参考文献:
[1] Voice Conversion (1/2)哔哩哔哩bilibili
[2] 2020 年 3月 新番 李宏毅 人类语言处理 独家笔记 Voice Conversion - 10 - 知乎 (zhihu.com)
[3] Voice Conversion (2/2)哔哩哔哩bilibili
[4] 2020 年 3月 新番 李宏毅 人类语言处理 独家笔记 StarGAN in VC - 11 - 知乎 (zhihu.com)
[5] 台大教授 李宏毅 Flow-based Generative Model哔哩哔哩bilibili
本次省略所有引用论文
目录
一、Voice Conversion介绍
-
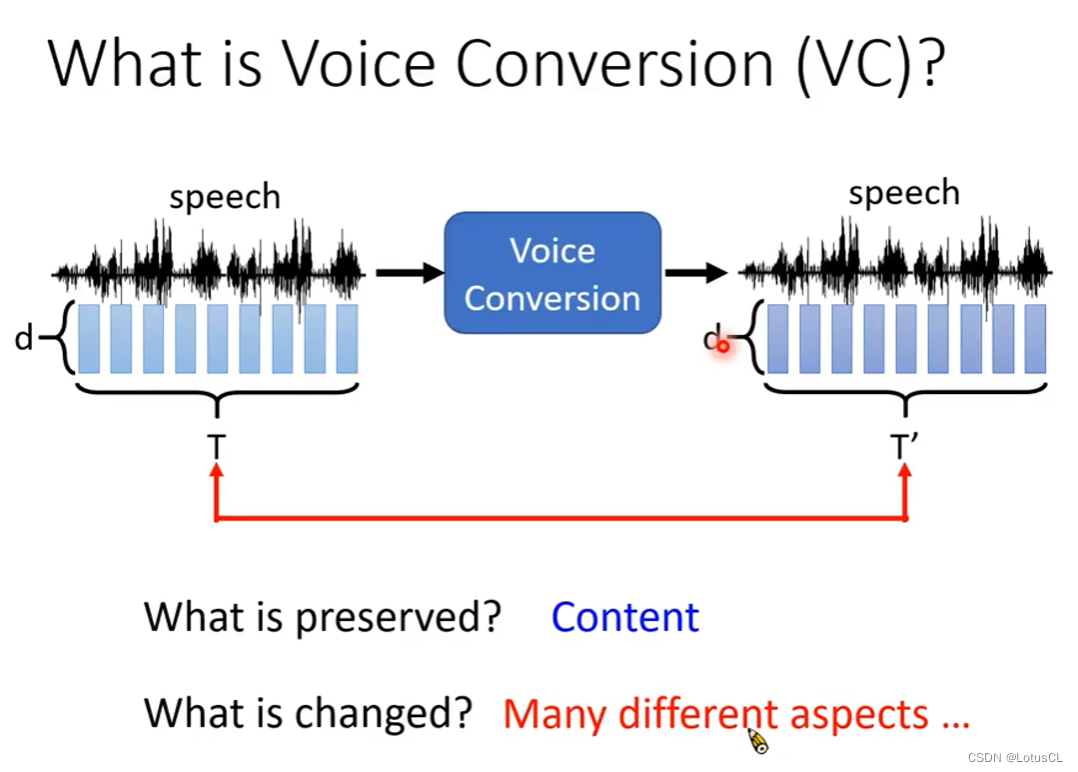
VC 任务是什么:
-
输入一段声音,输出另一段声音。
-
输出的声音在内容上与输入一样,但音色发生了变化。
-
就像是柯南的领结变声器。
-
-
用处是什么(必要性)
-
改变 Speaker:
-
不同人说相同的内容效果不一样
-
可以愚弄人
-
可以制作 Personalized TTS(Text-to-Speech),也就是个人化的语音合成系统
-
还可以转换歌声
-
可以保障个人隐私(变声)
-
-
改变 Speaking Style:
-
讲话的情绪变化
-
让声音变得正常(Normal-to-Lombard),Lombard语音是一种嘈杂环境下人们通常使用的语音风格,它通常比普通语音更加清晰、响亮、带有更多的高频成分,并且更易于在嘈杂的环境中被听到和理解。
-
悄悄话和正常语音互相转换(Whisper-to-Normal)
-
歌者声音技巧转换(Singers vocal technique conversion),如加入弹唇和颤音
-
-
可以增强 Intelligibility(可理解性)
-
把一般人不是容易理解的声音,转换成容易理解的声音。这样可以帮助那些有发声器官损伤的人们
-
可以做口音矫正转换,或者用在语言学习上,将别人口语教学转为你自己的声音
-
-
可以做Data Augmentation(数据增强)
-
把男女声互相转换,来让语音识别的训练集变得多样化。
-
把干净的声音来转换成有噪音的声音,来增强语音识别系统的鲁棒性。或者把有噪声的声音进行去噪,来提高语音辨识系统的能力
-
-
二、出发点(需要解决的问题)
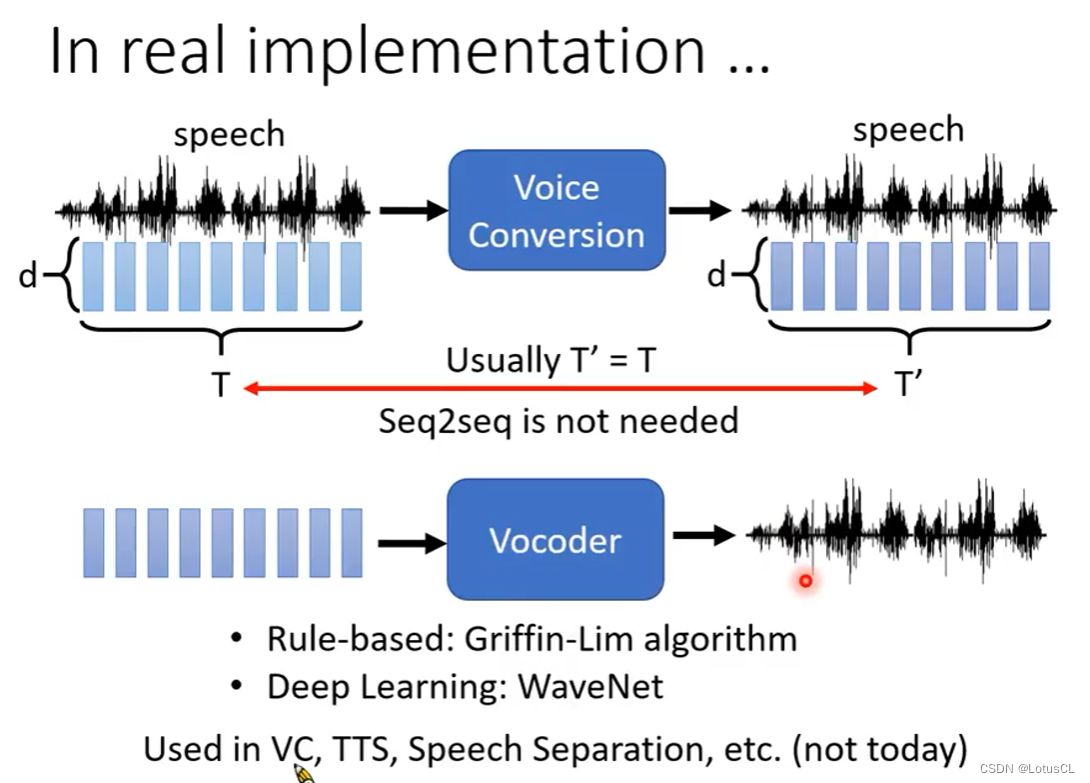
在实际部署的时候,我们通常会有两个重要问题:
-
实际实现中,VC 的输入和输出序列的长度可以是不一样的。如果长度不一样,那么我们就需要使用Seq2Seq模型,但很多文献会去假设输入和输出的长度是一样的。这样就可以用一些比较简单的模型去做。
-
以及在使用声音模型的时候,我们通常使用的都是Acoustic Features,也就是一串向量,然而在实际使用时,我们最后需要得到的是一个音频,如何将向量转为音频也需要一定的技术(通过Vocoder)来进行实现。
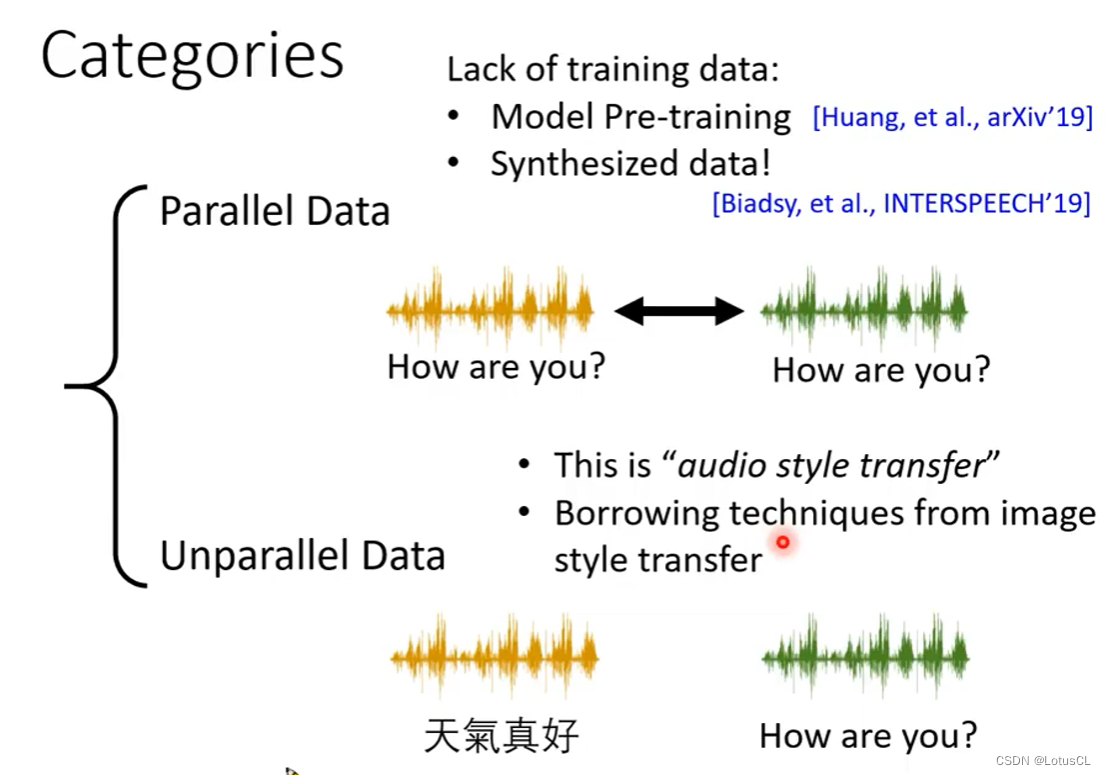
三、语料库的分类
-
Parallel Data:成对的语音资料,此时有多个语者都念的同一句话。但这样的数据实在太少,我们可以通过:
-
Model Pre-training:采用一个预训练的 Seq2Seq 模型,然后使用少量的成对语音资料进行 fine-tuning(模型微调)
-
Synthesized data:即使用合成语音,如在知道语料库的内容后,可以将内容给到谷歌语音,并合成出谷歌小姐的声音,这样就有了更多成对语音
-
-
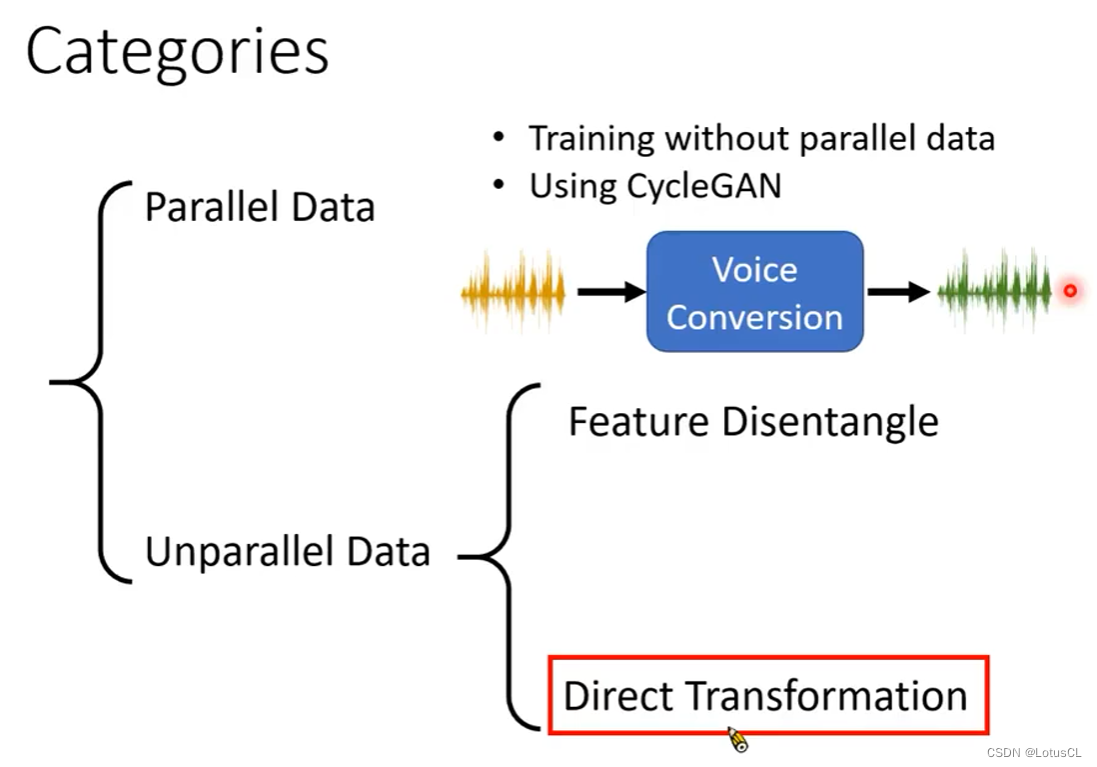
Unparallel Data:不成对语音,有多个语者,但他们念的话语可能不尽相同,甚至连语言都可以是不同的
-
实际上,这个任务可以叫做 “audio style transfer”,类比image style transfer
-
我们可以从image style transfer中偷取一些技术来使用。大致有两个方向:Feature Disentangle 和 Direct Transformation
-
四、具体实现技术(Unparallel Data)
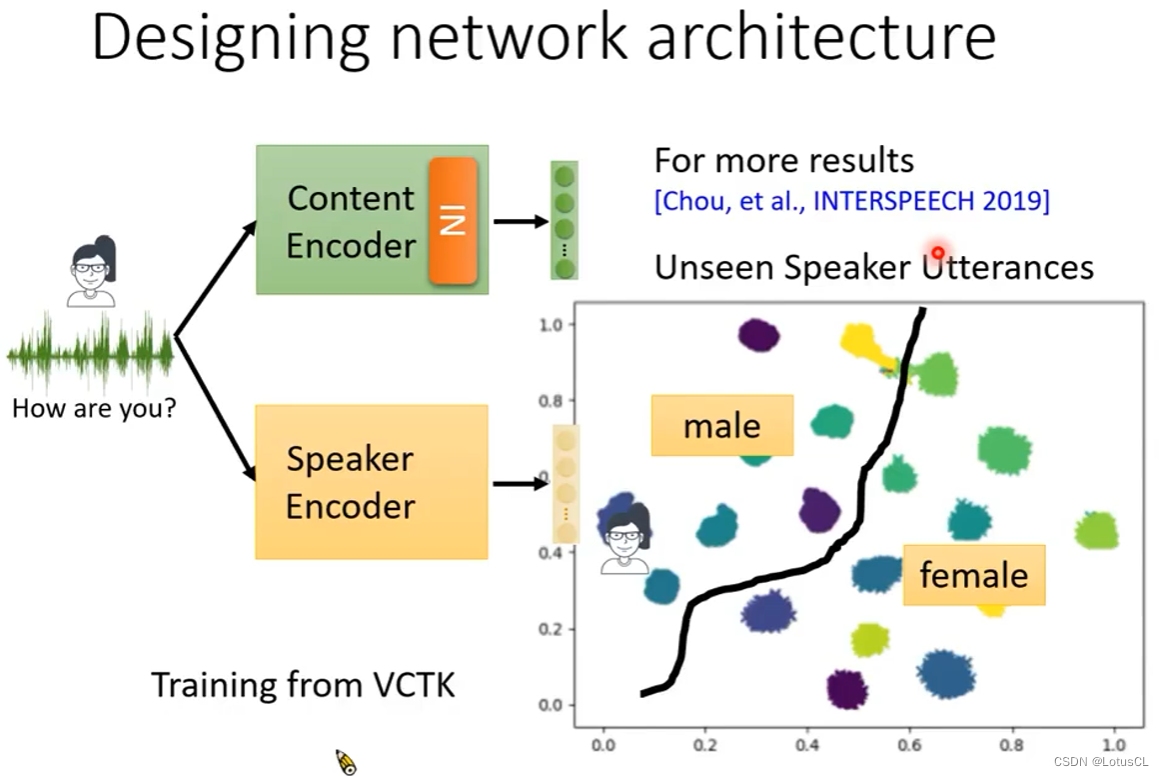
我们首先考虑不成对语音研究方向,具体可以分为分解和直接转换两种思路。下面这张图给出了分解,也就是Feature Disentangle的大致思路。
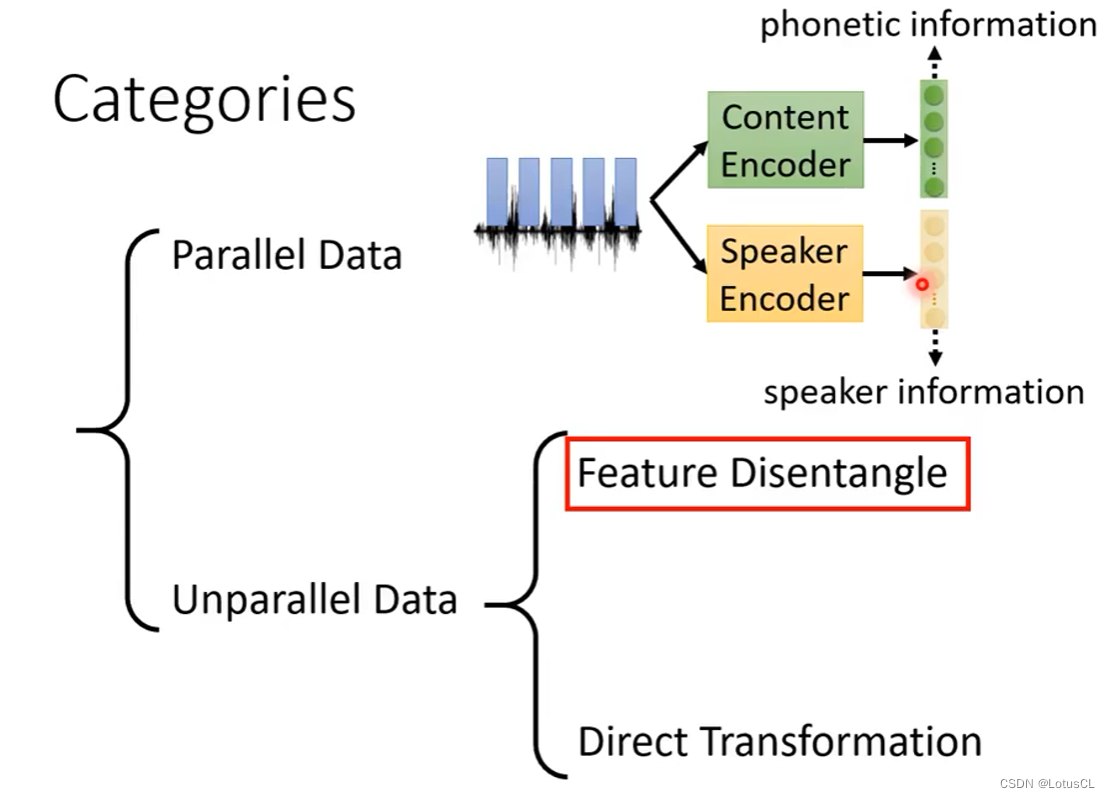
Feature Disentangle(特征解缠)
语音中实际上包含了很多信息,如文字信息,语者信息,环境信息,情绪信息等,如果需要替换Speaker,只需要替换其中的语者信息就可以。这个技术也可以用在除切换Speaker以外的地方,比如情绪转换。
-
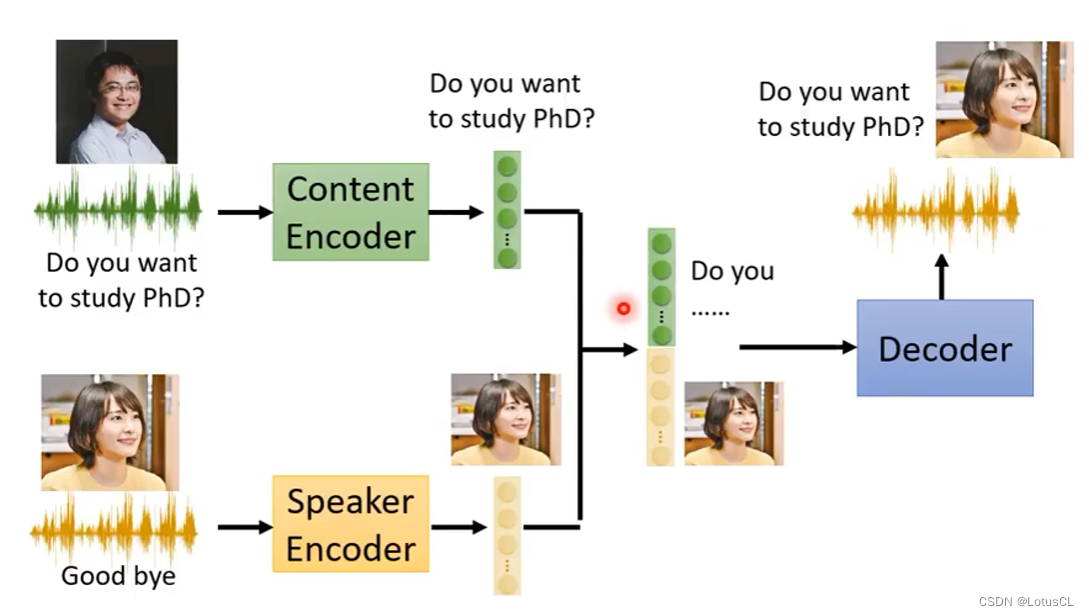
我们可以训练两个Encoder,分别可以提取内容信息和语者信息,然后再训练一个Decoder,能够将两个信息融合起来。

-
如此一来,完成训练后,我们只需要给Speaker Encoder提供其他语者的语音素材,然后进行融合即可。
-
问题来了,训练的目标是让解码器融合的输出更接近输入,但我们该如何让两个编码器乖乖听话,一个能提取内容信息,一个能提取语者信息呢?
-
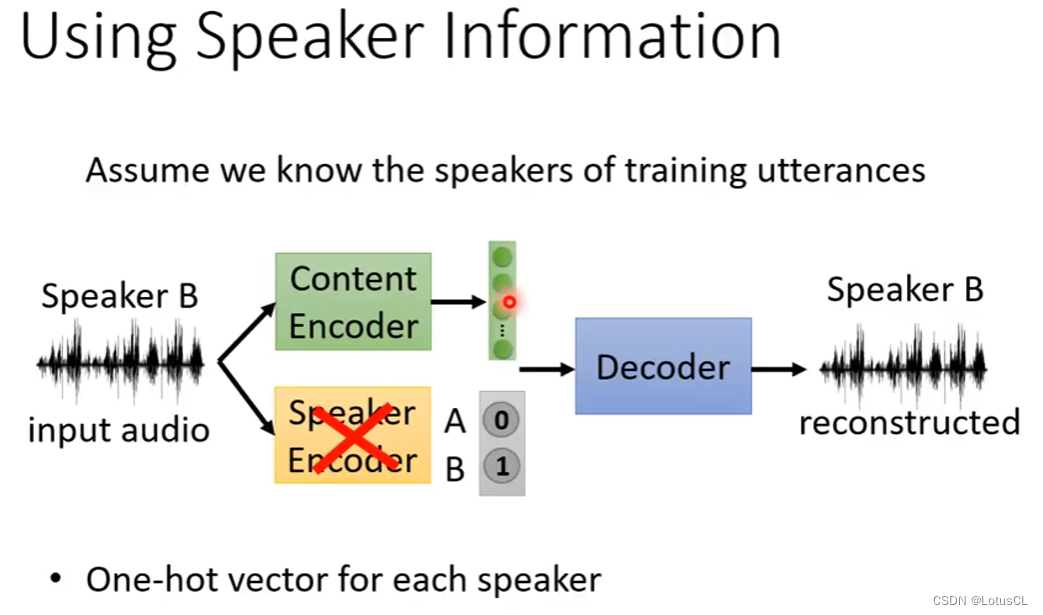
一个简单的方法是不再使用Speaker Encoder,而是改成使用独热向量来表示语者,但是这样做的坏处也很明显,不能合成新的语者的声音。因为在训练前,独热向量的维度就已经确定为数据中包含的语者的数量,而一旦需要加入新的语者,那么整个Decoder就需要重新训练。
-
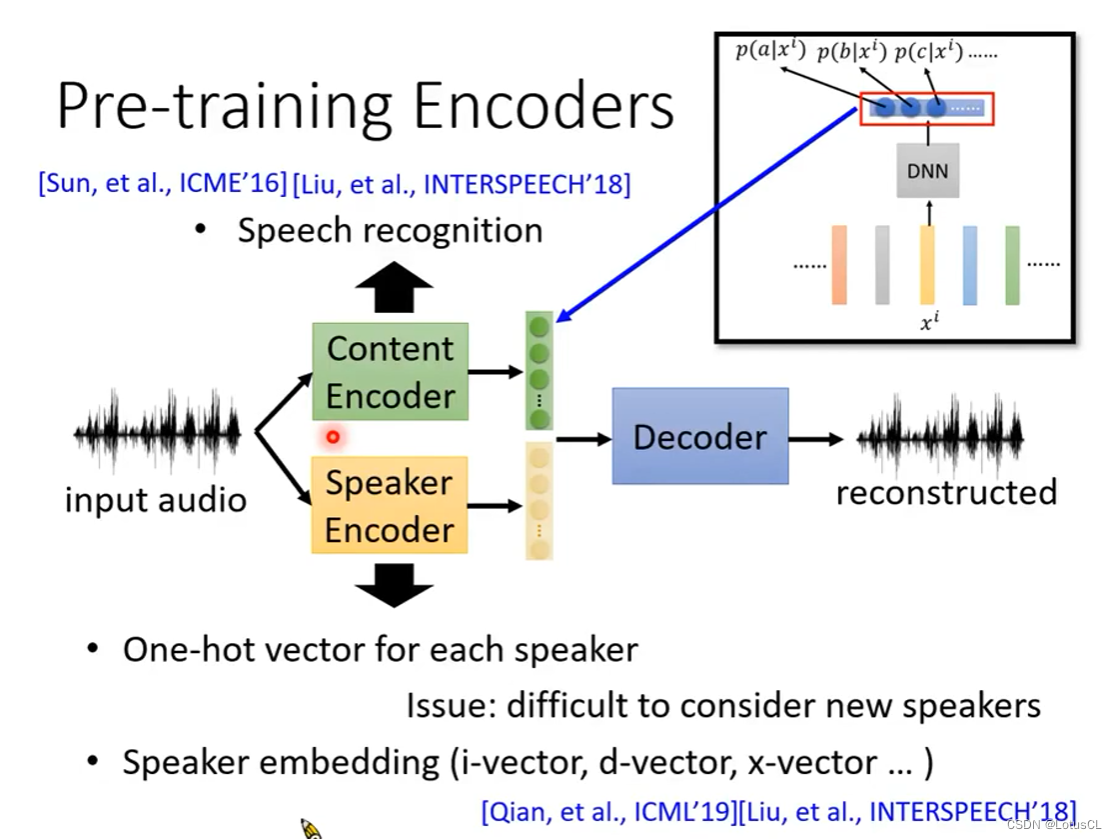
所以我们重新采用Speaker Encoder来对语者信息进行提取。已经有很多预训练好的模型,可以生成Speaker Embedding。
-
那么Content Encoder应该怎么处理呢?一个直接的办法是采用Speech Recognition(语音识别),还有就是像图中所说,采用HMM加入的神经网络,这个深度神经网络输出的是HMM的发射矩阵,自然可以当做Content Encoder。
-
还有一些其他的想法,比如去模仿GAN(Generative Adversarial Network,生成式对抗网络),将Content Encoder的输出内容直接取出,放入一个判别器(Speaker Classifier)中,而判别器的任务就是判断这个语音是哪个语者说的。而Content Encoder作为生成器的目标就是能愚弄判别器,让它无法识别出语者信息,这样就能让Content Encoder去除所有语者信息。在训练时,二者交替训练即可。
GAN,全称为生成对抗网络(Generative Adversarial Network),是一种深度学习模型,由一个生成器(Generator)和一个判别器(Discriminator)组成。GAN 的目标是通过生成器和判别器的对抗博弈来学习数据的分布,并生成与真实数据相似的合成数据。
生成器的作用是将输入的随机噪声信号转换为合成数据样本,而判别器则负责评估输入的数据样本是真实数据还是生成器产生的合成数据。二者通过反复的对抗训练过程不断互相优化,从而达到生成逼真的合成数据的目的。
GAN的训练过程可以简要概括如下:
-
生成器接收一个随机向量作为输入,并通过一系列的神经网络层进行映射和变换,最终生成一份合成的数据样本。
-
判别器同时接收真实数据和生成器生成的合成数据作为输入,通过一系列的神经网络层对其进行评估,并输出一个概率值来表示输入数据是真实数据的可能性。
-
生成器和判别器交替训练。首先,固定生成器,通过最小化判别器对真实数据的误判概率和对生成器生成数据的误判概率来更新判别器的参数。然后,固定判别器,通过最大化判别器对生成器生成数据的误判概率来更新生成器的参数。
-
重复进行步骤3,直到生成器和判别器达到一种平衡状态,生成器能够生成逼真的合成数据,而判别器无法准确区分真实数据和生成数据。

-
-
除此之外,我们也可以通过设计网络架构,来让两个Encoder去乖乖完成自己的工作。技术源自于Image style transfer,将Instance normalization加入到Content Encoder中,就可以去除语者信息。
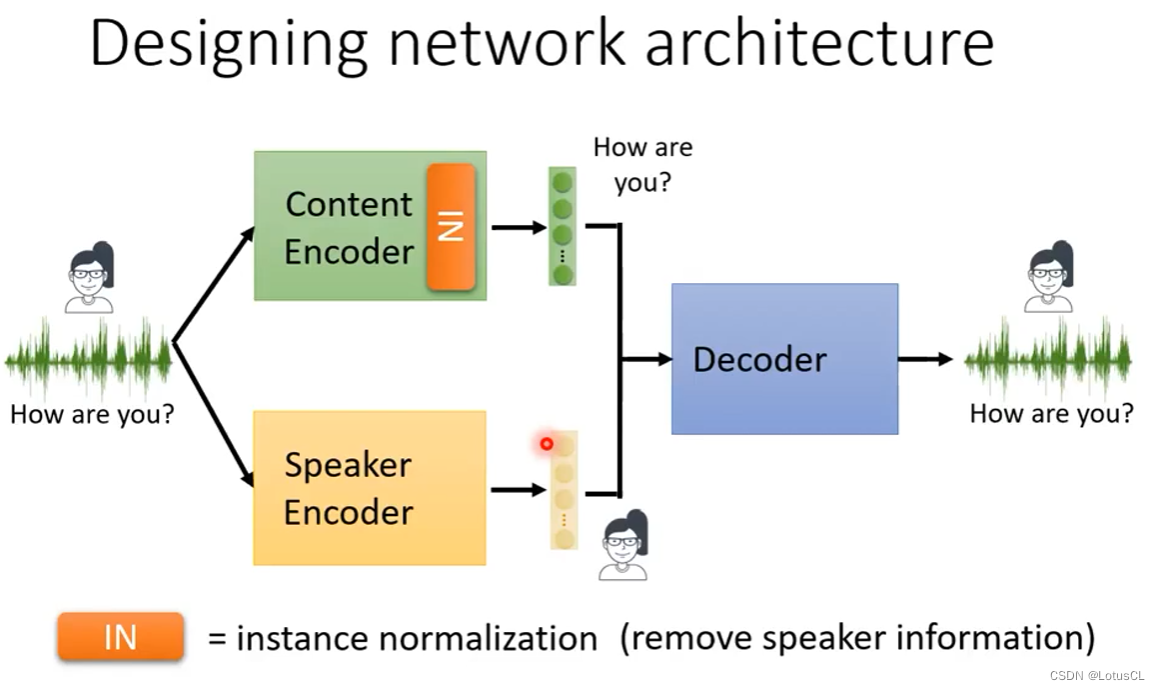
-
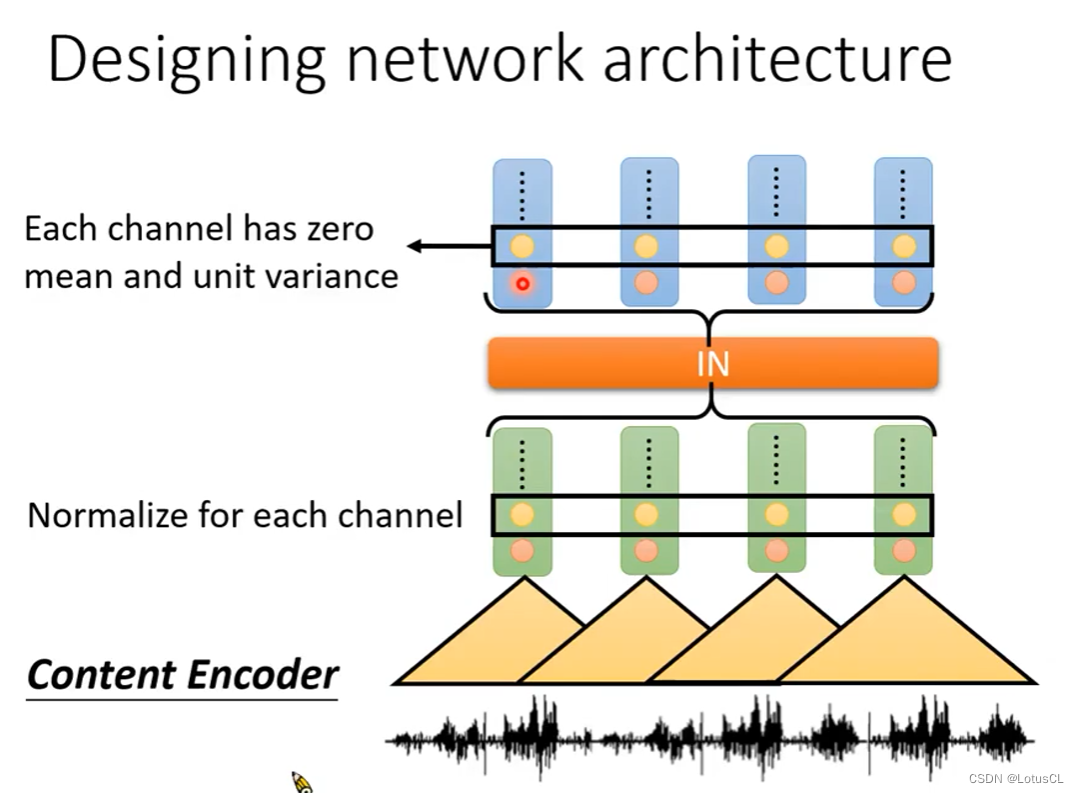
IN是怎么做到这个事情的?其本身是作用在Encoder中,filter采集完声波信息生成的向量序列(vector sequence)上的,也就是将vector sequence的每一个维度计算平均值(mean)和方差(variance)进行归一化(normalization)。对于Conv1D而言,每一个滤波器,相当于在捕捉每一种 Pattern 。所以它每一个 row 都代表了声音信号中的每一种特征有没有出现。简单地说,有一些滤波器捕捉高频特征,有些则捕捉低频特征。男声进来,低频的滤波器输出就会比较大,而高频的输出会比较小。女声进来,则反过来。但我们通过这个归一化的方法,让所有的滤波器输出的均值都是0,方差是1。这就相当于是把人声的特质给去掉了。因为被归一化后的滤波器,没有输出值会特别大,就彰显不出说话者的特质信息。
-
实际上,将Encoder的Embedding加入进Decoder的方式有很多,可以自己钻研钻研。
-
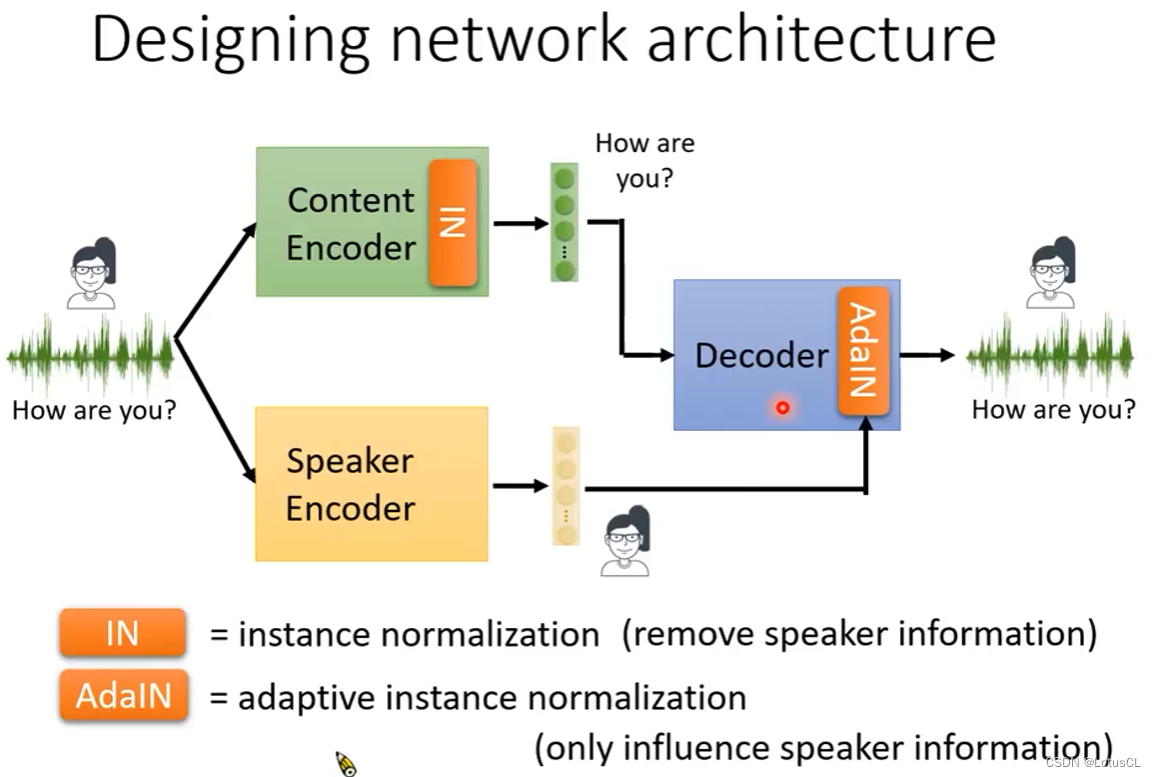
Content Encoder的网络架构解决了,那么Speaker Encoder呢?就是在Decoder中加入AdaIN(Adaptive Instance Normalization),使用它来将Speaker Encoder的输出作为输入添加进解码器中,这样就能使得这一份的输入只能影响到音色,而不会影响到说话内容。
-
AdaIN 是怎么做到的?在解码器中,我们也会有一个IN,来把解码器输出的每个 row 做归一化来去除说话者特质的信息。语者信息则需要结合Speaker Encoder的信息。Speaker Encoder的输出通过两个transform可以得到 γ 和 β 两个向量。假如做完 IN 之后的隐层嵌入为 Z1-Z4,我们就把这些隐层嵌入乘上 γ (即scaling操作)再 加上 β (即shift操作)得到 Z`。这步操作叫作 Add Global。也就是说,γ 和 β 对解码器的输出是全局的。而 IN 和 Add Global 整个合起来就是我们刚刚所说的 AdaIN。我们端对端地训了下去,就结束了。

-
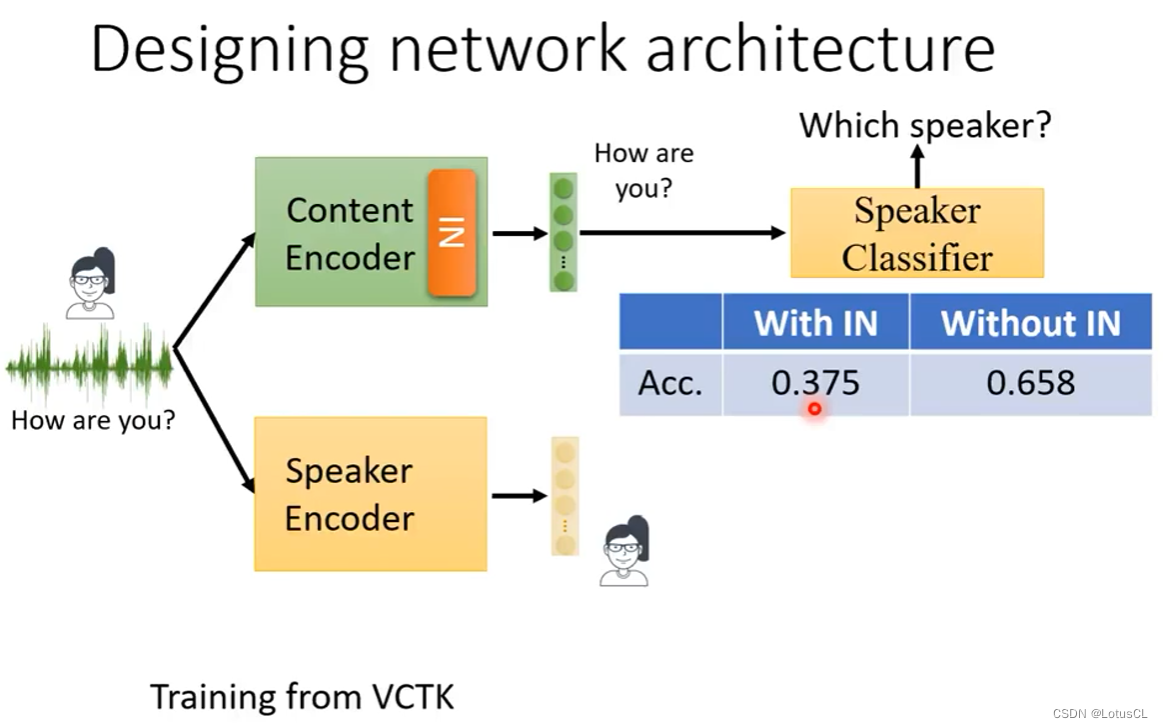
那么通过去设计网络架构的方法有没有作用呢,答案是有的,我们用一个训练好的语者判别器去判断Content Encoder的输出为那个语者,事实证明有IN相对于没有IN,判别器的准确率确实会下降。而我们对Speaker Encoder的输出的嵌入做一个可视化聚类,会发现它确实将不同语者的声音都进行了分辨(图中不同颜色代表不同的语者),并且也有男性女性的明显界限,证明效果还不错。
Feature Disentangle(特征解缠)改进
-
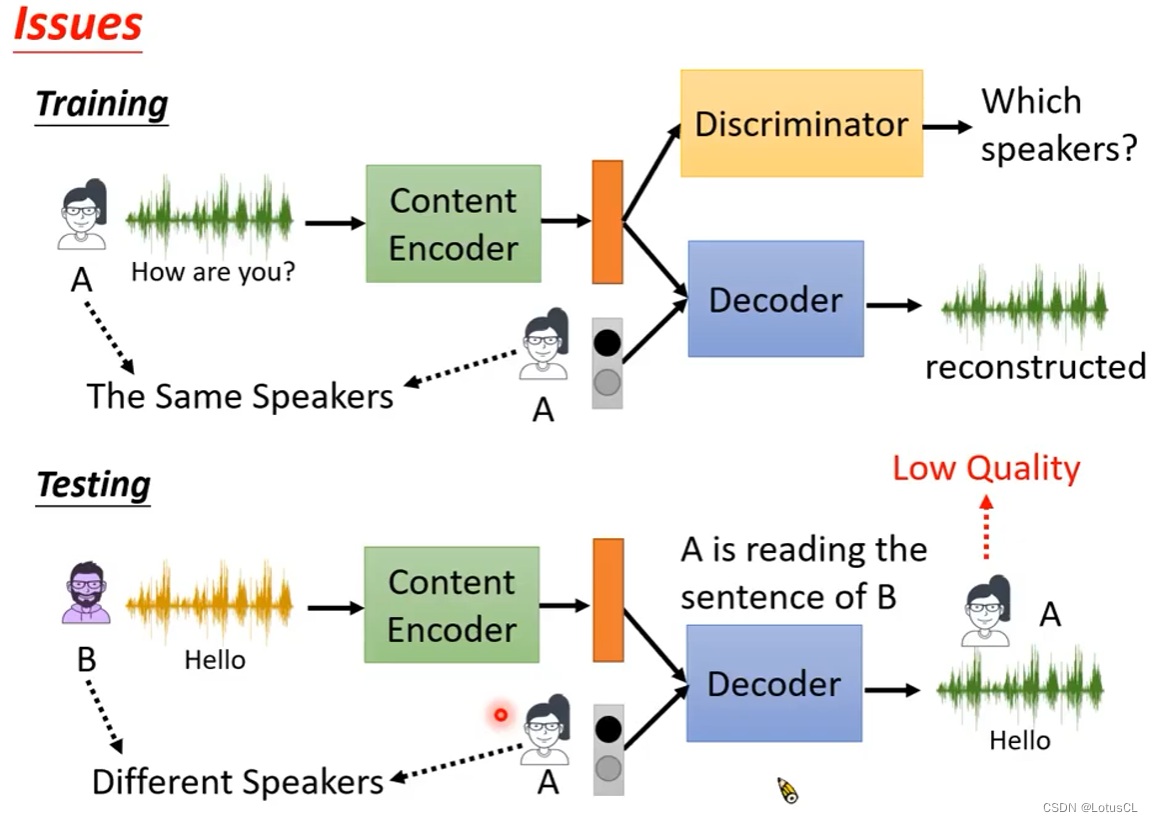
然而,我们回到 Feature Disentangle,我们现在了解到这个其实就类似于Auto Encoder。但它最终输出的声音有时候并不尽如人意。其中一个原因是,在训练过程中,我们一直喂的是同一个人的语音,模型根本不知道我们要做Voice Conversion,也就是会替换Speaker的音色。训练和推理过程不同,就会导致最终效果不好。
-
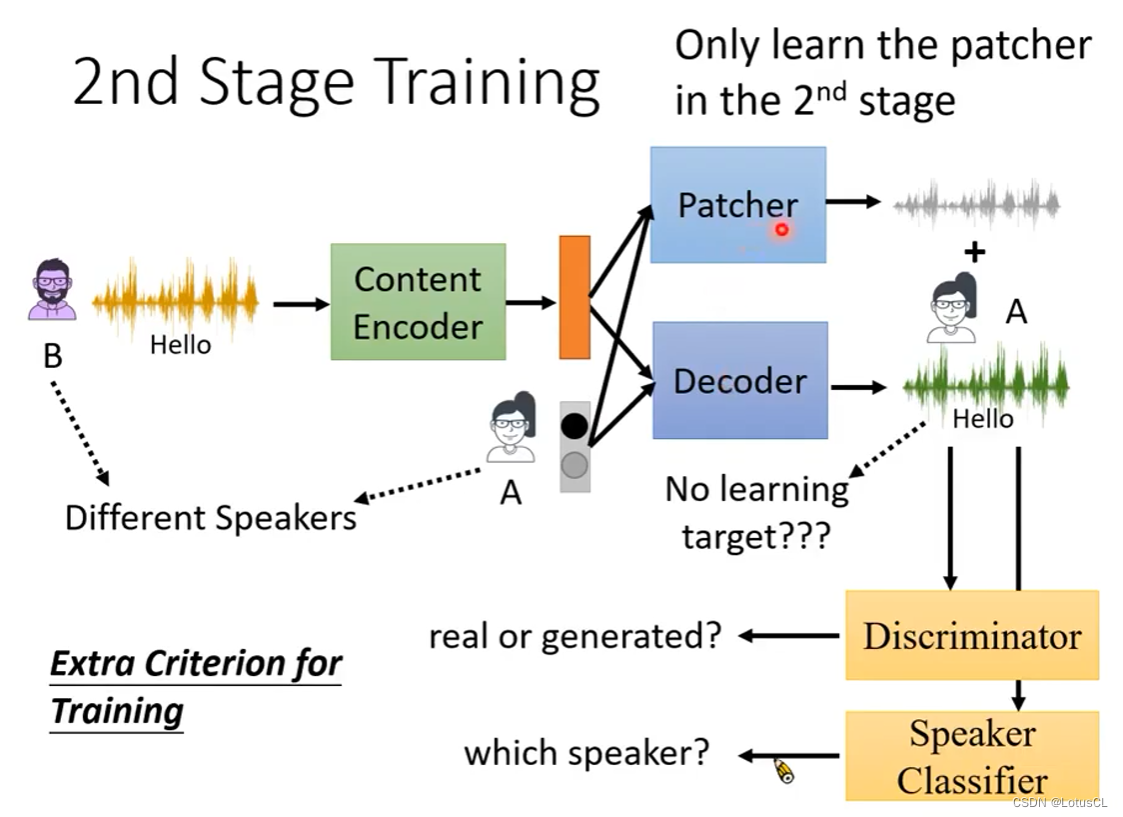
如何解决这个问题?最符合逻辑的考虑是在训练时将不同Speaker Encoder的输出内容加进来,也就是我们要进行 2nd Stage Training,但问题是没有训练的目标。所以我们考虑再次借助GAN:
-
训练一个Discriminator,去区分输出语音是否为真人讲话。
-
再进一步我们可以训练一个Speaker Classifier,让输出尽量靠近一个人的声音(得到一个正确的结果)
-
-
具体应用中,如果你直接去更新Decoder的参数来骗过两个判别器,训练很容易崩溃。所以我们采用额外训练一个Patcher,它也是和Decoder有一样的输入,不同的是它的输出最终会和Decoder的输出相加,将结果拿去骗判别器,这样训练会比较稳定。
Direct Transformation(直接转换)
-
这类做法简单粗暴,直接训练一个模型,输入A的声音,直接输出B的声音。下面这个图中介绍的就是技术之一——从图像风格转换技术迁移过来的 CycleGAN 。
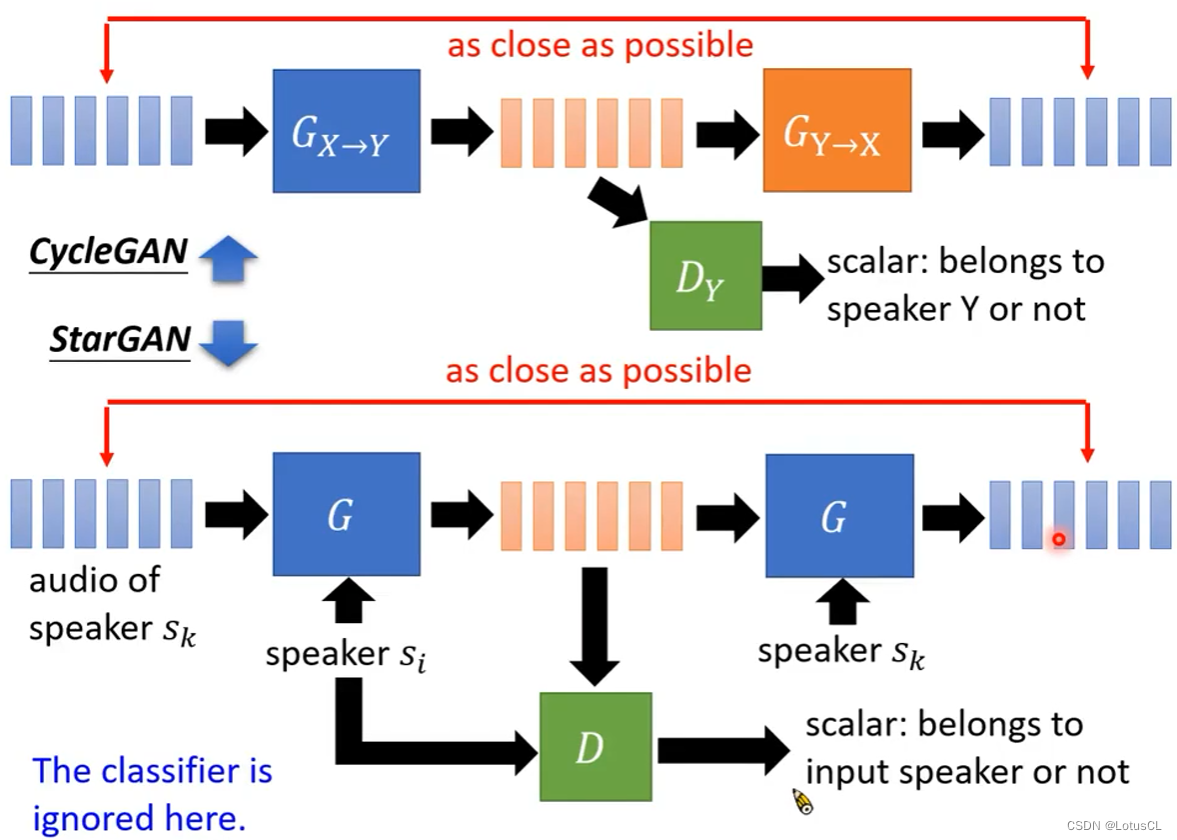
CycleGAN
-
原理很简单,就是做一个Generator,输入X人的声音,输出Y人的声音,并进入判别器,判别器通过Y的声音训练从而能够分辨一段语音是否是Y说的,Generator的目的就是为了骗判别器,让其认为就是Y说的。
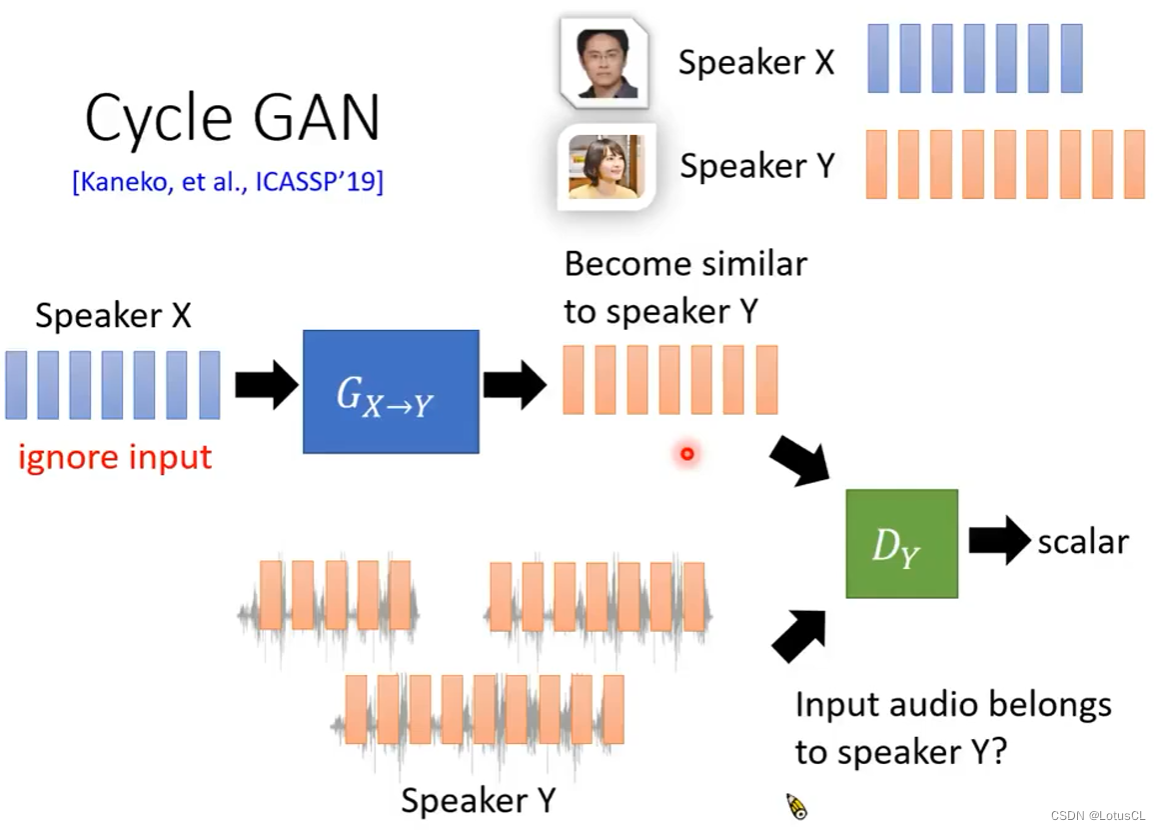
-
但是这样也有问题,就是生成器可能会完全不顾输入的内容,直接输出判别器最想听到的,也就是会发生“模式崩溃”,于是我们再加一个生成器,能将Y的声音转为X的声音,这样我们用前一个生成器的输出作为这个生成器的输入,训练目标就是让这次的输出内容和最开始输入X的内容相近(比如计算L1或L2 distance)。
-
此外,我们还可以再加一个训练过程使其稳定,就是在训练X→Y生成器时,也喂给它Y的语音,训练目标是输出一模一样的声音。
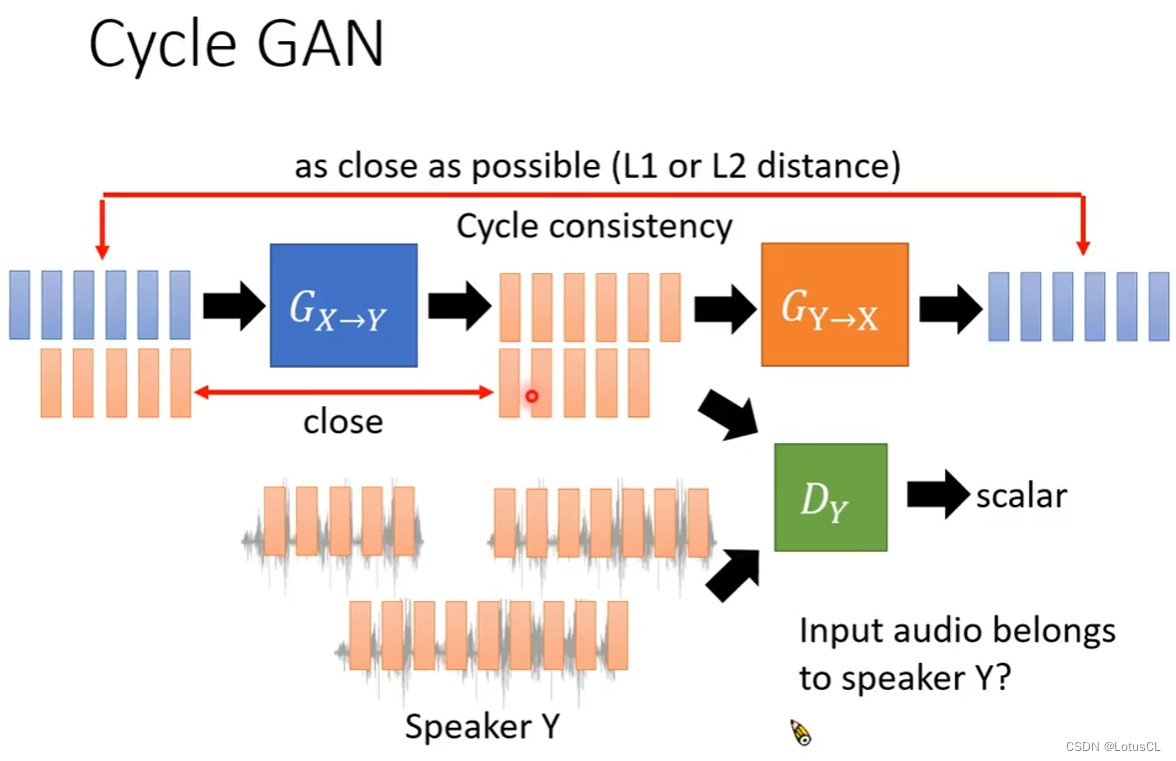
-
同样,我们也可以将两个生成器对调,输入Y的声音,最终输出Y的声音,这样我们就得到了完整的CycleGAN
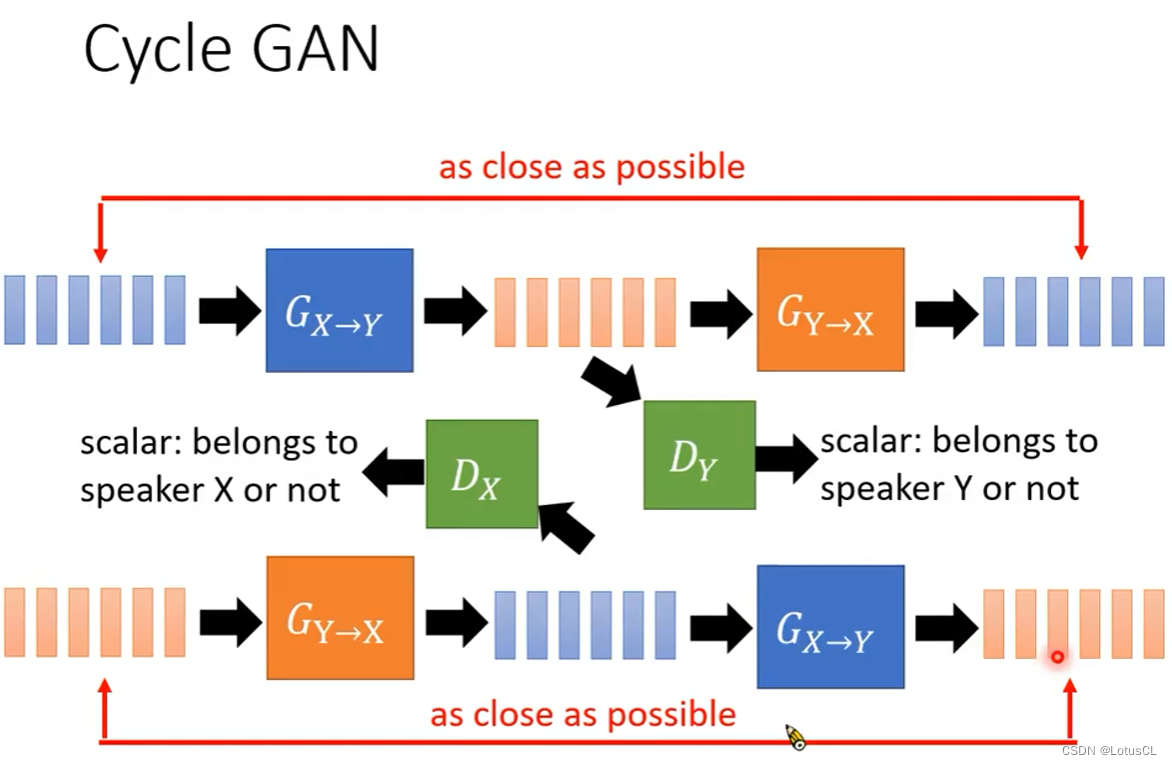
StarGAN
-
CycleGAN有一个缺陷,如果有N个语者的话,要想得到这N个语者之间的语音互转,那么我们就需要训练 N×(N-1) 个CycleGAN,于是就有了我们进阶的StarGAN。
-
StarGAN 对生成器和判别器都做了改进。生成器多了个输入,将speaker的编码也输入进了生成器中,让生成器指定生成语音的来源。speaker的编码可以用独热编码,也可以采用预训练后的speaker encoder。判别器的改动和生成器一样,也是多了个speaker编码的输入,来判别语音来源是否是给定的speaker。
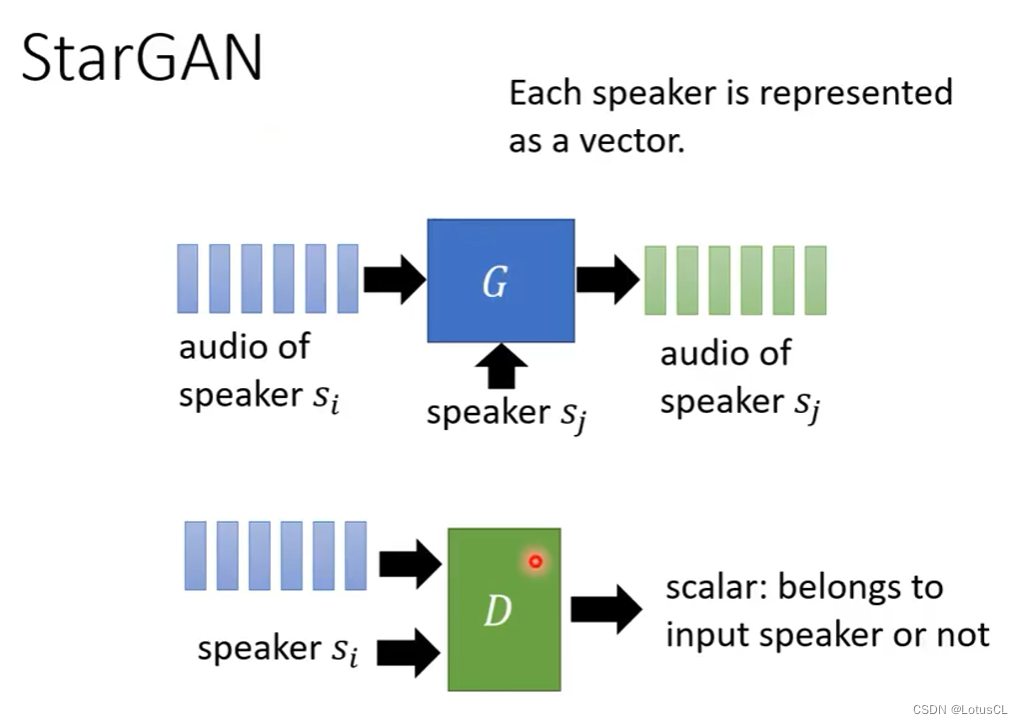
-
具体是怎样操作的呢,输入sk语者的声音,再提供另一位语者si的编码给生成器,让生成器生成si的语音,并顺便将si的编码和生成的si的语音送给判别器,判断是否是si说的话,然后再将sk的编码和生成的si的语音送给生成器,让它生成sk的语音,并将结果与原sk语音做对比,越接近越好(训练目标)。
-
不过,这里是简化的StarGAN,具体论文里还添加了classifier,想了解的话可以去原始论文中查看。
特征解缠与直接转换方法对比
-
想啥呢,其实是对比不了的辣,在文献中,这两种方法是用了不同的网络架构去做不同的事情,确实不太好比较。
-
况且这两种方法也没有冲突,比如你可以把两个方法捏合起来,使用Feature Disentangle的Autoencoder架构来设计Direct Transformation的生成器。
补充
-
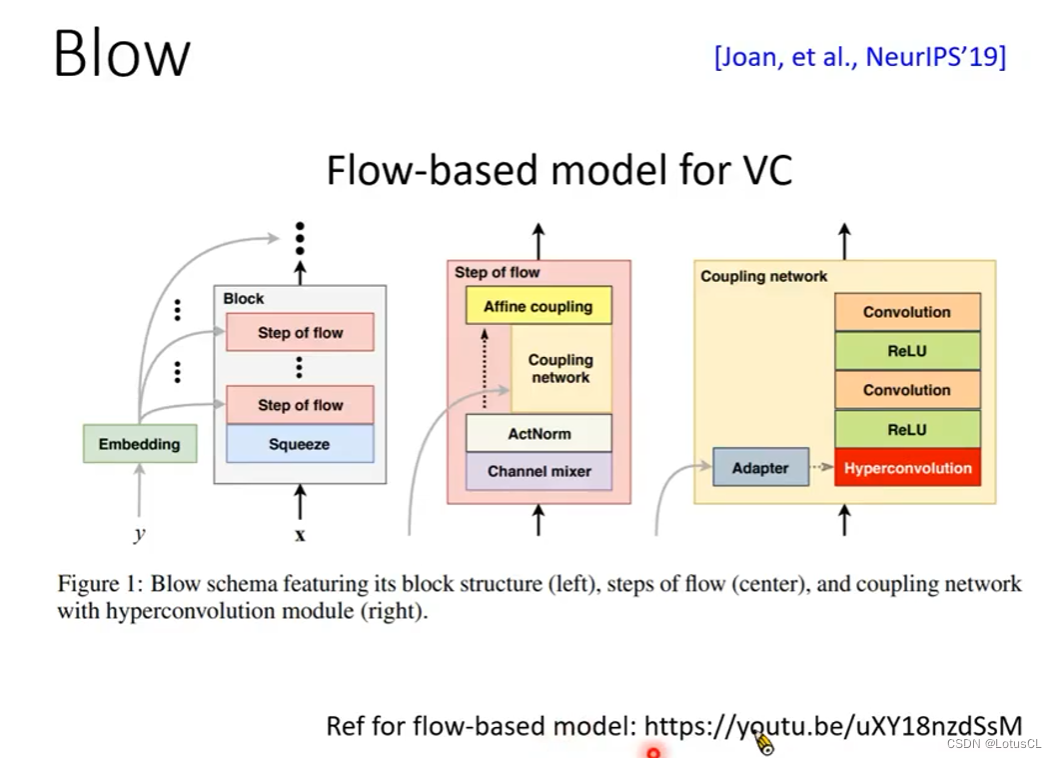
也有一种比 StarGAN 更进阶的做法叫作 Blow。它是用 Flow-based 模型来做 VC。详情可以参考李宏毅之前讲的 Flow-based model 视频(视频链接:台大教授 李宏毅 Flow-based Generative Model哔哩哔哩bilibili )