版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/xd15010130025/article/details/88751987
1.语音包模型及其到达
1.1语音模型
我们说话的时间分布服从指数分布,但是空闲时间不太符合指数分布
1.2到达
语音的到达是一个典型的2状态生灭过程
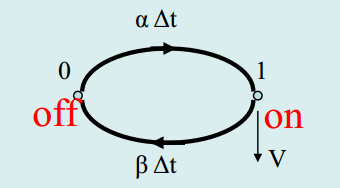
2.系统能服务的用户个数
2.1激活因子
我们把处于讲话状态的概率成为激活因子,即
2.2能容纳的用户数
显然,我们有结论,若在激活状态语音包的速度为NV,系统的处理速度是CV,可以得到
我们再做一个详细的推导,容易知道有
得到由系统容量知道用户数的公式
3.例子
Say a bandwidth of 3000 packets/sec(1.272Mbps,packet=1 ATM cell=53 byte) is set aside to accommodate voice traffic.Since V=170 packets/sec is the packet generation rate of each voice source while in talk spurt, for an activity factor is 0.4,how many users can it hold?
由公式
知