参考文献:
[1] Speech Recognition- Language Modeling哔哩哔哩bilibili
[2] 2020 年 3月 新番 李宏毅 人类语言处理 独家笔记 Language Model - 9 - 知乎 (zhihu.com)
本次省略所有引用论文
目录
一、LM 的必要性
-
Language Model 是什么?是估计一段 token 序列的概率的方法
-
Estimate the probability of token sequence
-
-
在 HMM 中,LM 被自然用到,而在 LAS 这样端到端的语音模型中,原本不用用到,但是加上以后其表现会显著提高。
-
这就是因为,LAS 是对条件概率建模,需要成对的数据,收集比较困难;而 LM 用到的只有文本的数据,非常容易收集,因而我们很容易得到 P(Y) 的分布。
-
事实上,只要你的模型最后输出是文本, 那么加上 LM 总会有用的。

-
BERT 大型 LM 模型,只有文本,大约有30亿以上的词。
二、如何估计 token sequence 的几率
N-gram
-
N-gram language model 计算 token sequence 几率方法(以 2-gram 为样例):
-
-
例如:
-
-
如此一来,3-gram就是统计前两个词然后计算下一个词的概率,以此类推 n-gram。
-
-
N-gram 出现的问题在于:当采用较大的 n 时,由于数据的稀疏性,会导致条件项从未在语料库中出现,导致最终计算的概率为0。
-
解决方法:采用 language model smoothing ,即让原本概率为0的情况不为0。
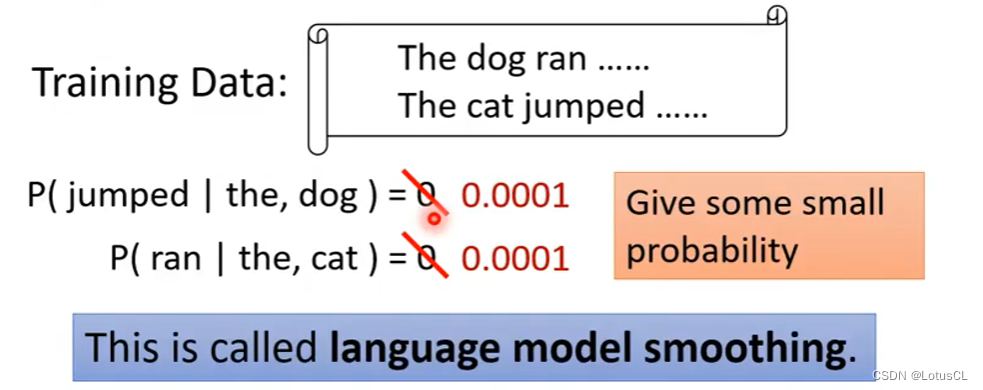
-
Continuous LM
Matrix Factorization:Matrix Factorization(矩阵分解)是一种数学和计算方法,通常用于在机器学习和数据挖掘领域中处理矩阵数据的技术。其主要目标是将一个大矩阵分解成两个或多个较小的矩阵,以捕获矩阵中的隐藏结构和关系。
在Matrix Factorization中,通常有一个大的矩阵,其中包含了许多观测数据点。这些数据点可以代表用户对物品的评分、文档中单词的出现频率、用户和物品之间的关系等等。Matrix Factorization的目标是找到一组较小的矩阵,使它们的乘积近似等于原始矩阵。
在推荐系统中,Matrix Factorization经常被用来解决协同过滤问题,其中用户和物品之间的关系矩阵是非常稀疏的。通过将这个大矩阵分解为两个低维矩阵,可以捕获用户和物品之间的潜在特征,从而更好地预测用户对未知物品的兴趣。
Matrix Factorization的一种常见方法是奇异值分解(Singular Value Decomposition,SVD),它将矩阵分解成三个矩阵,包括一个左奇异向量矩阵、一个奇异值矩阵和一个右奇异向量矩阵。在实际应用中,SVD经常受到矩阵的稀疏性和缺失数据的限制,因此,更常见的方法是使用梯度下降等迭代方法来寻找矩阵的分解。
Matrix Factorization在推荐系统、文本挖掘、图分析等领域中得到广泛应用。它允许数据降维,发现数据中的隐藏特征和关系,从而更好地理解和利用大型矩阵数据。
-
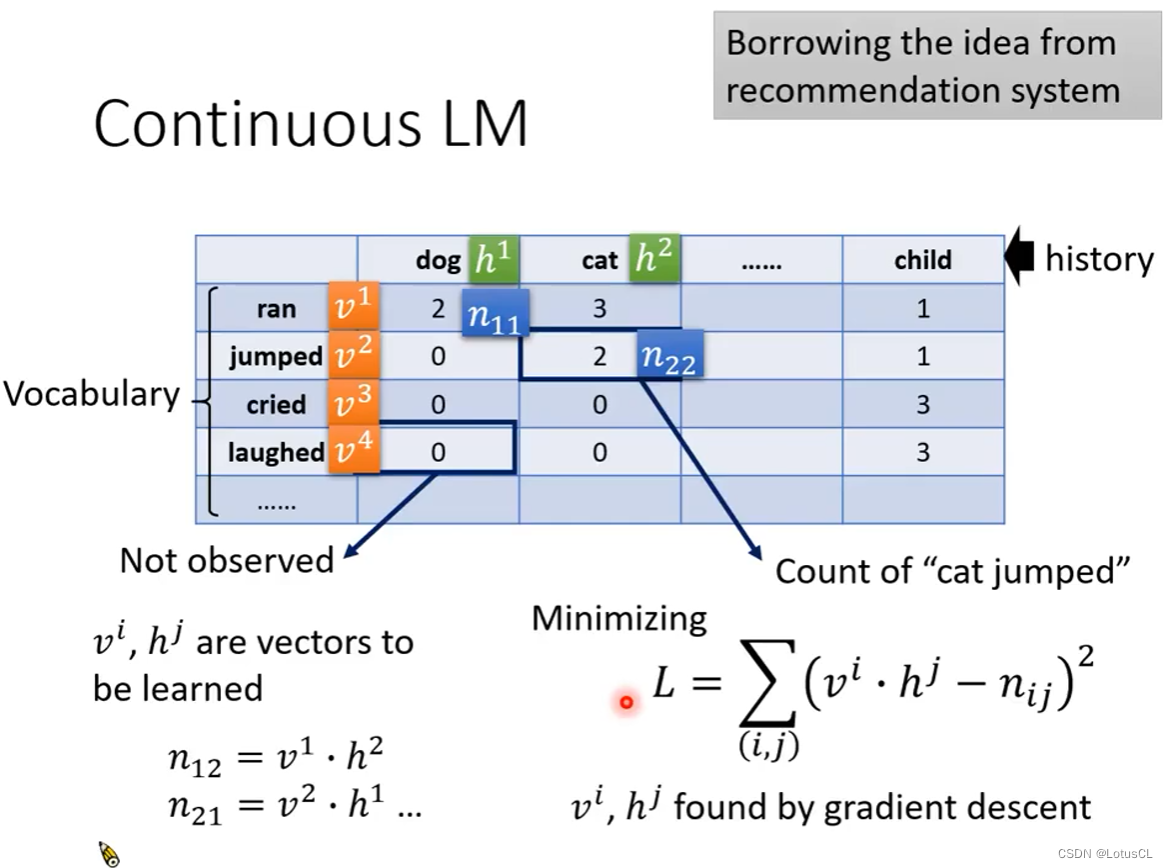
关键是其采用的 language model smoothing 技术。其来自于推荐算法中的 Matrix Factorization(矩阵分解)。示意图如下:
-
表格中,dog,cat 是前置词汇,表格中的值表示前置词汇后接 ran,jumped等词汇的次数。(二者相交处的格子填共现的频次)
-
我们的目的是尝试使用hi、vi向量来表示各个词汇,也就是找出一个function,输入单词,输出其向量。
-
因此我们采用梯度下降法来找到这些词汇所对应的向量,采用L2损失,Loss函数如图,我们想保证hi·vi的数值接近目前已观察到的次数。

-
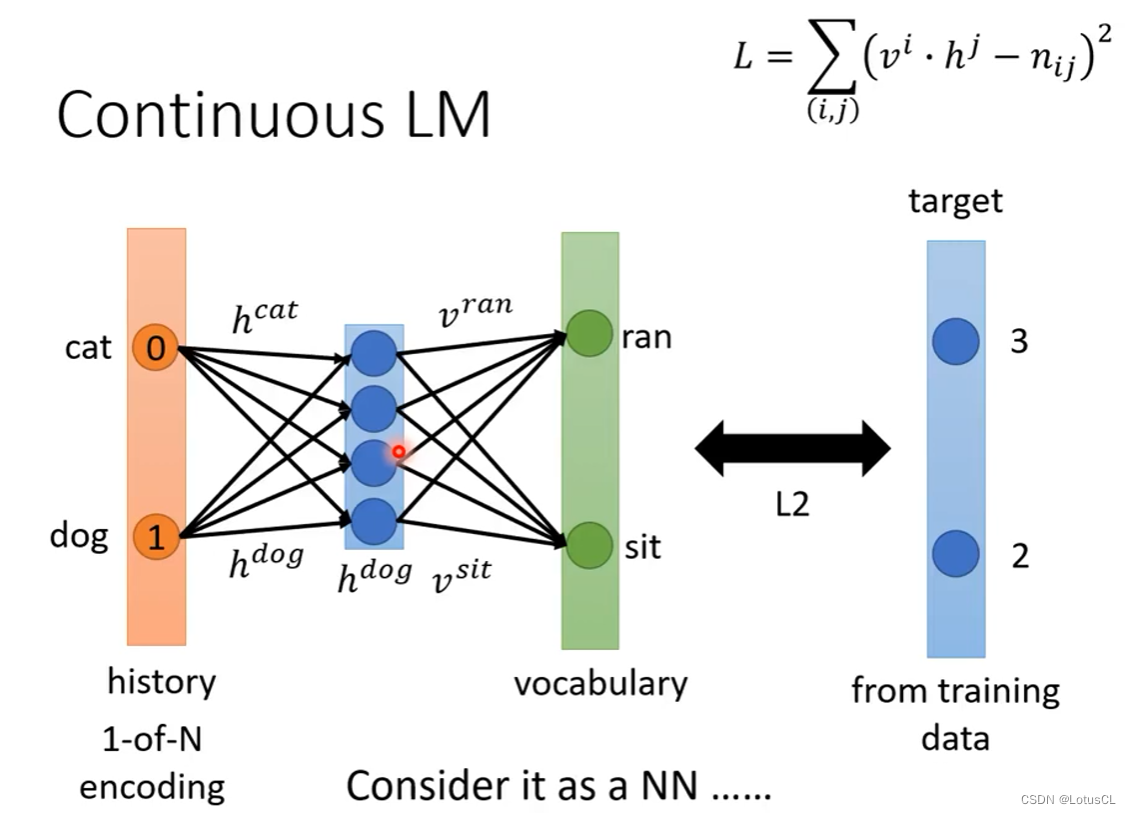
然后我们就用向量的乘积来替代原来观察的次数。通过这种方式,它就会自动把0补成学到的参数。由于 dog 和 cat 与其它很多词有类似的共现关系。即便没有见过 dog jumped,但知道 cat jumped,它也会自动学出 dog 和 jumped 的关系。
-
而进一步的,我们也可以将这个过程想象成只有一个隐藏层的神经网络,输入的就是 one-hot vector(独热向量),dog对应维度为1,隐藏层就是词汇的向量表达,输出就是后接词汇的类distribution。由此我们就可以引出 NN-based LM
-
NN-based LM
其做的事情和上面我们引申的 Continuous LM 相同,就是训练一个 NN。
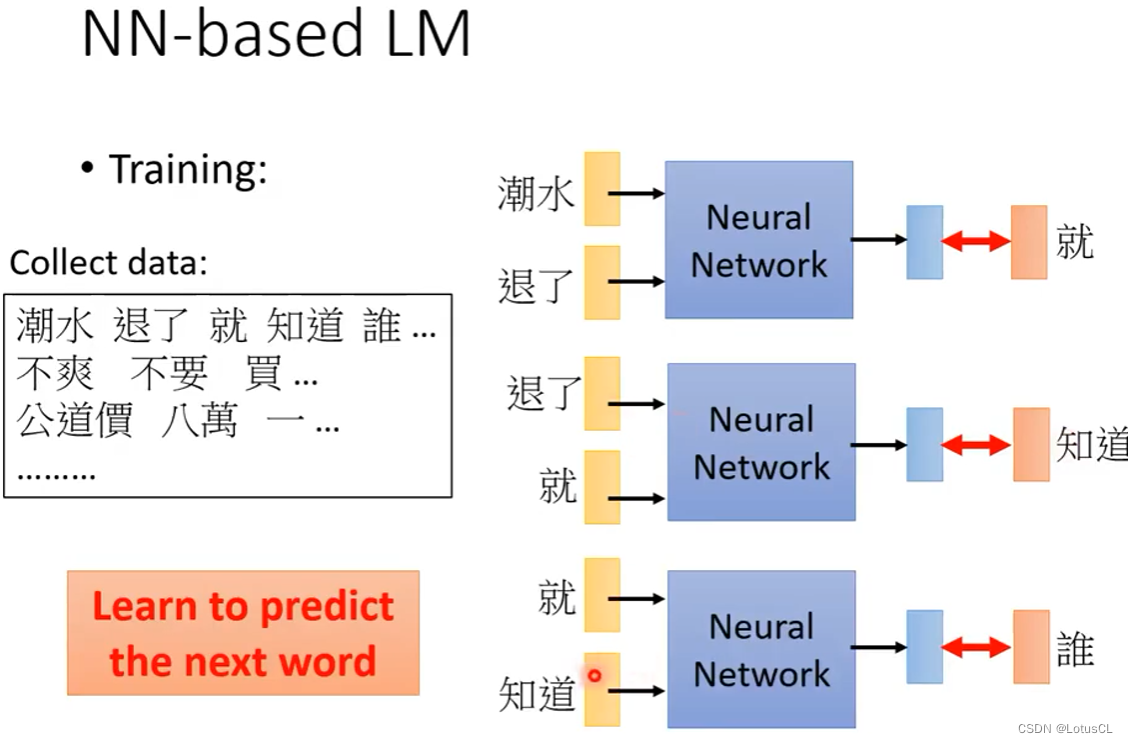
训练完成后,我们就可以使用这个LM,对之前拆分的概率公式中的各项进行计算。
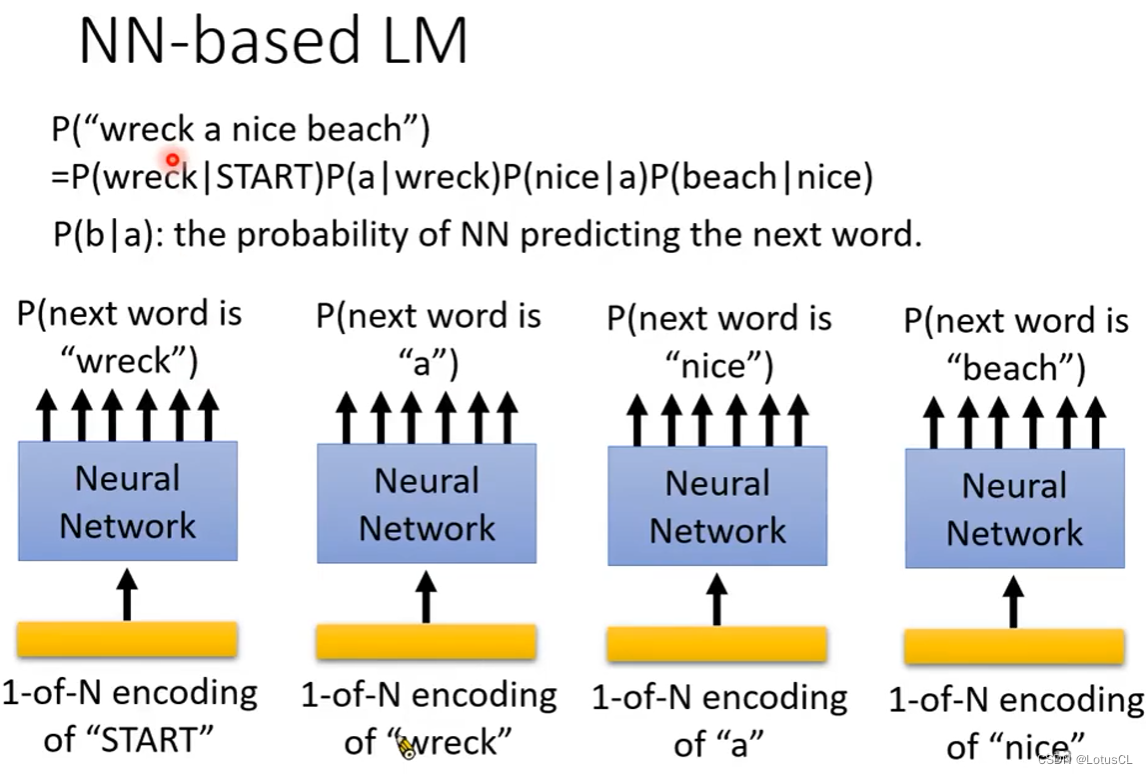
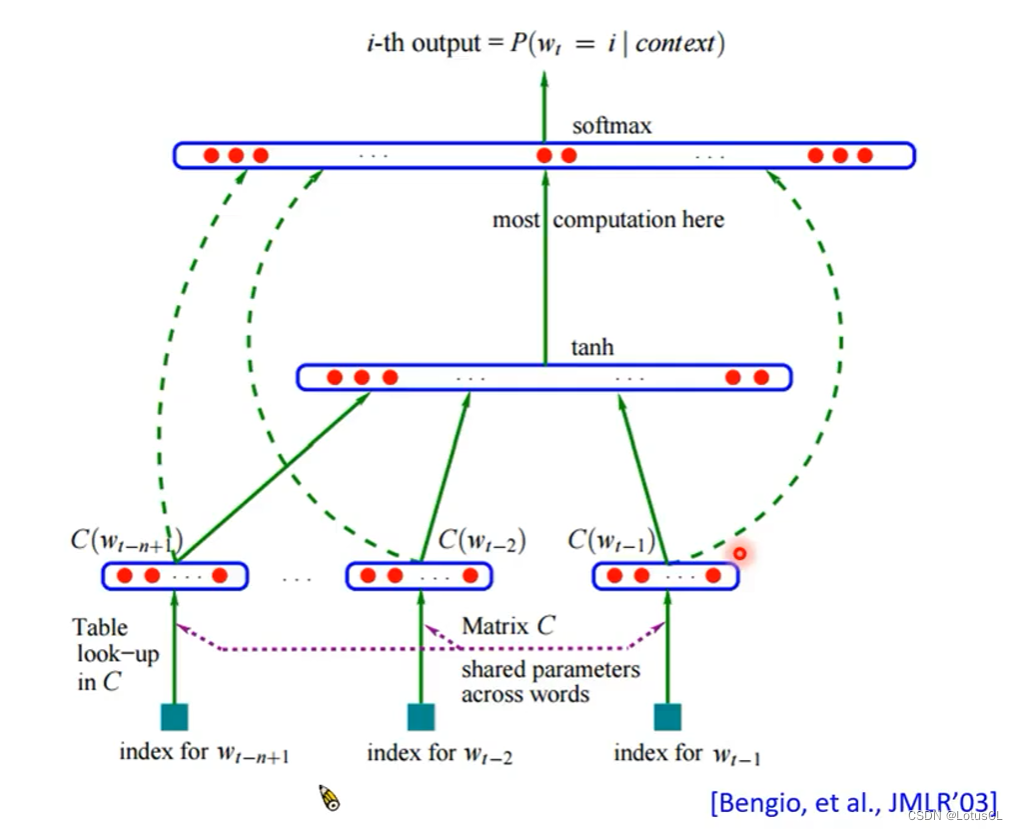
事实上,NN-based LM 其实出现得比 Continuous LM 还要早。在Continuous LM变得流行之后,才有人把 NN-based LM 找出来。之后随着深度学习崛起,才变成了现在的主流。在2003年,超过15年前发表的文章,Bengio 就有提到过 Word embedding 的概念。它有把中间的参数层可视化出来,就像我们现在看到的词嵌入类比实验可视化一样。
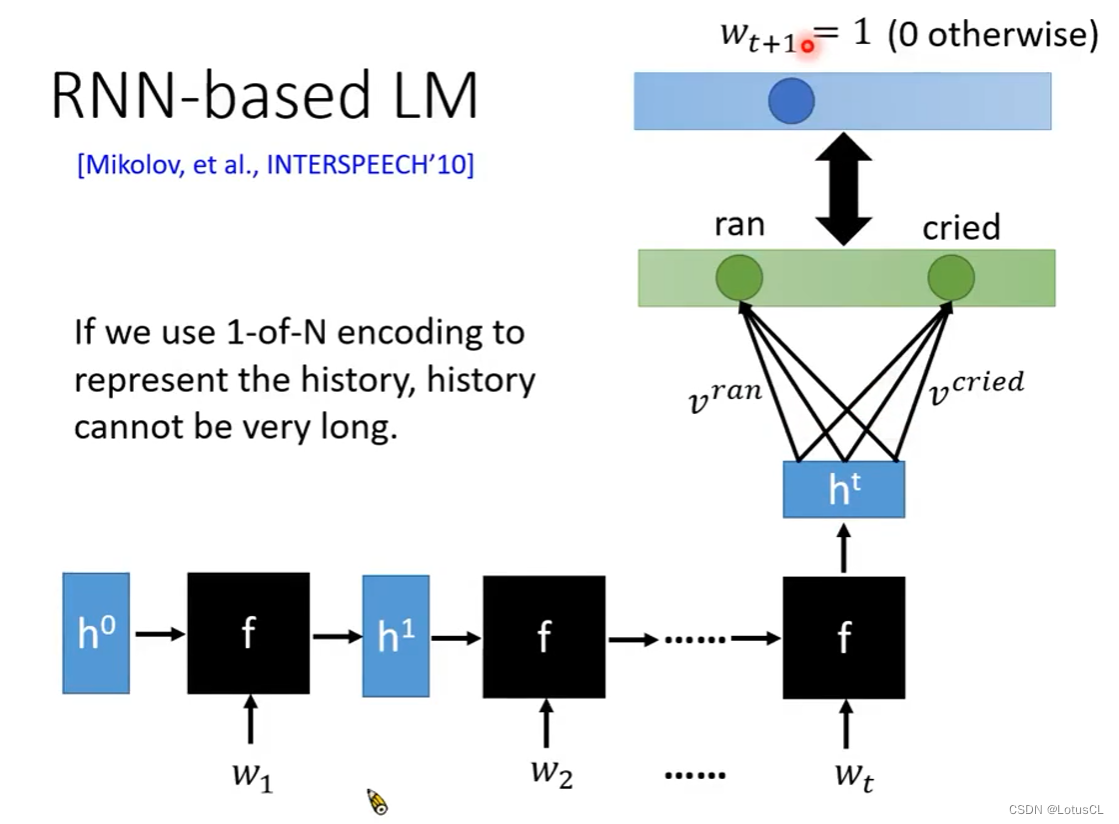
RNN-based LM
有的时候我们需要选取前面词汇更多的情况,也就是5-gram,6-gram甚至更多,这会导致NN的输入序列过长。于是便有了 RNN-based LM 。这样有多长的gram我们就可以做多少。
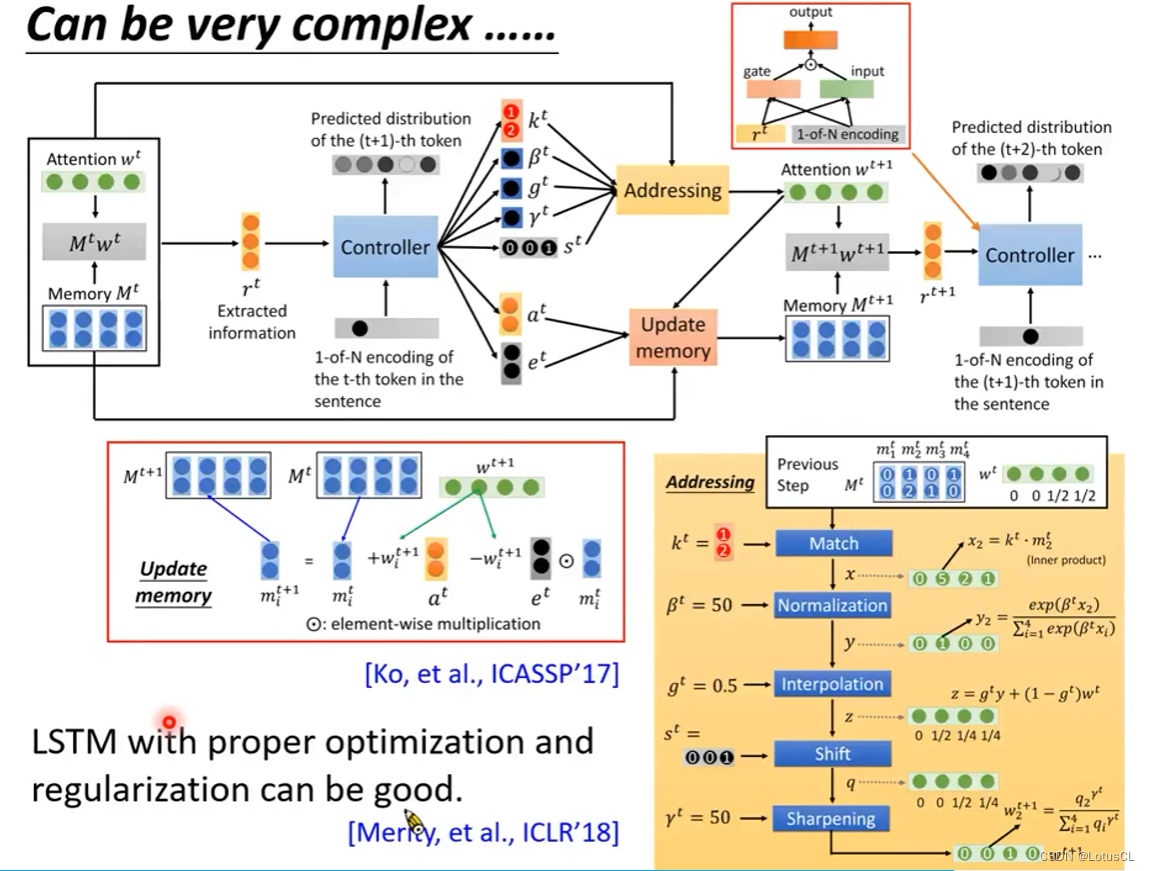
RNN 有各式各样的变形。曾经人们的想法是,把 RNN 尽可能地做复杂,看能不能做出更强的语言模型。甚至还有人用 Nerual Turning Machine 改一改来做语言模型。近几年也有研究表明,LSTM 加上合适的优化器和正则项就可以表现得很好。也不见得需要用非常神妙的奇技淫巧。
三、如何使用 LM 以改善 LAS
我们要将 LM 和 LAS 相结合。首先我们根据结合的位置和时间来对结合方式进行分类:
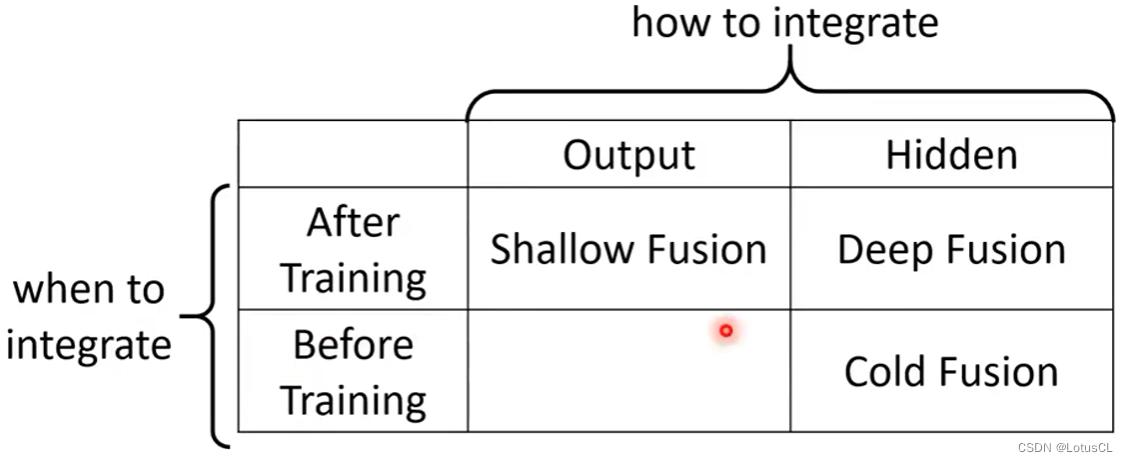
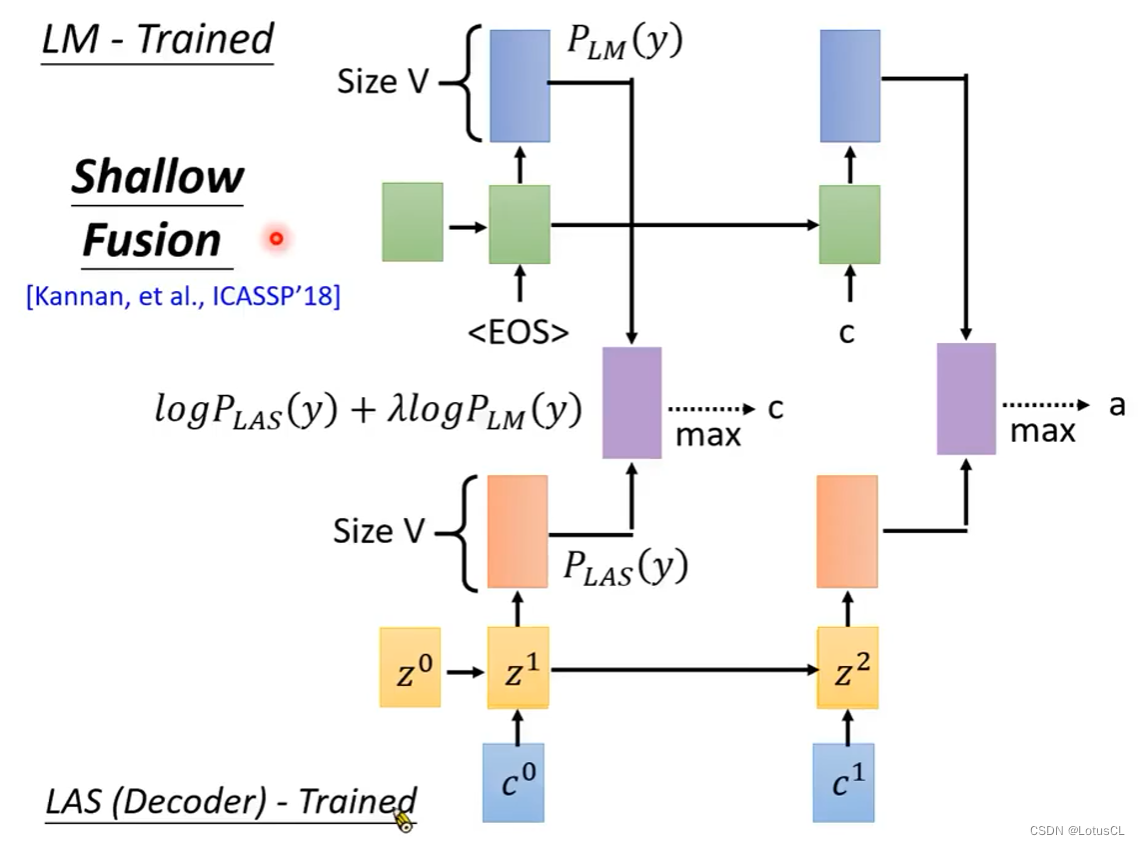
Shallow Fusion
这种结合方式非常符合直觉,就是将训练好的LAS和LM算出来的概率取log并进行相加(可以带权重),然后进行束搜索等方式找到最大值并采用。
Deep Fusion
这个是深度融合,也就是将隐藏层的内容拿出来,通过一个Network进行混合,来预测最终的概率分布。示意图如下。因此在采用这种方式的时候,我们还需要对这个用来混合的Network进行训练。但是这样问题也随之而来。就如图中所说,我们无法随时切换我们的 LM。因为不同的LM的隐藏层的每个维度所表示的含义可能都不同。因此我们要是切换LM就需要重新训练用来混合的网络。
什么时候需要我们切换LM?就是当我们在面对不同领域(domain)的发音的时候。比如城市和程式发音相同。如果是工业领域,则城市的概率更高;如果是数学领域,可能就是程式的概率会更高。后续应用中,我们甚至可以针对一个人来做LM,根据这个人的常用词来做个性化的LM。
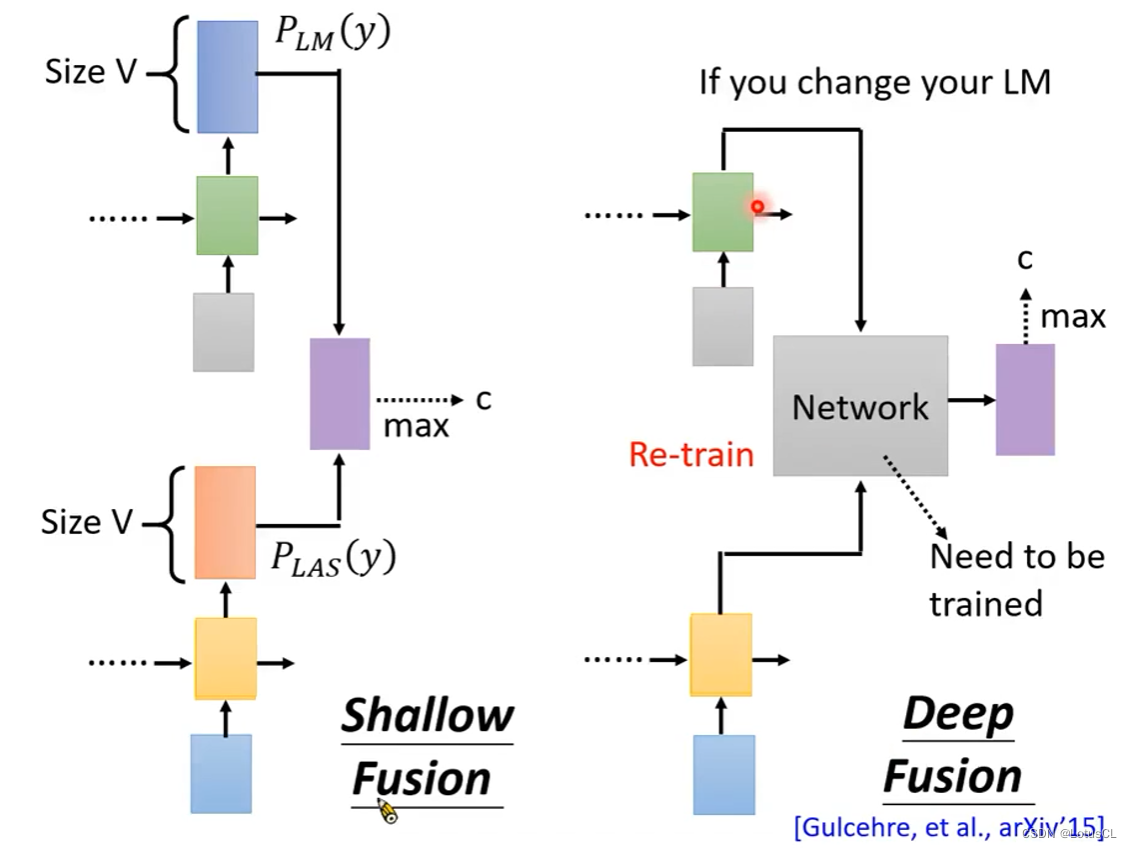
不过我们也有一个解决方案,那就是可以把语言模型在Softmax之前的输出,得到一个它的维度和词表大小V一样大的向量,再喂给神经网络。这样做的好处是,我们可以随时更换我们想要的语言模型。 为什么呢?因为这个灰色的神经网络可能学到的是,看到有什么样的token,要怎么和LAS的输出整合起来。就算是换了语言模型,它还是会输出一个token的概率分布。对一个语言模型来说,在这个词表大小V的向量中,每个维度的意义都是一样。但对不同的语言模型来说,则不一样。对于灰色的神经网络来说,每一维的概率分布,都是对应相同的token。即便是换了语言模型,这一点也不会变。并且这样还有一个好处,那就是你可以不必要使用NN-based 的 LM,传统的 LM 没有隐藏层,但同样也能提供token的概率分布。

然而,这样做也有一个坏处,如果你的vocabulary size,也就是词表大小v很大时,比如采用word作为token,那么得出的向量维度就会很高,就不太好这么做。但如果采用的token的v比较小,比如用字母等作为token,那么就可以这么做。
Cold Fusion
冷融合则与上面两个融合方式不同。这个融合是在LAS尚未完成训练时加入的。也就是在当前环境下,LM已经训练好,但是LAS还未完成训练。我们像Deep Fusion那样将二者相结合,然后再一起训练。
这样做的好处是可以大大加快LAS的训练。因为此时LAS就可以不用去在意LM能够做到的事情,而专注于语音到文本的映射。
也有一定的坏处,那就是这回是真的不能随便换LM了,一换就需要重新训练LAS。在Cold Fusion中,LM自LAS出生时就已经存在了,做一个引导成长的作用。因而切换LM,那么LAS也需要重新成长。
