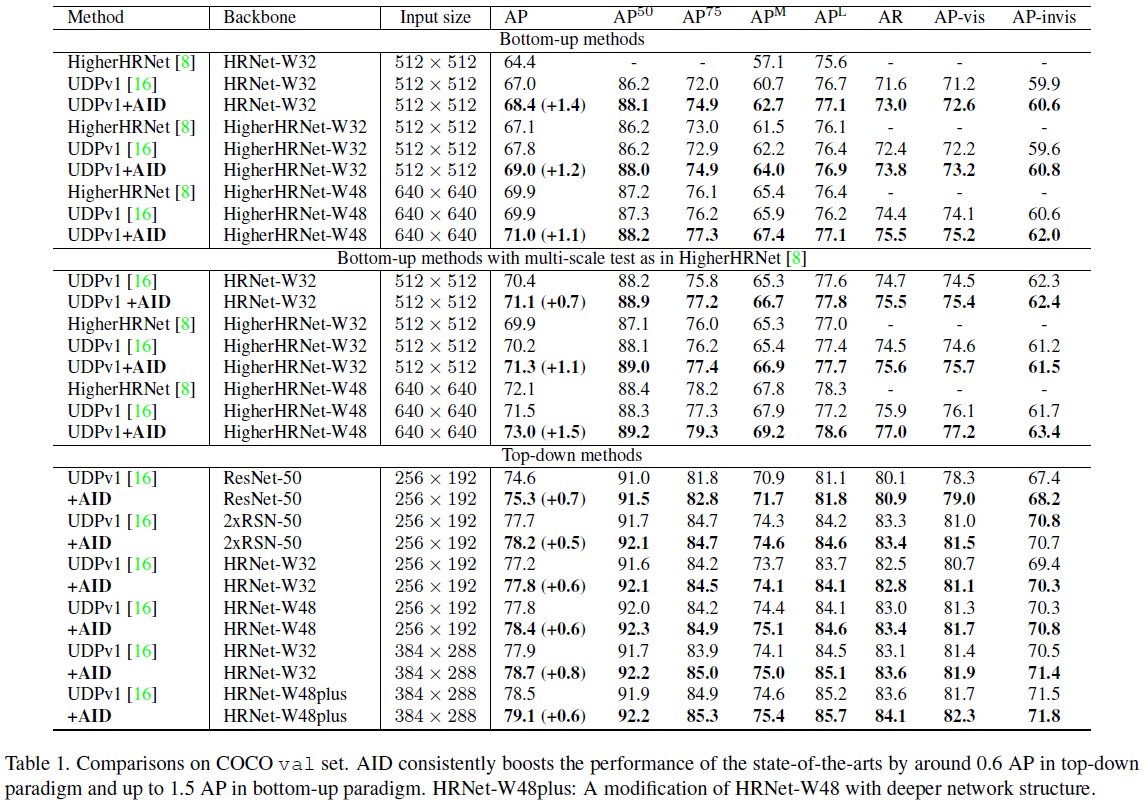
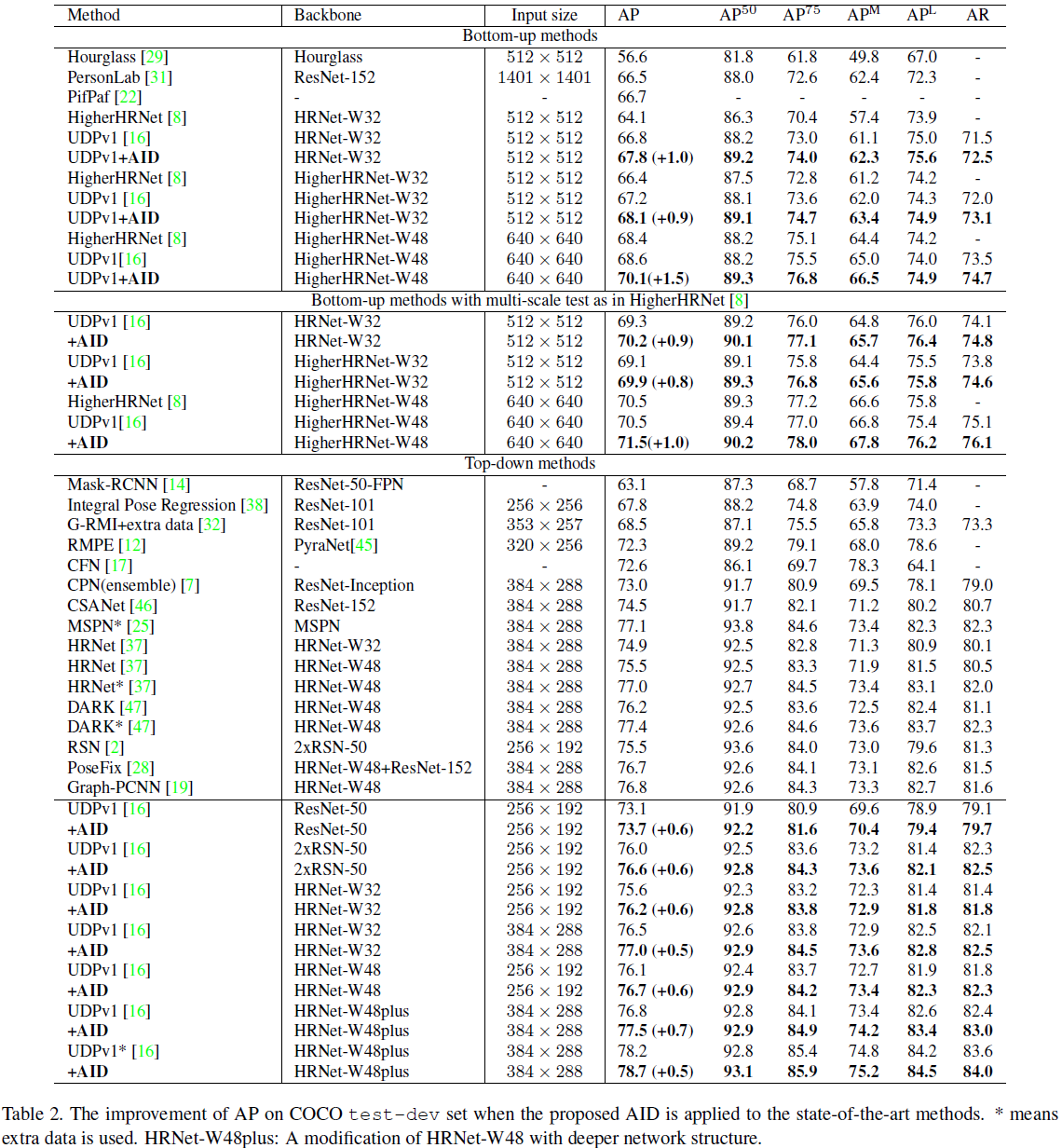
在test-dev上的效果如下表所示:其中 ∗ * ∗表示使用了额外数据AI Challenger。使用额外数据,原模型78.2AP已经很高了,但使用AID时候仍增加了0.5AP,到了78.7AP。这表明使用更多数据训练的模型能有效提高模型性能,但仍不能解决过拟合问题。AID仍是有效的方案。
CrowdPose
在CrowdPose的结果如下表所示:以HigherHRNet作为baseline。

消融学习
探索了Cutout、HaS和GridMask的实验。在数据增强上,超参数的设定是十分重要的。为了让几种方法具有可比性,作者让初始loss尽可能接近,以尽可能减少超参数的影响。最终得到了两个总结:(a)不同的信息丢失方案在bottom-up中的性能不同,但在top-down中是相近的;(b)HaS对于bottom-up是最好的,而Cutout对于top-down是最好的。实验结果如下图所示:
训练方案的消融学习实验
使用的模型为HRNet-W32-256x192,使用的是Ground-truth human boxes,探索使用AID时训练方案的影响。有三种方案:(1)和HRNet一样的训练方案,初始学习率为1e-3,然后在170个epochs掉到1e-4,在200个epochs时掉到1e-5,一共210个epochs;(2)两倍于(1)的训练周期,分别在380个和410个epochs时降学习率;(3)重复(1)的实验,但两次实验第一次不使用AID,第二次使用AID。
有不同的时间长度,故有五个实验进行:

表现和损失值如下图所示:E1和E2使用的训练方案都是S1,区别在于是否使用了AID,使用AID时的损失更高。在早期训练过程中,E2表现比E1差,说明在早期的训练过程中,外观信息是至关重要的,辅助会干扰对外观特征的研究。但E1和E2在训练结束的时候模型性能是相似的,这表明在原始的训练方案中,AID是不会产生正面的影响的。比较E3和E4,E4在250个epoch时开始超过E3,而优势在后期训练中越来越大。

论文中模型的性能展示
下图中,左边是ground-truth,中间是加了AID训练的模型,右边是baseline模型。
