论文地址:https://paperswithcode.com/paper/bottom-up-human-pose-estimation-by-ranking
代码地址:https://github.com/HRNet/HRNet-Bottom-up-Pose-Estimation
论文总结
本文方法是Bottom-Up方法的一员,其主要研究方向就是在将离散点Grouping成候选姿态的人,同时训练一个较小的OKS评分网络,对候选姿态进行评分。
即论文方法有两个分支:Point Heatmap预测离散的点,GroupIng Cue分支有一个中心点的Center map及其对应的Offset。Offset是对应该中心点的的,是相对偏移,用于将一组离散点联系起来。这种grouping 方法,作者称为pixel-wise keypoint regression。作者认为这种表达方式可以有效处理姿态检测中scale and orientation variance.
训练小的OKS评分网络时,输入有Heatmap的预测(17个点的heatmap value),每一对连接的keypoint之间的关系(19对)。关系有距离Distance( 19 ∗ 1 19 * 1 19∗1),有Offset( 19 ∗ 2 19 * 2 19∗2),即网络的输入是74维的。作者将Keypoint的关系称为姿态的shape。即评分的小网络输入是heatmap value and shape。
论文方法
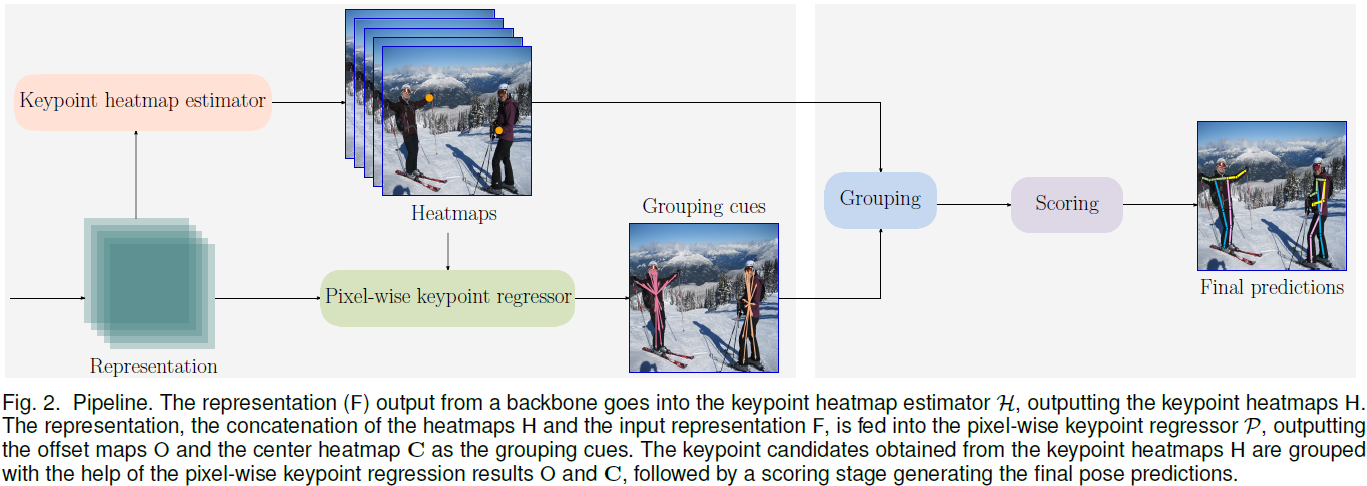
以一张图片作为输入,输出含有两个部分:(1)Keypoint Heatmaps;(2)Pixel-wise Keypoint regression results。Keypoint Heatmaps H 就是最基本的K个关键点的Heatmap。Pixel-wise Keypoint regression results由两个部分组成:(1)Center Heatmap C,表示某个position是一个pose的可信度;(2)Offset maps O,包含2K maps,表示如果该位置确定为是一个pose的中心点,则表达出每个keypoint到中心点的Offset。Groupint分支的输入是feature map和heatmap的concat。
Adaptive representation transformation
为了解决scale和orientation variance(不同的人在图片中开源有不同的大小和方向),作者提出一个adaptive representation transformation(ART) unit。具体看代码,就是从普通卷积中修改而来。该小节中的T是由feature map reshape而来,通过卷积得到一个channel为4的feature map,再将channel reshape成 2 ∗ 2 2*2 2∗2的维度与G进行计算。
通过骨干网络后,预测heatmap的head和group的heatmap都使用两个ART unit。
Loss function
heatmap的损失:

⊙ \odot ⊙是elemet-wise product, ∥ ∙ ∥ \| \bullet \| ∥∙∥是2范数,即 ∥ X ∥ 2 = ∑ i x i 2 \| X \|_2=\sqrt{\sum_{i}x_i^2} ∥X∥2=∑ixi2, M k M_k Mk定义为不在第k个关键点区域的为0.1,在的为1,形状为 H ∗ W ∗ K H*W*K H∗W∗K。实际上也就是带权重的MSE,用以平衡大量的非关键点map位置与少量的关键点位置。
pixel-wse keypoint regression 的损失采用smooth loss:其中offset部分,以bbox的对角线长度的导数作为权重,大致是越大的边框,其偏差的重要性就越低;

其中 Z i = H i 2 + W i 2 Z_i=\sqrt{H_i^2+W_i^2} Zi=Hi2+Wi2, H i , W i H_i,W_i Hi,Wi是bbox 的高和宽, C ∗ C^* C∗是groundtruth center heatmap.
最后的损失为:

其中 λ = 0.01 \lambda=0.01 λ=0.01,作者认为pixel-wise keypoint regression只提供作为groupint cur,所以较小权重。
Training data construction
Heatmap groundtruth H ∗ H^* H∗仍采用高斯核函数处理;offset maps groundtruth和center heatmap groundtruth依据对应的pose坐标进行处理:(1)确定各个坐标的中心点 p n ˉ = 1 K ∑ k = 1 K p n k \bar{p_n}=\frac1K\sum_{k=1}^Kp_{n_k} pnˉ=K1∑k=1Kpnk;(2)确定对应的offsets τ n = { p n 1 − p n ˉ , p n 2 − p n ˉ , ⋅ ⋅ ⋅ , p n k − p n ˉ } \tau_n=\{ p_{n_1}-\bar{p_n}, p_{n_2}-\bar{p_n}, \cdot\cdot\cdot, p_{n_k}-\bar{p_n} \} τn={ pn1−pnˉ,pn2−pnˉ,⋅⋅⋅,pnk−pnˉ}。即offset是对应“根结点”的偏移表示。设置offset maps时,在半径为4的范围内都设中心点和对应的offset。
Inference
给定输入 I I I,通过网络,得到 H H H和 ( C , O ) (C, O) (C,O)。在Heatmaps H H H上,通过NMS在每个关键点的heatmap上找到30个最大的点,在通过阈值(文中为 0.01 0.01 0.01)进行filters,得到每个Keypoint的候选集 S = { S 1 , S 2 , ⋅ ⋅ ⋅ , S K } S=\{ S_1, S_2, \cdot\cdot\cdot,S_K \} S={ S1,S2,⋅⋅⋅,SK}。对于pixel-wise keypoint regression 分支也是如此,得到候选pose 集 ϱ \varrho ϱ。
对于每个 ϱ \varrho ϱ中的点 p k p_k pk (offset中),选取 S k S_k Sk中距离最近的点(文中是在75个像素以内),否则直接使用 p k p_k pk作为位置展示。
Scoring
原始的score方案为heatmap value与center heatmap的value的共同结果,但这没考虑到空间信息的作用:

作者采用学习一个小网络(两个全连接层,ReLU和一个线性预测层),去预测OKS分数。小网络的输入为shape特征和heatmap特征,最终得到候选pose的分数。shape特征为COCO数据集中17个点对应的19个连接线的距离(distance)和向量(offset),heatmap特征是heatmap对应的value,一共有 19 + 19 ∗ 2 + 17 = 74 19+19*2+17=74 19+19∗2+17=74个维度的特征。