参考文献:
[1] Chan W, Jaitly N, Le Q V, et al. Listen, attend and spell[J]. arXiv preprint arXiv:1508.01211, 2015.
[2] Speech Recognition - Listen, Attend, Spell (part 2)哔哩哔哩bilibili
目录
Listen:即 Encoder;Spell:Decoder,这是一个经典的使用注意力机制的 seq2seq 模型
一、Listen
-
输入:一串 acoustic features(声音向量)
-
输出:同样也是一串向量,数量、维度和长度均和输入相同
-
作用:提取语言内容信息,将音频信号分析为高级的声学特征表示,将语种之间的差异抹除,将噪声去除
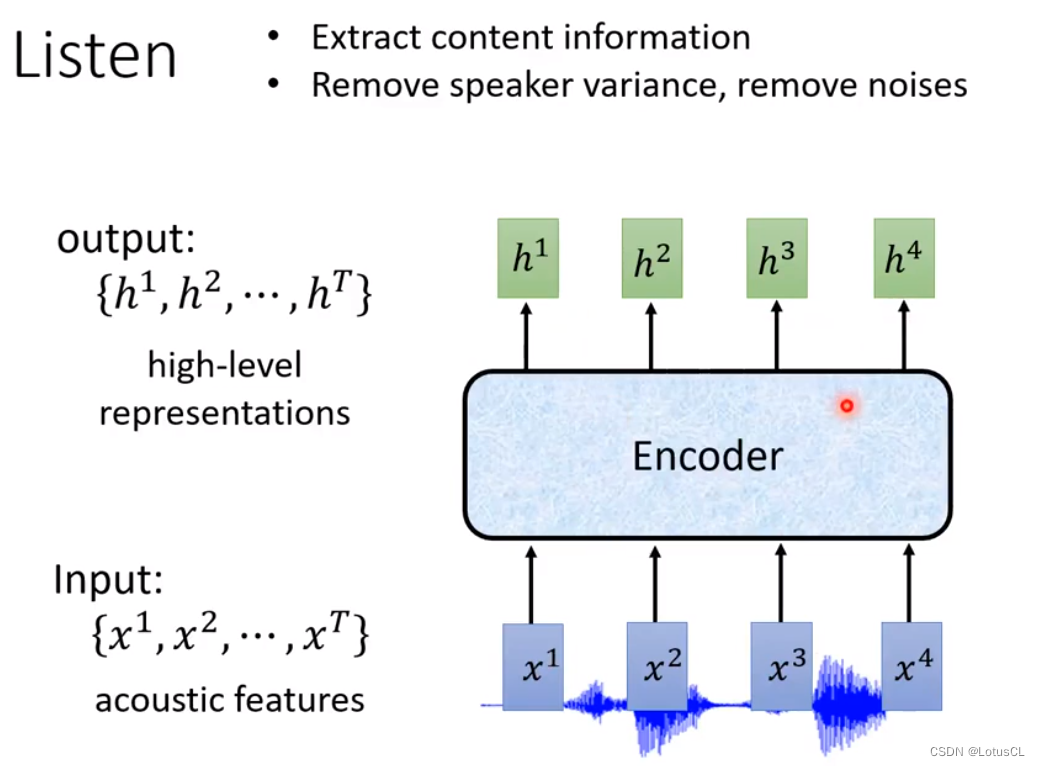
-
种类:
-
RNN(Recurrent Neural Network,循环神经网络):
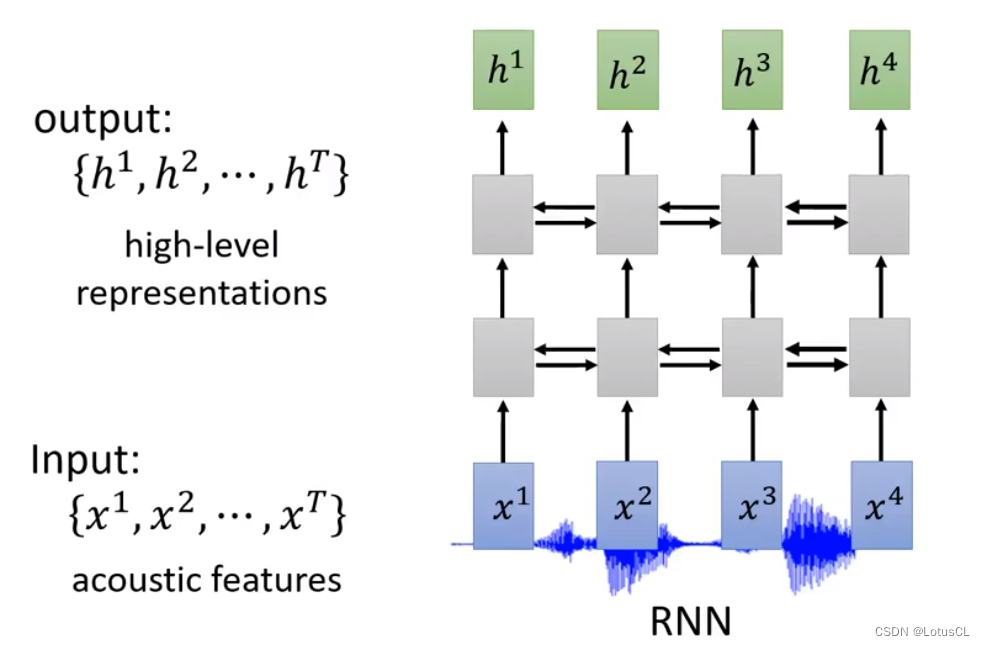
-
1-D CNN(One-dimension Convolutional Neural Network,一维卷积神经网络):

-
Self-attention Layers(自注意力):(类似于 Transformer 模型?)
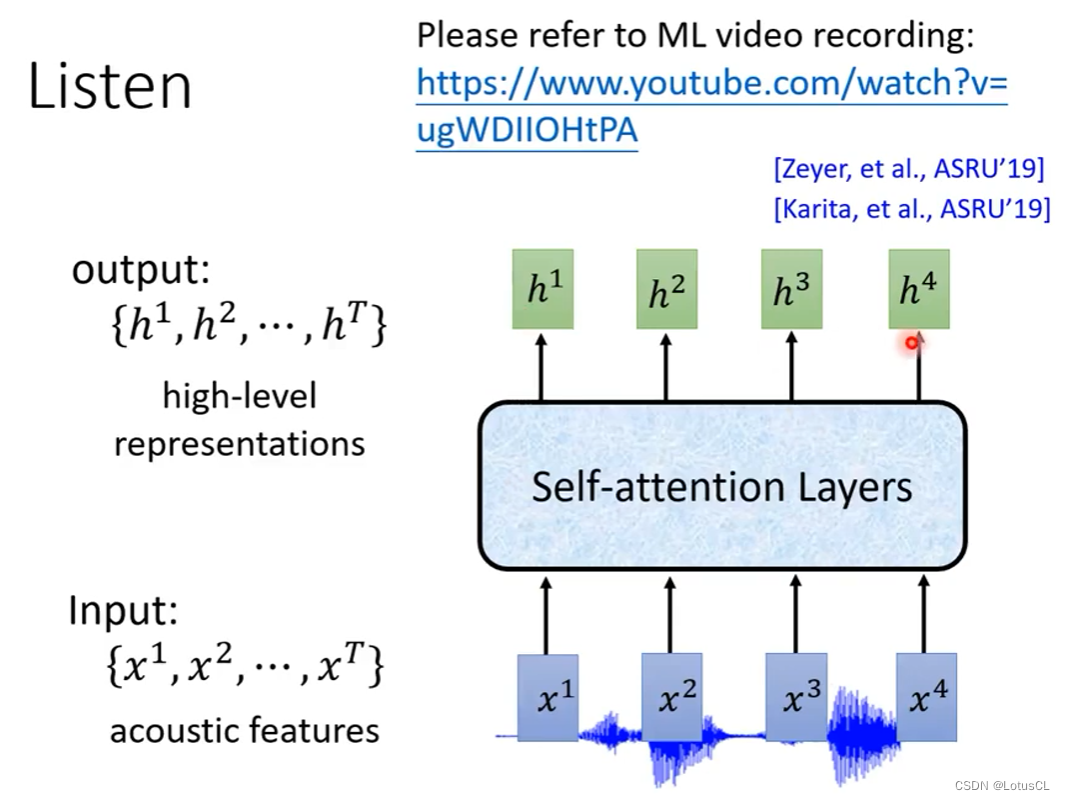
-
Listen - Down Sampling
-
起因:数据量过大,计算量过大,相邻 acoustic features 包含信息差异较小,为了节省数据量,让训练更有效率
-
种类:
-
Pyramid RNN:两个 Tensor 结合起来送入下一层,RNN的变种
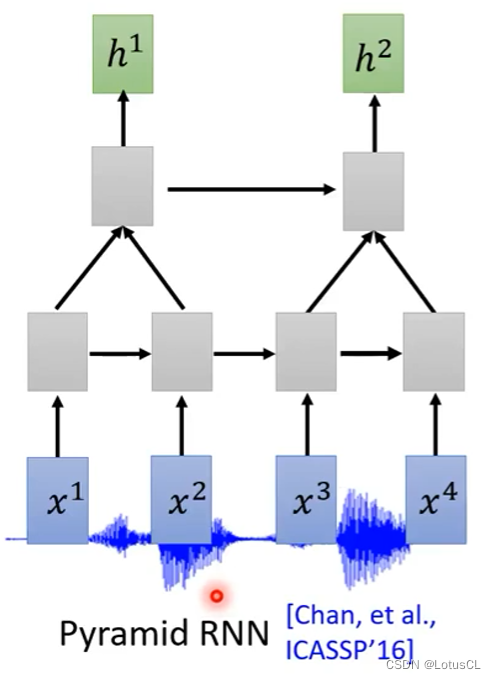
-
Pooling over time:两个 Tensor 选一个送入下一层,RNN的变种

-
Time-delay DNN(TDNN):CNN的常见变种
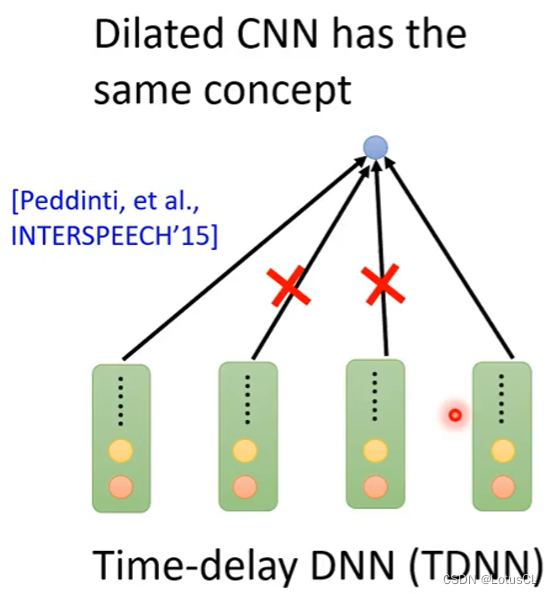
-
Truncated Self-attention:在生成output时,一个Tensor的attention只作用于一段范围,而不是整个input,Self-attention的变种
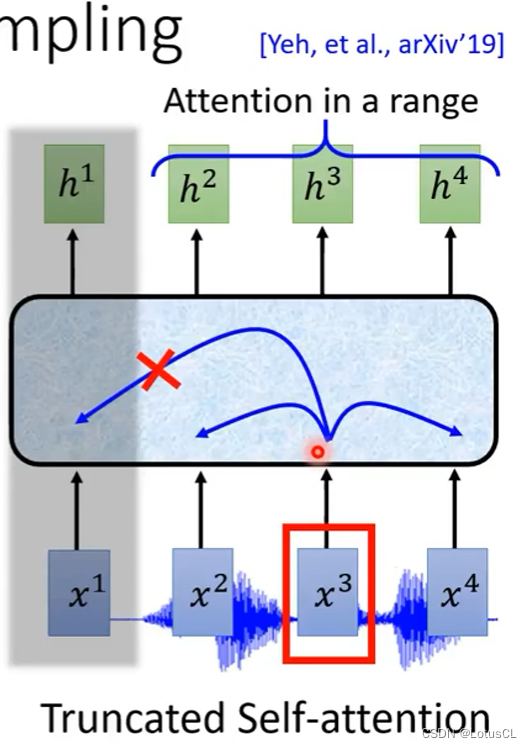
-
二、Attention(Attend)
主要作用是通过注意力机制建立声学特征和文本之间的关联,帮助模型更好地将声学特征转化为文本输出。其可以动态地分配注意力权重,以捕获输入序列中不同位置的重要信息的关键组件。
步骤
-
首先通过 match function 计算Query和Key之间的相似度分数,以确定哪些Value对当前时间步的Query最重要。然后,相似度分数经过 softmax 操作,将它们归一化为概率分布,以获得每个时间步的注意力权重。
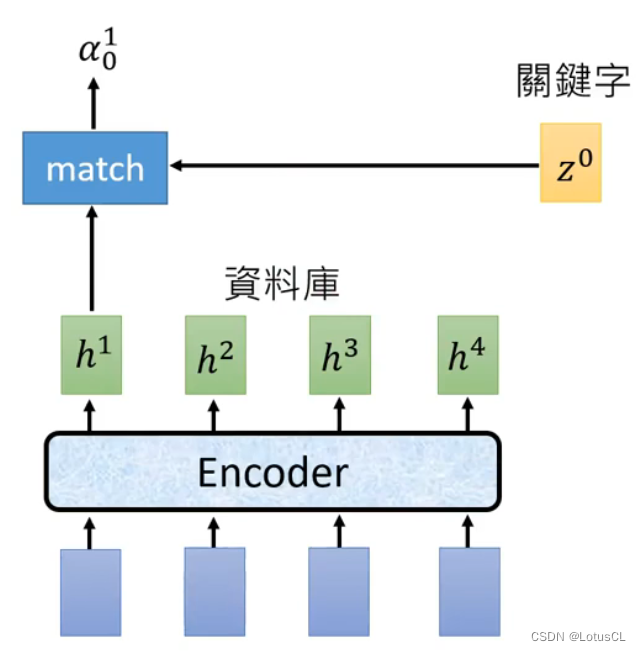
-
Key(键):为Input之一,指的是图中的【h1~h4】。Key是编码器(通常是RNN或CNN)生成的中间表示的一部分。在LAS中,编码器生成的声学特征表示被认为是Key。每个时间步都有对应的Key,因此它是一个时间步的特征向量。
-
Query(查询):为Input之一,指的是图中的【z0】。Query是解码器中的隐藏状态,通常用于生成文本输出。在LAS模型中,Query是解码器中的隐藏状态向量,它表示当前时间步的解码器状态。
-
Value(值):在这里与Key是一个东西,也是指的是图中的【h1~h4】。Value是与Key对应的权重信息,通常也是编码器生成的声学特征表示。每个时间步都有一个对应的Value。Value包含了有关输入序列的有用信息。
-
-
然后,相似度分数经过 softmax 操作,将它们归一化为概率分布,以获得每个时间步的注意力权重。
-
最终,注意力权重用于对 Value 进行加权求和,生成加权的声学特征表示,这些特征将用于生成文本输出。这个加权求和过程允许模型自适应地关注输入序列中与当前解码步骤相关的信息,从而提高语音识别或文本生成的性能。
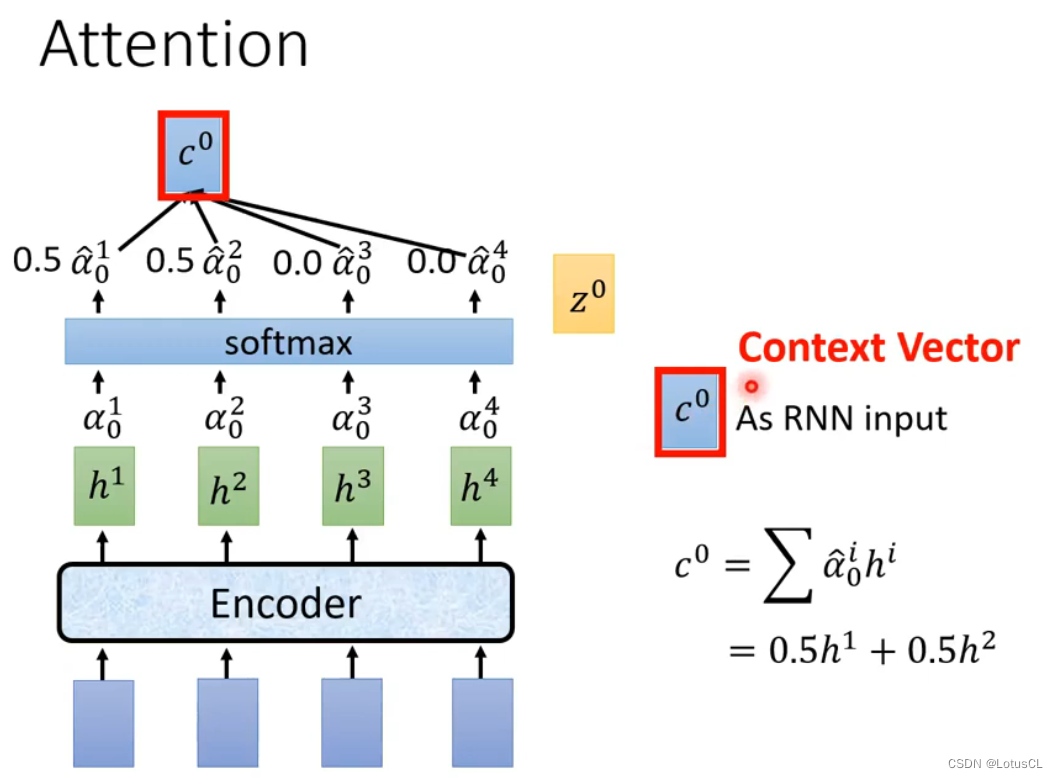
-
Context Vector(上下文向量):就是Attend环节的 Output,指的是图中的【c0】。其随后与解码器的隐藏状态相结合,通常是通过简单的拼接或加法操作,以生成一个包含上下文信息的声学特征表示。这个合并后的特征表示将被解码器用于生成下一个文本标记,从而实现语音识别或文本生成任务(在后续的 Decoder 中有介绍。
-
Match function
-
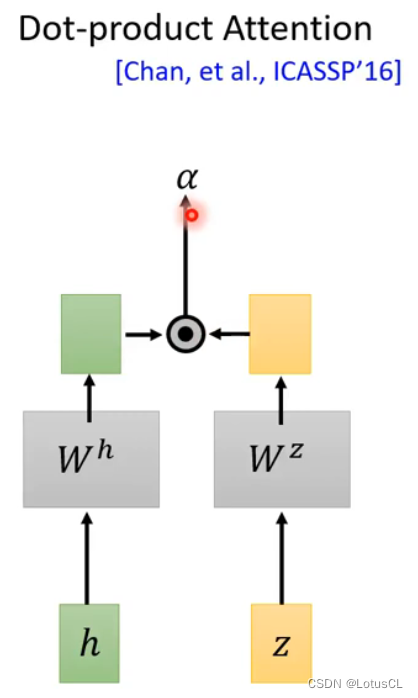
Dot-product Attention:
-
将z与h进行transform,然后进行点积
-
-
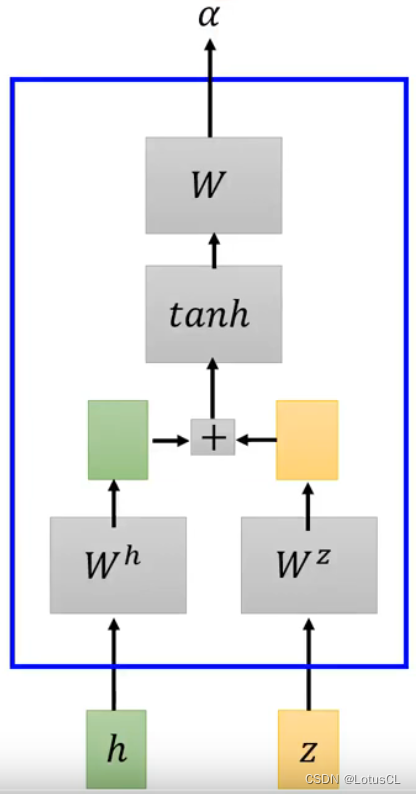
Addictive Attention:
-
z与h进行transform后,相加,然后经过一个function,然后再来一个linear transform
-
探讨:我们为什么要使用注意力机制?
-
Attention,意思是关注,事实上,这个最早是被用在 Translation 任务中。因为在翻译时,输入和输出并没有一致的对应的关系,比如你可能翻译出来的第一个词汇很有可能来自于输入文本的最后一个词汇。因此我们需要使用注意力机制,来让Decoder能从Encoder那边自己寻找它现在需要解码的词汇。
-
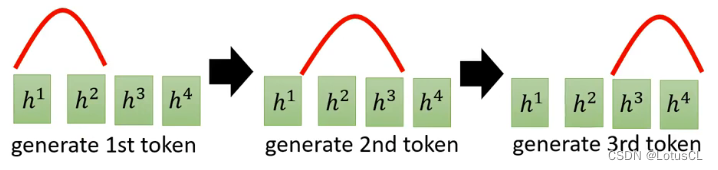
然而,在语音识别时,最好的情况下,前面的语音就是对应前面的token,然后一点一点移动下去,也就是说,decoder 需要关注的上下文信息理论上是慢慢往后走的:
而并不会出现乱跳的情况:
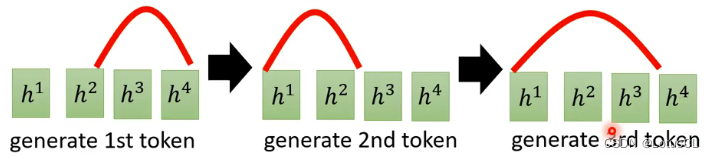
但是 attention 机制赋予了decoder能够乱跳的能力!!!这不对啊!
-
第一篇(?)使用seq2seq模型进行语音识别的作者也注意到了这个问题,因此他又加了一个机制,让当次计算的 attention 的 weight 需要受到上一次 attention 计算的 weight 的影响
Location-aware attention
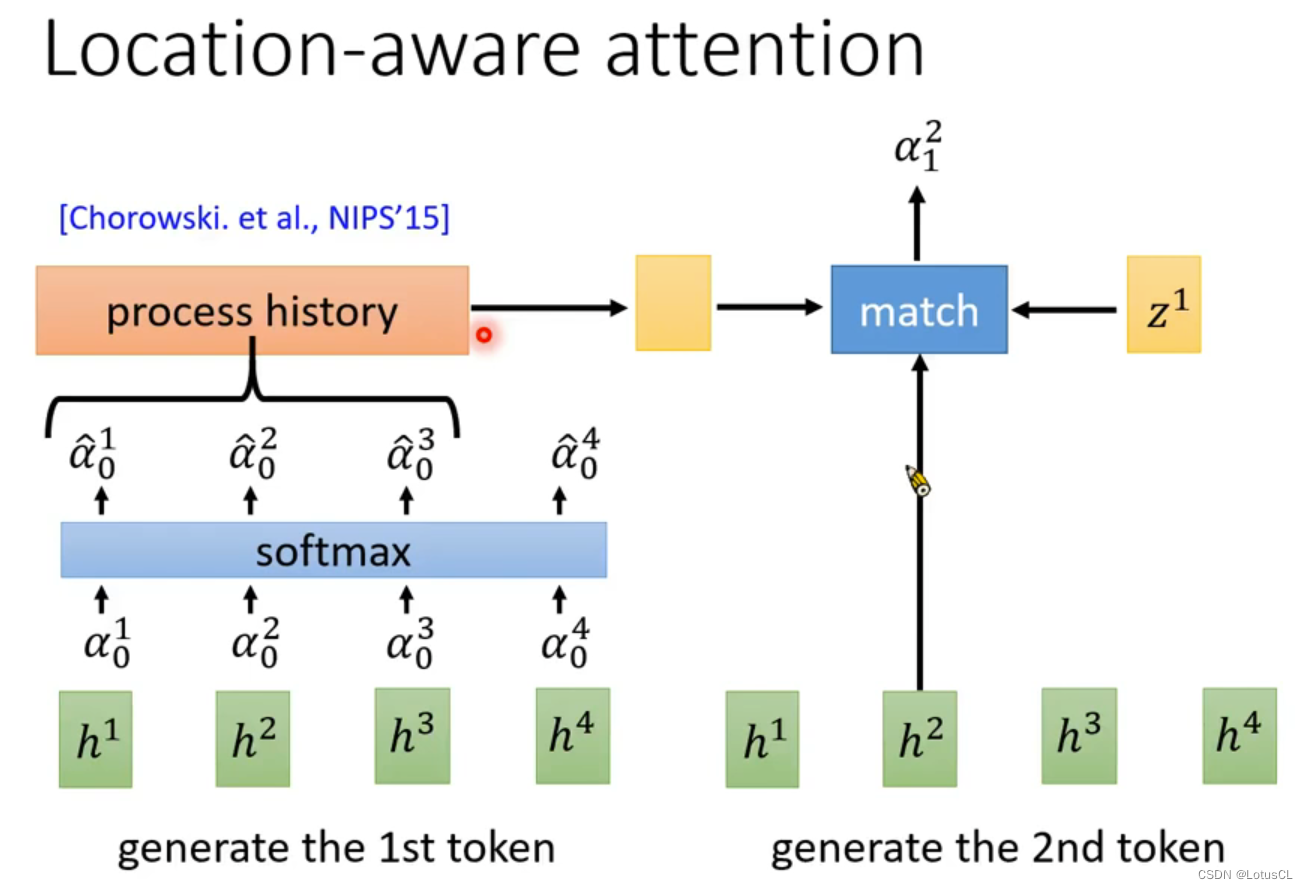
-
在这里要计算第二个token的α12时,我们同时考虑上一次 attention 计算过程中,h2 附近的计算结果(需要给定窗口大小)
-
比如这里取的是计算第一个token中 h2 前一个、自身和后一个的,将其纳入transform中传入计算第二个token中
探讨:然而,注意力机制这个真的有很大的用处吗?
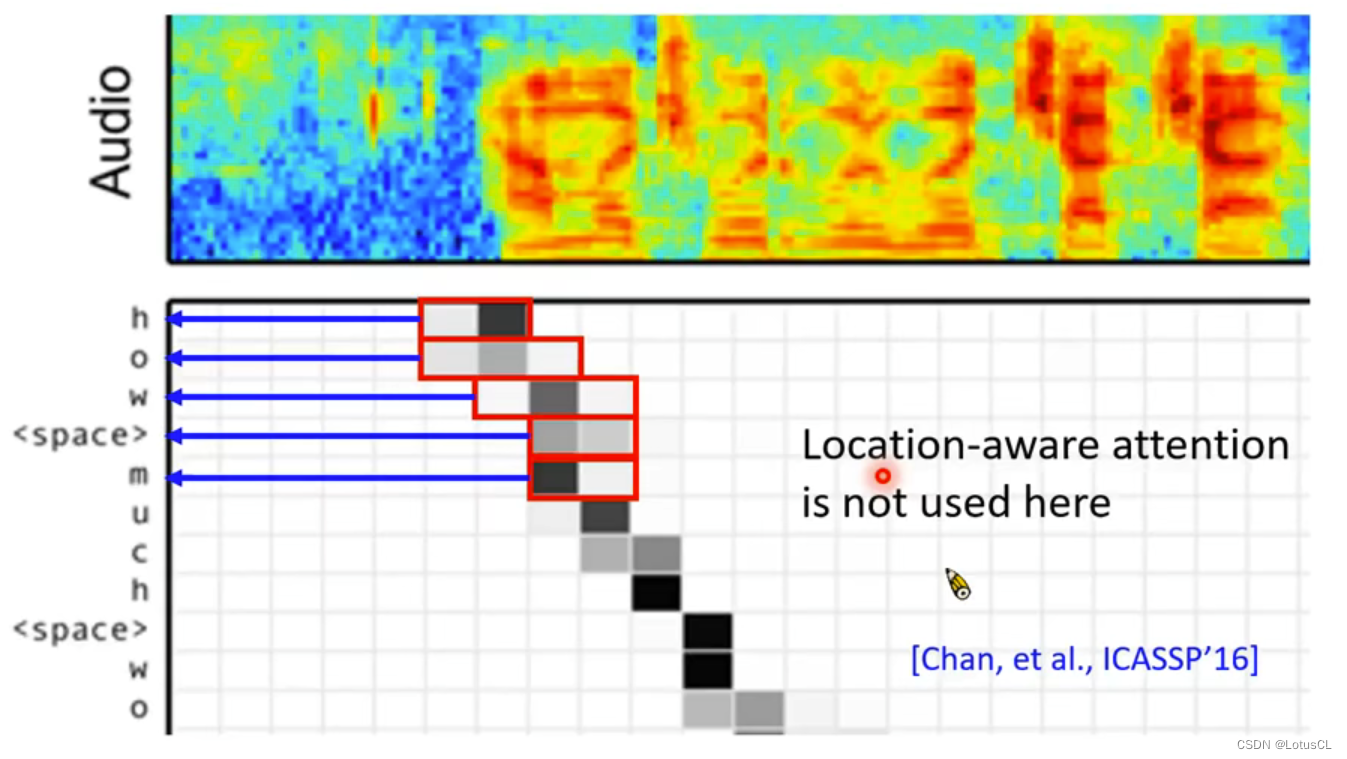
-
经过大家的测试,如果不使用 Location-aware attention 机制的话,其实 attention 也并不会乱跳,它自己也能学乖,一步一步走
三、Spell
步骤
-
上下文信息融合:
-
Input:
-
前一个时间步的隐藏状态(zi,初始为z0)
-
前一个时间步生成的标记(token,初始为起始符号如<s>)
-
当前时间步"Attend"环节的输出(即上下文向量Context Vector)
-
-
Method:通常是使用前馈神经网络,如RNN单元
-
Output:
-
新的隐藏状态z1
-
vocabulary 各个token的概率值(distribution)。
-
-
-
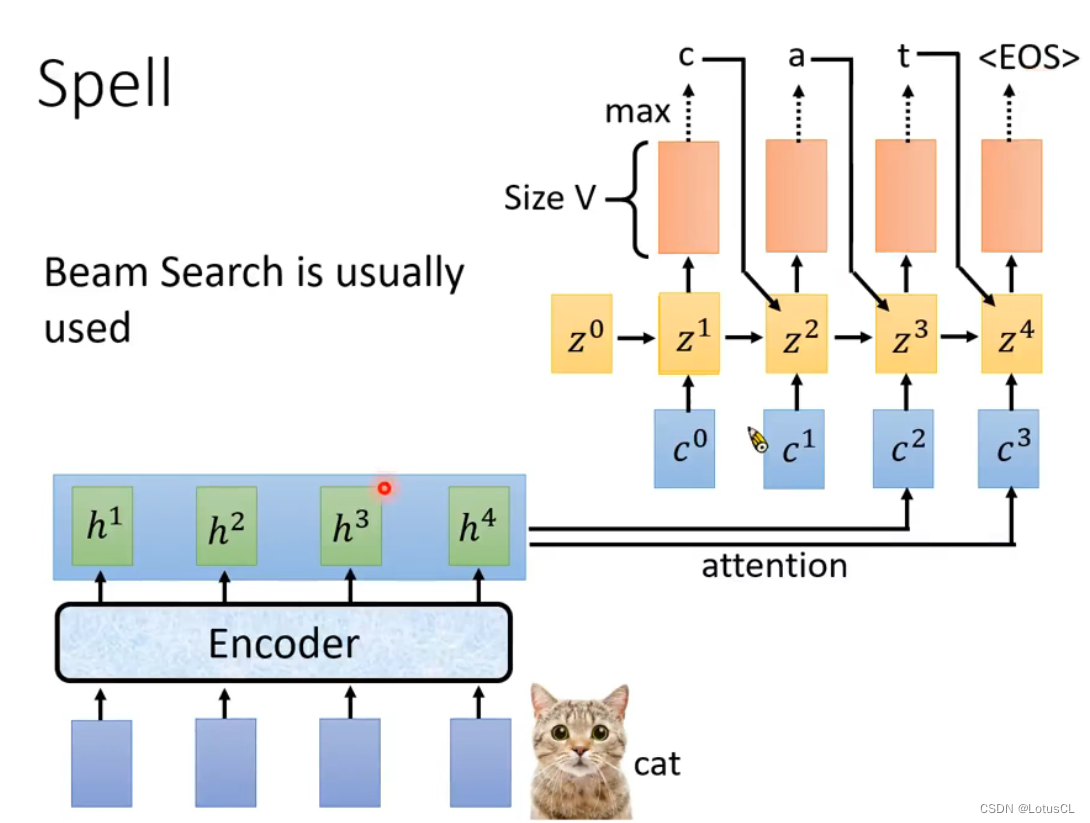
随后一般就从 distribution 中取概率值最大的那个token,作为本次的 token 输出,比如cat,第一次输出token:c。
需要明确的是,如何选取 token 也是需要进行研究的,这里取 概率值最大的 Token 采用的技术叫 贪心解码(Greedy Decoding),常见的还有 束搜索(Beam Search),我们将在之后介绍这种采样技术
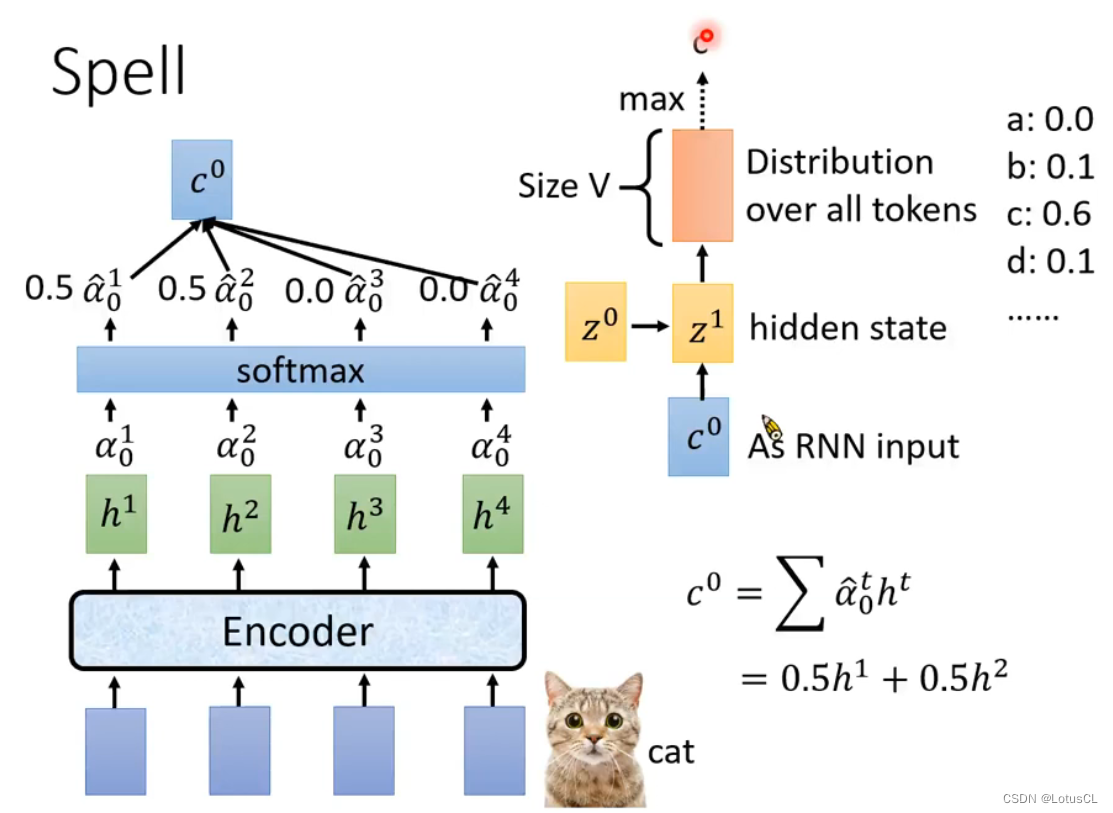
-
然后将刚刚得到的新的hidden state z1,去做attention,得到c1,然后再进行刚刚的操作,即将得到的 z1 投入新一轮的 attention 中,计算得到c1,再去计算下一轮。
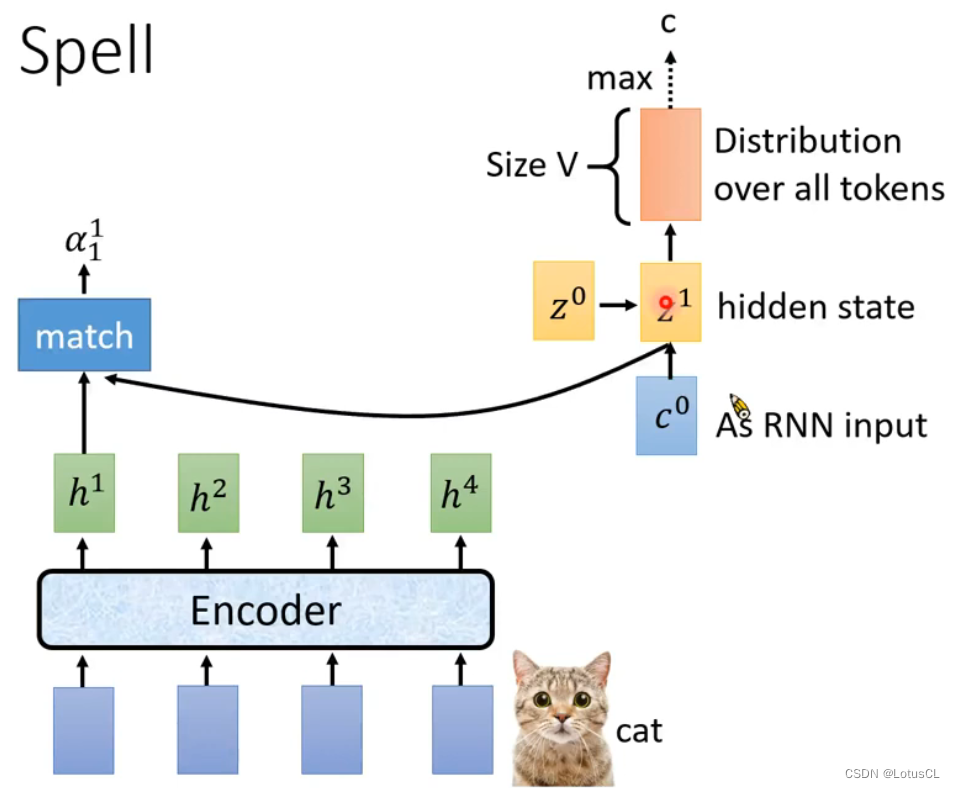
事实上,这里也分了2种情况,一种是这样的,一种是这里的c1还会影响自己那一步的输出:
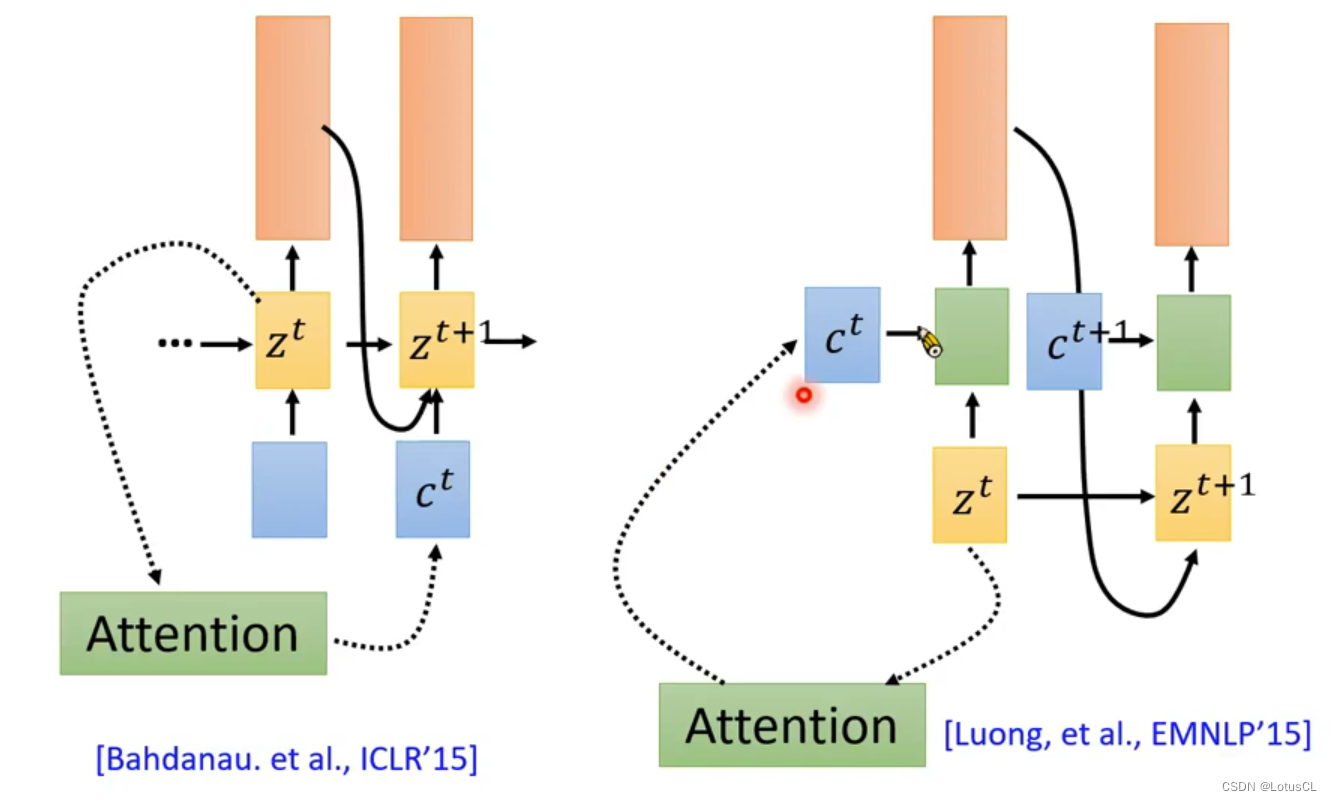
那么我们的第一篇利用seq2seq模型做语音辨识的论文是采用了什么方式呢?我全都要!
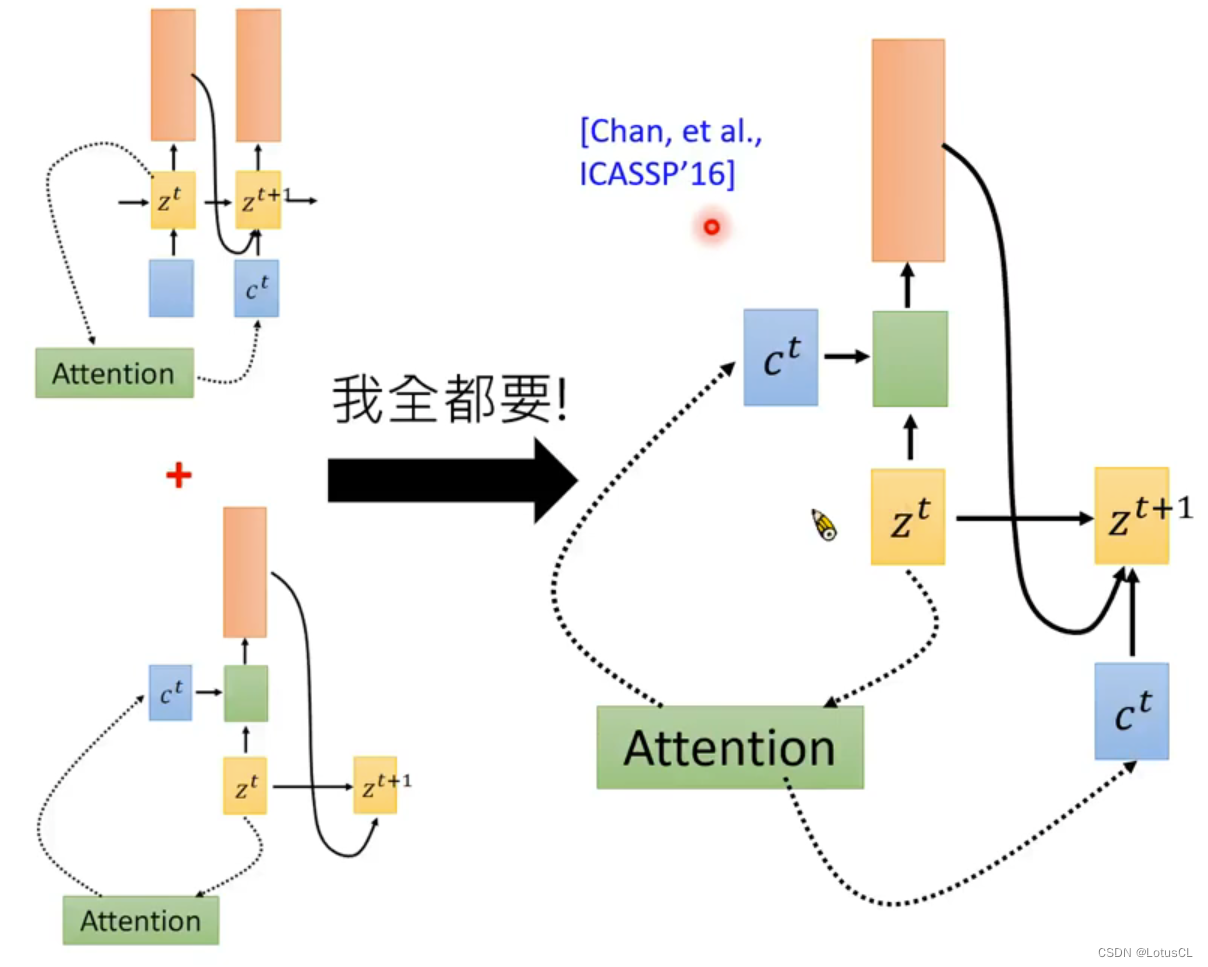
-
然后不停循环,直到最后生成结束标志或达到最大生成长度为止。
Beam Search
中文名为“束搜索”,其出现的原因是因为若我们每次都在当前位置直接取max,也就是采用所谓的“Greedy Decoding”,基于贪心的解码策略,我们不能保证生成整个序列的概率是最优的。例如下述情况:
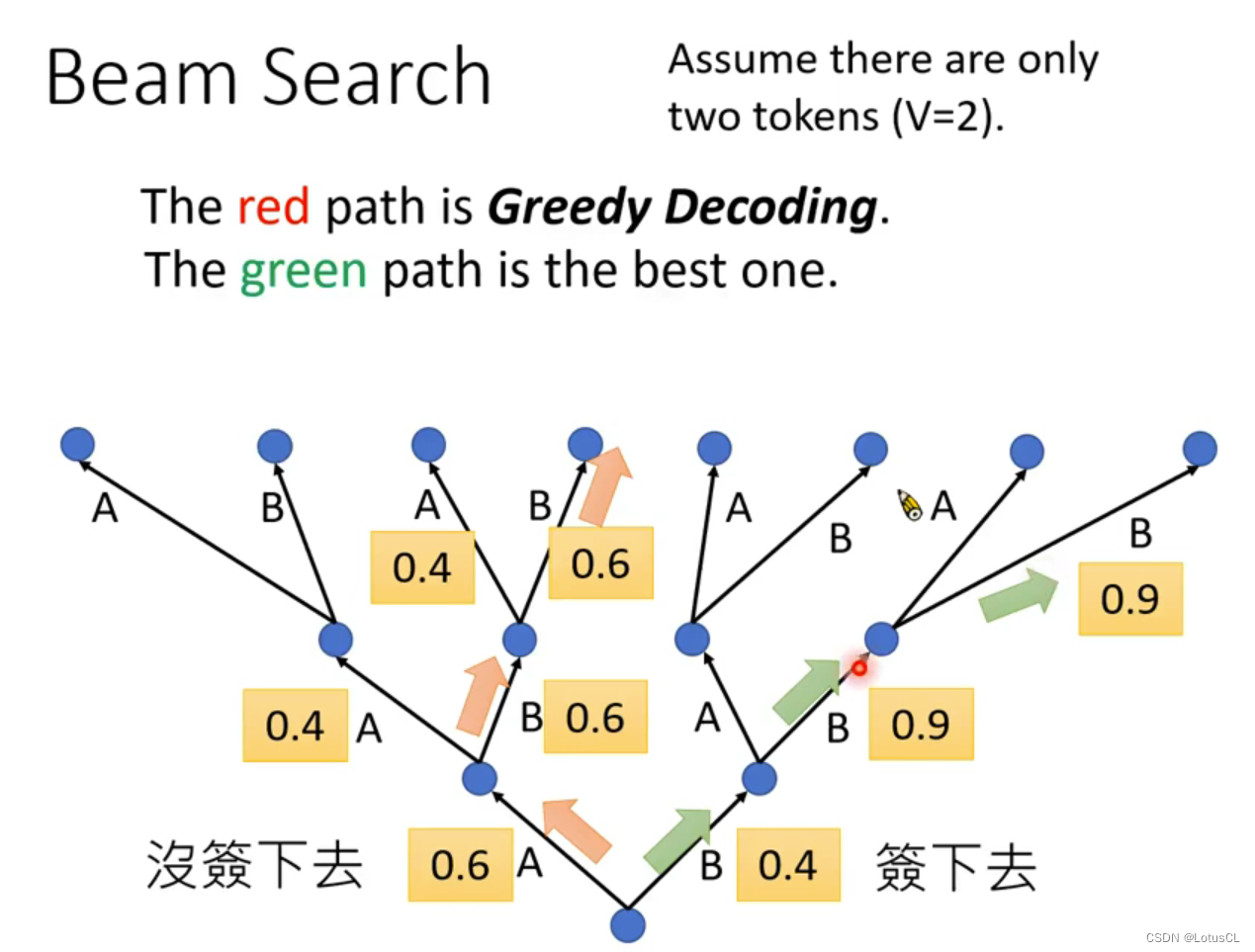
-
在这种情况中,我们假设 token vocabulary 仅为2,只有 A、B两个 token
-
红色路径是我们采用贪心解码策略获得的结果,但它并没有绿色路径的结果的最终概率要大
-
因此,当我们采用 Greedy Decoding 时,我们并不能保证我们能取到最优解。
理论上,我们应该遍历所有的path,找到那个概率最大的,也就是理论最优解。但实际中,我们的词表很大,没有办法去搜索穷尽所有的可能性。解决这个问题的方法就是使用Beam Search。它是窗口大小为K的贪心搜索。从每个节点我们都保留K个最好的路径,一直往下,如下图:
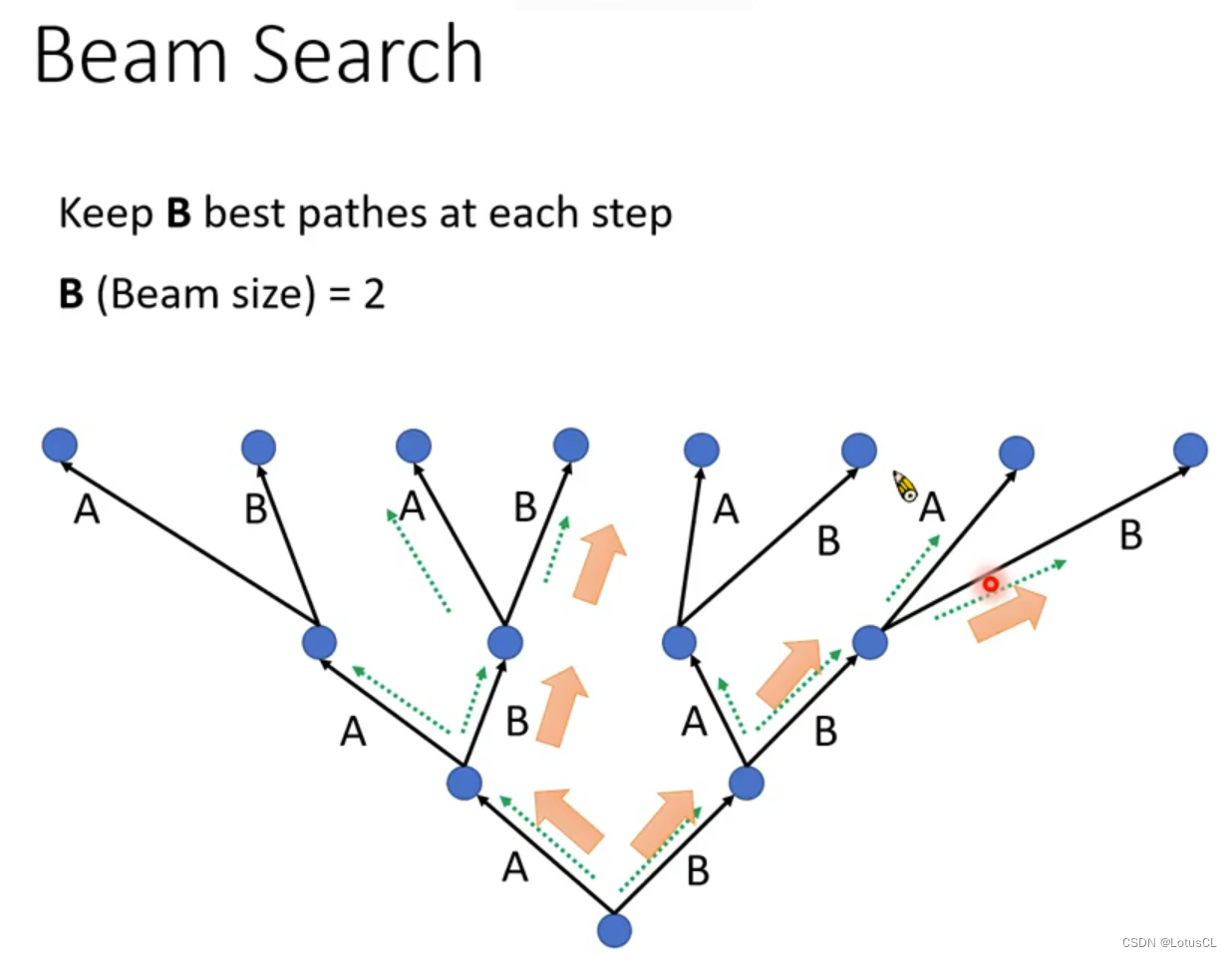
-
这里,我们每次都保留当前概率最大的 2条 路径。
-
最终,我们就能取到所谓的最优解。
四、Training
One-hot vector:(独热向量)是一种用于表示分类数据的二进制向量,其中只有一个元素为 1,而其他元素都为 0。这个元素对应于数据的分类或标签,而其他元素则表示不同的分类或标签。
Teacher Forcing:上面 Transformer 章节中有讲过,这里简单赘述,它是一种在训练序列生成模型(如语言模型、机器翻译模型等)中常用的技术。在训练过程中,Teacher Forcing 通过将模型的真实目标序列作为输入来辅助模型的训练。
-
给予相应的声音讯号和输出结果进行训练
-
先使用声音讯号,生成第一个字母,如对于cat的训练资料,我们让机器先生成第一个字母的 distribution
-
这个 distribution 我们需要让它的 c 概率最大化
-
因此我们将这个 distribution 与 c 的 one-hot vector 计算交叉熵(Cross Entropy),作为模型的损失函数。
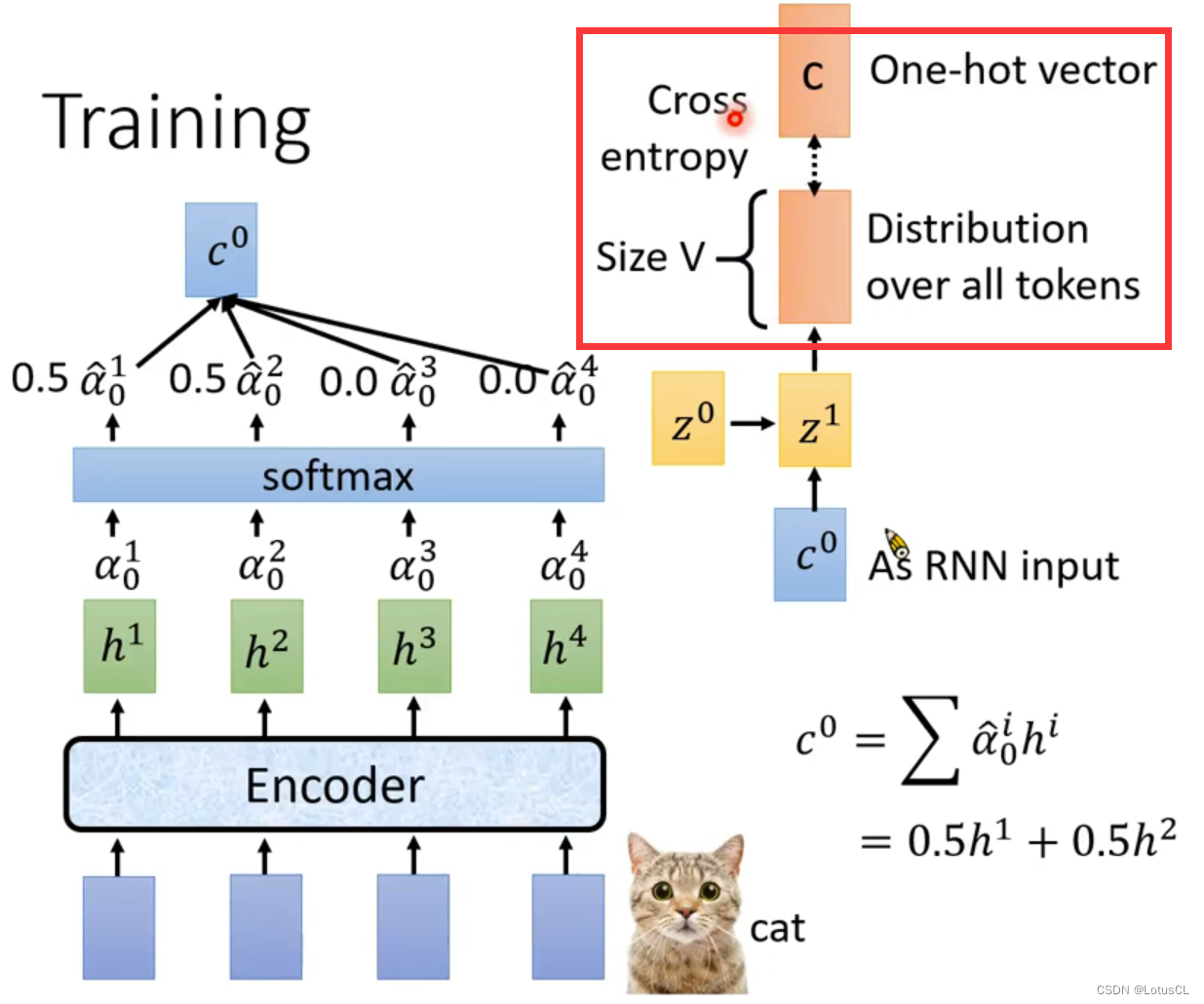
-
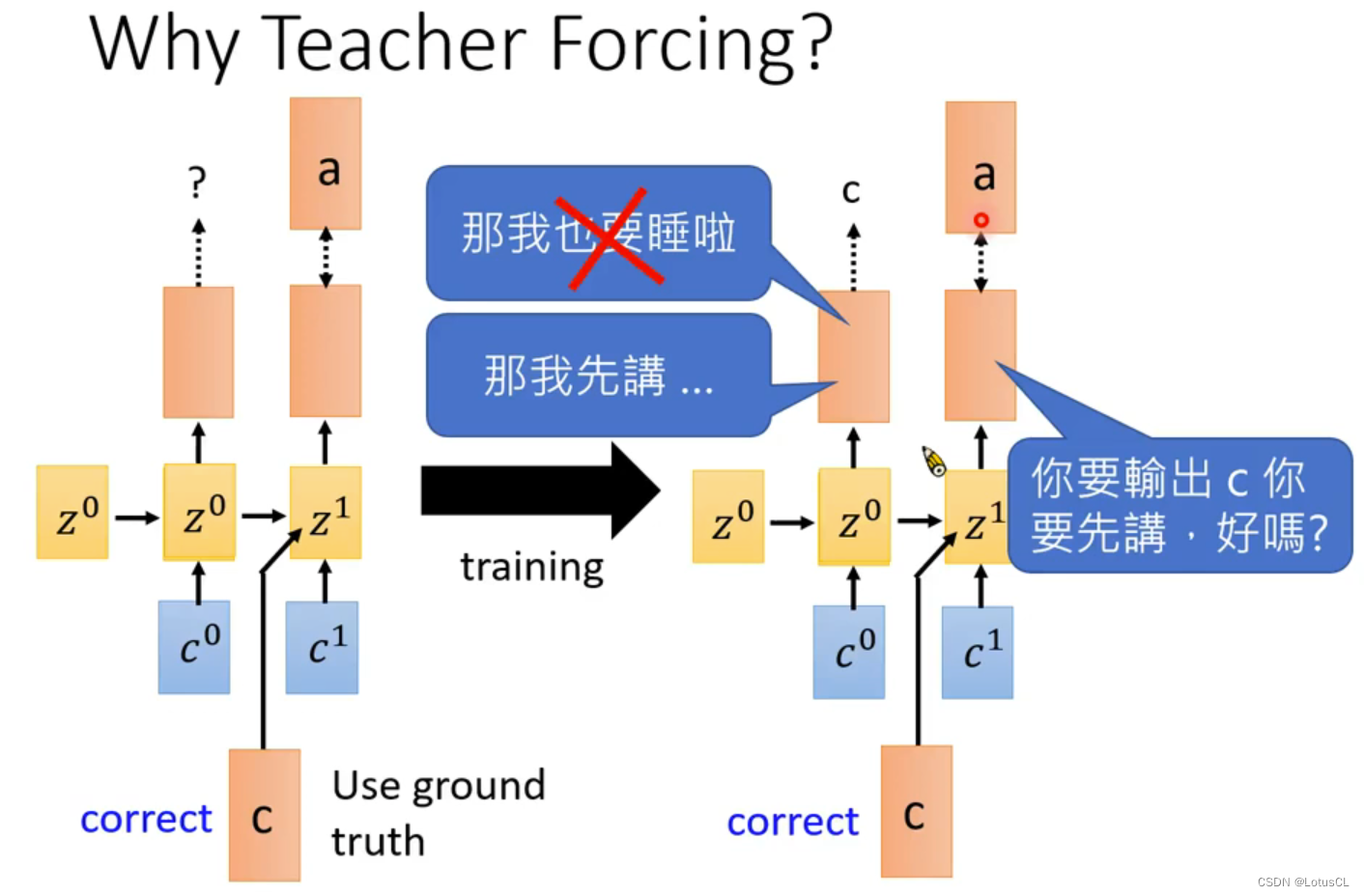
然而,在训练第二个及以后的字母时,我们并不会和 Inference 的过程中采用的方法一样,将上一步输出的 token 作为下一步的输入,而是采用 Teacher Forcing 的技术,固定将 结果c 作为下一个字母distribution计算的输入。
这里为什么要用 Teacher Forcing?李老师给了一个很有趣的解读:一开始你的Decoder很烂,第一个token你输出了x,然后你让下一个token见到x以后输出a。但是最后训练完的结果是什么呢?是看到c然后再输出a。那我作为第二层的distribution我就很恼火啊,前面的功夫不都是白费了么
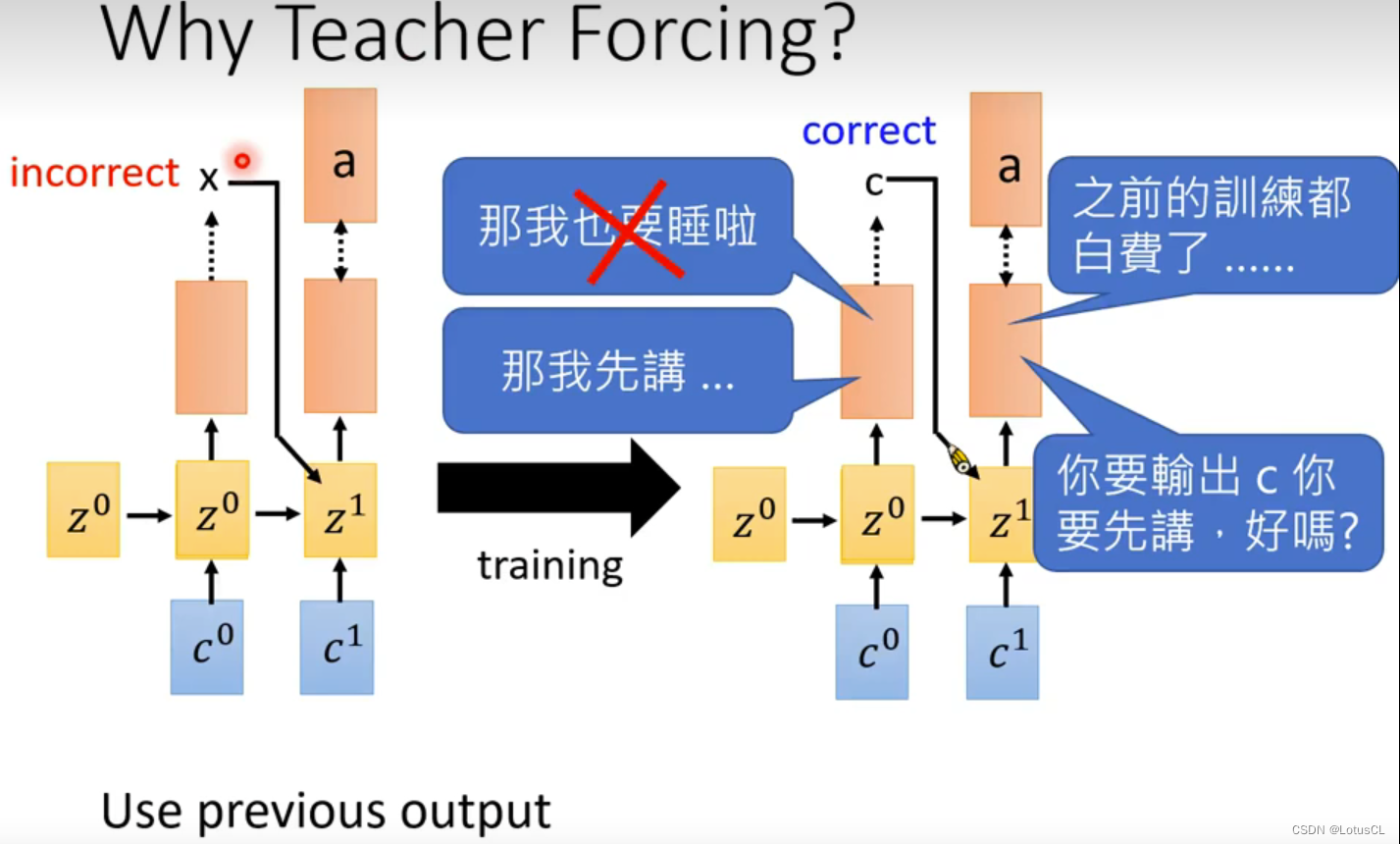
所以我们不能让这个事情发生,每一层就应当给予正确答案,专注自己所学,而不要被前边人影响(×)
五、总结与局限性
-
在一开始,LAS 在一些小数据集上面训练出来的结果其实并不是很好,它和常规的深度学习结果还有一定的差距。但随着训练的数据集越来越大,LAS也开始起飞了,最终在12500hour+的数据集上反超了常规深度学习的算法,并且LAS在模型大小上(0.4 GB)还远胜于传统深度学习算法(7.2 GB)
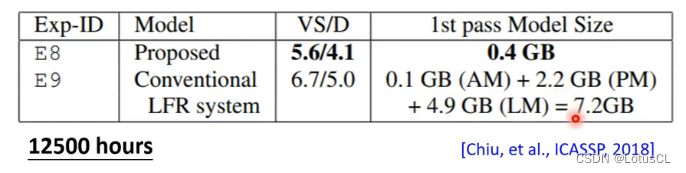
-
LAS 有时候也可以学习到很复杂的声音讯号和文本文字之间的关系,如下图,在这里,对Truth语句的辨识中,aaa是权重第一(正确),triple a是权重第二,而 triple a 和 aaa 其实在语音方面相差实际很大,然而二者的意思却又完全相同,所以很神奇。

-
因此,LAS 也可以做类似于 <闽南语转中文> 这样的带了一点点翻译工作的任务,效果还不错
-
LAS 不可以实时转文字,必须要听完完整一段话后才能输出第一个 token。但是实际运行中,用户更希望说一点,机器辨识一点