
一、本文想要解决的问题
1、提高精度
2、尽量解决因为“遮挡” ,“画面中其他人物关节的干扰”、“杂乱的背景” 导致的错误

二、提出的方案
1、Deeply Learned Compositional Model (DLCM)
2、spatially local information summarization (SLIS)
3、 use bone segments to represent a part and supervise its score map in the training phase (骨骼分割 这个新的表征,涵盖了方向、尺度、以及轮廓,“对于传统的做结构的人体姿态估计来说,还降低了计算量和复杂度”)
三、文章的主要贡献
1、DLCM
2、bone based representation
3、结构化的网络结构,消除了一些bottom-up的歧义。。。,在这个结构里,既有Bottom-up 也有top-down,当然和平常姿态估计中的不一样。
四、详细介绍
compositional model:

![]()
![]() 代表了节点的状态,其中包含了p代表坐标,t代表状态(如,方向)这个概念来自于传统的tree structure。总的score function设计的目的就是,去最大化对于某一张图像I的所有关节点在各自某状态下得分最高,且他们的组合得分也高。
代表了节点的状态,其中包含了p代表坐标,t代表状态(如,方向)这个概念来自于传统的tree structure。总的score function设计的目的就是,去最大化对于某一张图像I的所有关节点在各自某状态下得分最高,且他们的组合得分也高。

第一个公式是叶子节点的得分计算;第二个公式是,比如父节点为右肩膀,候选的右肘有3个,那么我们需要从这3个右肘中找出得分最大的,然后如果右肩膀还有其他可选子关键的链接,比如右臀部,那么就把“右肩膀-右肘”+“右肩膀-右臀”。
Top-Down过程

Spatially local information summarization:
对于非 root节点
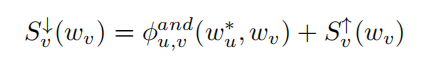


以上这些公式都是用于理解这个思路的,具体到CNN中如何去实现,就得看下面的内容了:
Model SLIS functions with CNNs.:

