参考文献:
Speech Separation (1/2) - Deep Clustering, PIT哔哩哔哩bilibili
2020 年 3月 新番 李宏毅 人类语言处理 独家笔记 Speech Seperate - 12 - 知乎 (zhihu.com)
Speech Separation (2/2) - TasNet哔哩哔哩bilibili
2020 年 3月 新番 李宏毅 人类语言处理 独家笔记 TasNet - 13 - 知乎 (zhihu.com)
本次省略所有引用论文
目录
Scale invariant signal-to-distortion ratio(SI-SDR or SI-SNR)

五、Permutation Invariant Training(PIT)
六、Time-domain Audio Separation Network(TasNet)
一、介绍
-
鸡尾酒会效应:人类可以轻易从嘈杂的声音中(复合声音)专注在自己想听的声音上,将一个声音从其他声音中抽取出来。
"鸡尾酒会效应"是一个来源于信息理论和信号处理领域的术语,它描述了在多个源同时传输信息或信号时的混叠和难以分辨的现象。这个术语的背后涉及到信号混叠和信息交叉的问题,类似于参加拥挤的鸡尾酒会,你可能会听到多个人同时交谈,使得单个声音变得难以分辨。
-
分类:
-
Speech Enhancement:你在讲话,有很多其他杂音在干扰,如何增强你的声音
-
Speaker Separation:很多人在讲话,能不能把每个人的声音分离出来
-
-
Speaker Separation任务介绍:
-
主要任务:输出一段声音,输出多段声音,声音长度输入和输出长度相同(因此不需要使用Seq2Seq模型,因为Seq2Seq模型集中解决的任务是输入和输出序列长度不同)
-
我们接下来的研究内容基于以下条件:两个语者、单个麦克风、训练与测试语者不同
-
声音数据很好收集,我们直接将两个不同的人声混合在一起就可以成为训练数据。
-
二、Evaluation(评价指标计算)
对于声音转换(切换音色),我们没有ground truth,因此不太好评估。但是对于语音分离任务,我们是有ground truth,也方便做客观评价,即计算模型输出和真实数据的相似程度。
Signal-to-noise ratio(SNR)
-
实际上,每段音频都可以视作是向量,因此就是去计算向量之间的相似程度。
-
SNR随之诞生。其公式如下:
其中,X_hat 为ground truth 声音向量,X^*为模型输出声音向量,E为二者之差。那么照这样来看,二者越相似,则SNR数值越大。
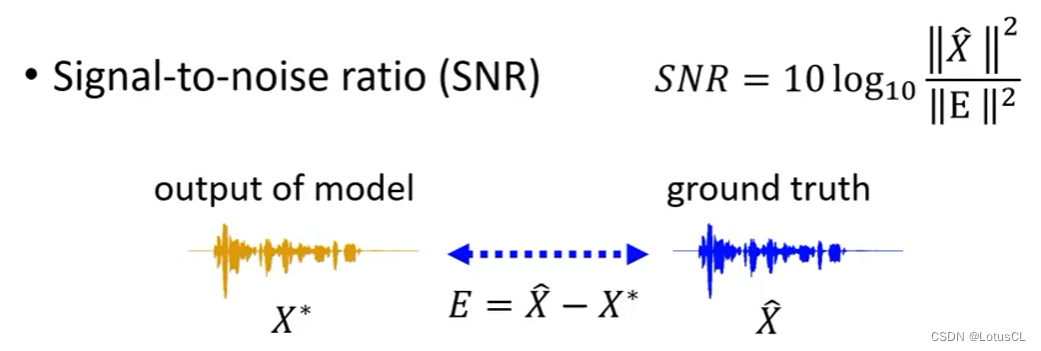
-
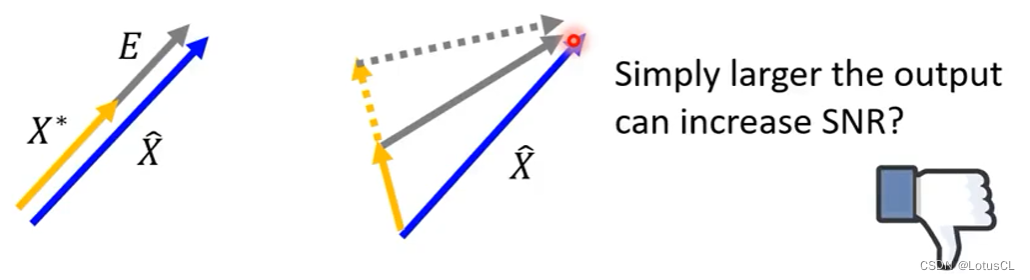
然而,这样的计算方法也是有问题的。譬如下面两种情况,第一种情况方向相同,理论上效果很好,但是因为声音很小,二者差值的模长大,因此SNR就小;第二种情况则是方向不同,不过我们可以仅仅是增大音量,就能让SNR变大。
Scale invariant signal-to-distortion ratio(SI-SDR or SI-SNR)
-
这相当于SNR的进化版本。公式如下:
其中,X_T 为模型输出向量在ground truth向量方向上的投影向量,X_E 则为模型输出向量在垂直于ground truth向量方向上的投影向量。
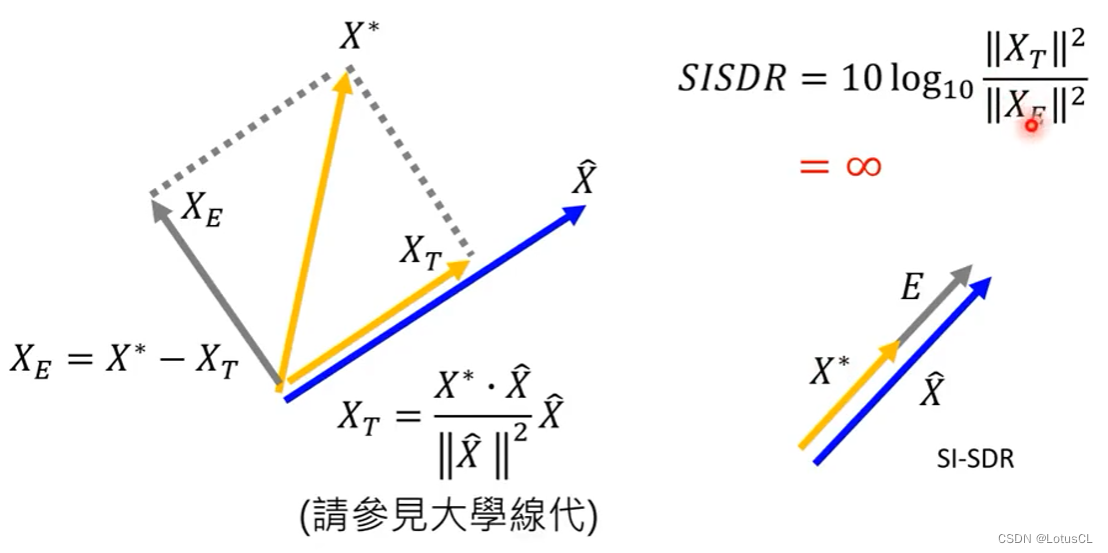
-
这很好的解决了我们刚刚说的两个问题。
-
实际上,这个评估指标还可以再改善。我们为了防止本来输入的声音讯号就接近分离的情况,于是做出了改善,即后面的 SI-SDRi:
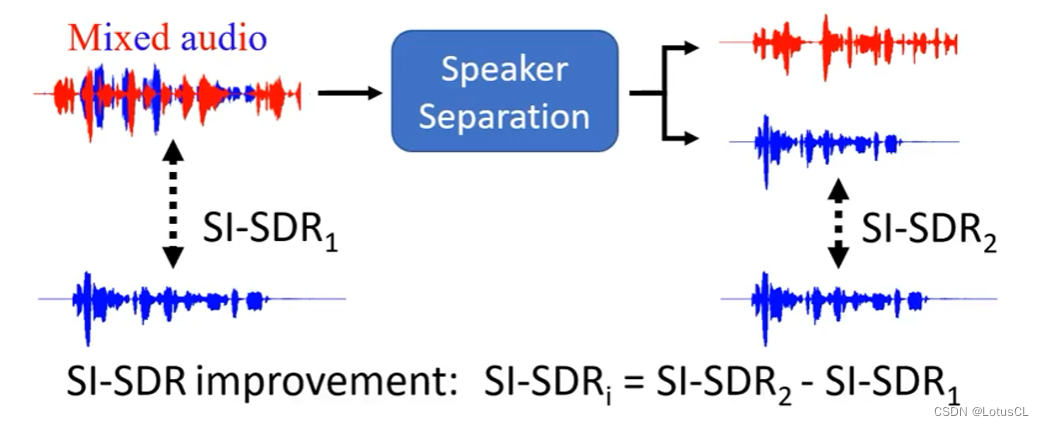
-
这是在计算分开结果的 SI-SDR 减去 正确输出与未分开结果的 SI-SDR。
-
这样可以轻松得到声音讯号在经过模型之后的改善情况。
-
其他(不再讨论)

三、Permutation Issue(样本排列问题)
-
如果输入是混合的声学特征,输出的声学特征矩阵可以与Ground Truth 计算 L1 或 L2 距离作为损失。若模型很强,可以直接输出波形,我们甚至都可以用 SI-SDR 计算损失。好像很简单?
-
但是,我们很容易遇到一个问题:你凭什么在训练中,把模型输出的上面的声音规定为语者1?下面的规定为语者2?这个正确答案的排列问题将直接决定整个训练过程。
-
能否根据声音的特征,如性别、声调等来进行排列?不行!因为不确定因素太多了。
我们的训练语料中有各种各样的人声,若指定模型为一种顺序输出,显然是不合理的。我们假设蓝色是男声,红色是女声。我们输入男声和女声混杂的声音,模型学会了女声在上面,男声在下面。但另一段混合声音中,绿色的是女声,黄色的是男声。这时模型有可能也学到男声在上面,女声在下面的组合。哪怕我们按照性别分开,规定把男声放上面,女声放下面。但这也不见得完全解决问题。因为你还要基于多一个准则去把男声女声分类。这个准则可以是音调,或音色。但音调高的未必就是女声。能量饱满的也未必是男声。你可能还会想到,根据音调去做人声分离,音调高的输出 X1,音调低的输出 X2。但这种方法对于两个音调差不多的人声混合,就很不友好。所以要让分离出来的人声位于 X1 还是 X2 其实是一个大问题。

四、Deep Clustering
-
最早使用深度学习来做Speaker Independent的分离任务的就是 Deep Clustering。实际上,我们回顾之前定义的语音分离任务,它其实就是输入一个声音矩阵,输出两个声音矩阵。如果你使用深度学习也这么做,其实就是杀鸡用牛刀,因为你的输入和输出其实是非常相似的,往往是输入减去一些东西就成了一个输出。

-
于是我们需要把它用另外一种思路去思考。模型不是直接产生新的声音,而是产生一个 MASK。MASK 是一个和输入一样形状的矩阵。我们把 MASK 与 X 做点乘就能得到要分离的人声。这是一个在 Speech Seperation 中常用的设计。
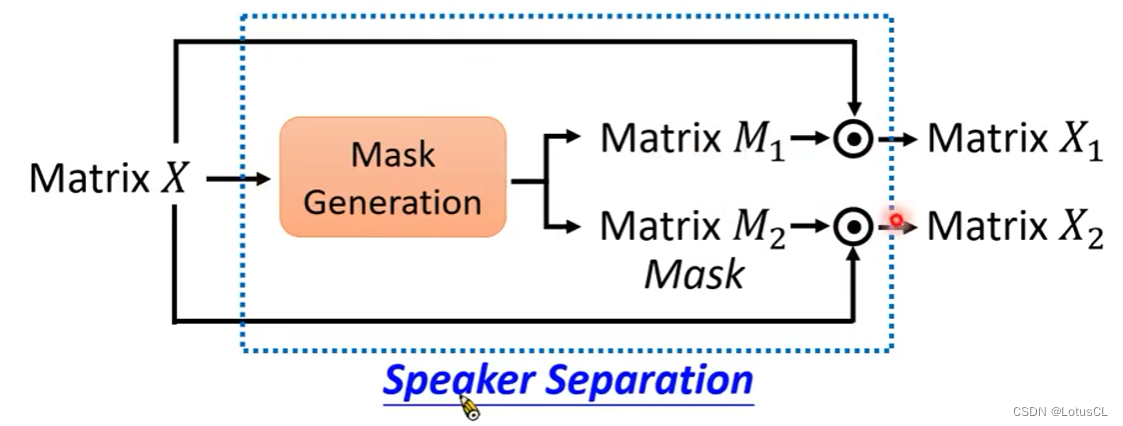
-
而有意思的是,MASK 可以是 Binary 的(只有0和1),也可以是 Continious的(使用连续的值)。
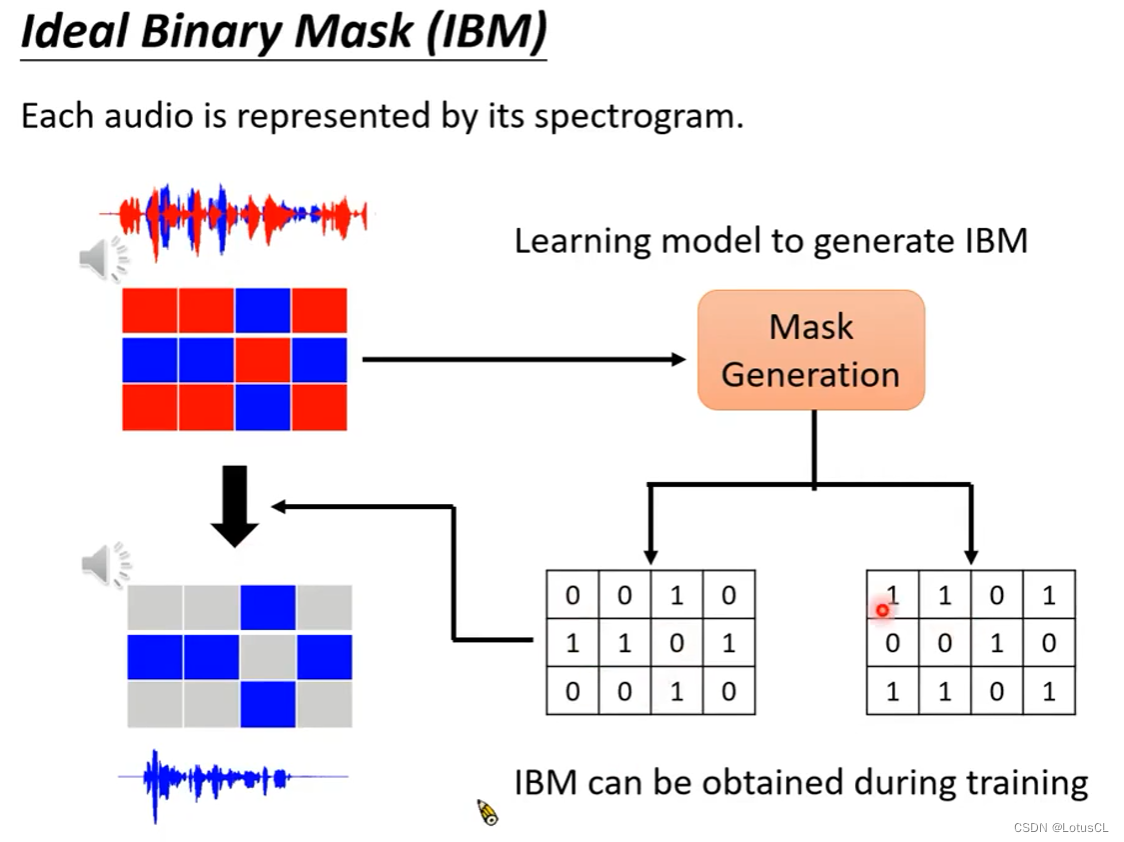
Ideal Binary Mask(IBM)
-
我们来看看使用 Binary Mask 的典型例子:IBM。
-
首先,我们如何得到这个IBM呢,很简单,在混合两个声音矩阵时,哪一个声音矩阵在同一个位置的声音大(即数值大),我们就在对应Mask,将其设为1,其余所有声音 Mask 都设为0。

-
这样,在使用Mask点乘混合语音后,滤除来的就是蓝色的声音。是的,只保留了蓝色矩阵,而其他的全都是0。实际效果如何?其实很好。
-
然而,bug在于,我们要做的是语音分离,我们并不知道原始的语音谁大谁小,如何获取IBM成了问题。因此真正实操的时候,我们要让模型(Mask Generation)去生成出一个 IBM。这个 IBM 在有 Ground Truth 的时候,可以轻易得到理论上的 IBM 来作为训练标签。由于生成的 IBM 是二元的。我们只需要生成其中一个声音的 IBM,就可以知道另外一个 IBM。因此 Permutation Issue 就迎刃而解了。
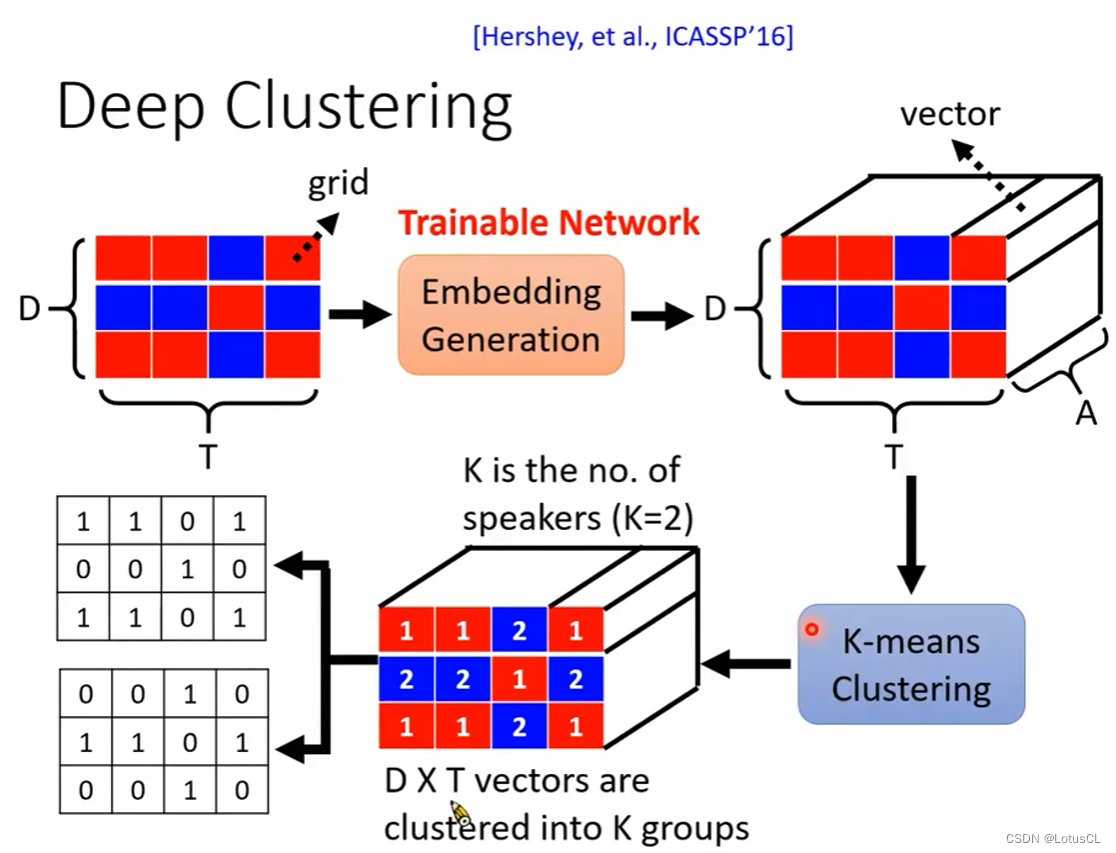
Deep Clustering
-
Deep Clustering 是怎么做的呢?我们先关注它是如何使用的。其关键部分在于 Embedding Generation,它能输入一个二维的声音向量,输出一个三维的新向量。也就是将原来的每一个格子扩张成一个向量。然后我们对这些向量做 K-means 聚类,这样,同属于一类的,其mask就规定为1,其余格子为0即可。
-
不过,K-means 由于是固定的算法,而无法进行训练,所以我们只能对 Embedding Generation 进行训练。那么我们应该如何训练?
-
首先我们需要明确训练的目标。相同的Speaker我们希望被归类为同一个cluster,根据K-means聚类算法,也就是生成的向量距离要近,而不同的Speaker的格子我们希望生成的向量距离要尽可能远。因此我们可以先基于混合声音的标签,找出它的 IBM。接着,我们根据 IBM 中的0 和 1 的位置来决定嵌入生成器的输出向量,在同样位置拉远还是拉近。
-
神奇的是,由于K-means的存在,我们可以设定聚类的数量,也就是说可以训练多人人声混合,这个模型在多人人声分离的任务上同样有效。
牛的是,这篇论文还做了现场的 DEMO。他们现场找了两名观众同时说话,结果模型能够很好地分离出他们的声音。DC 唯一美中不足的是,它没有端对端。中间有 K-means 操作。
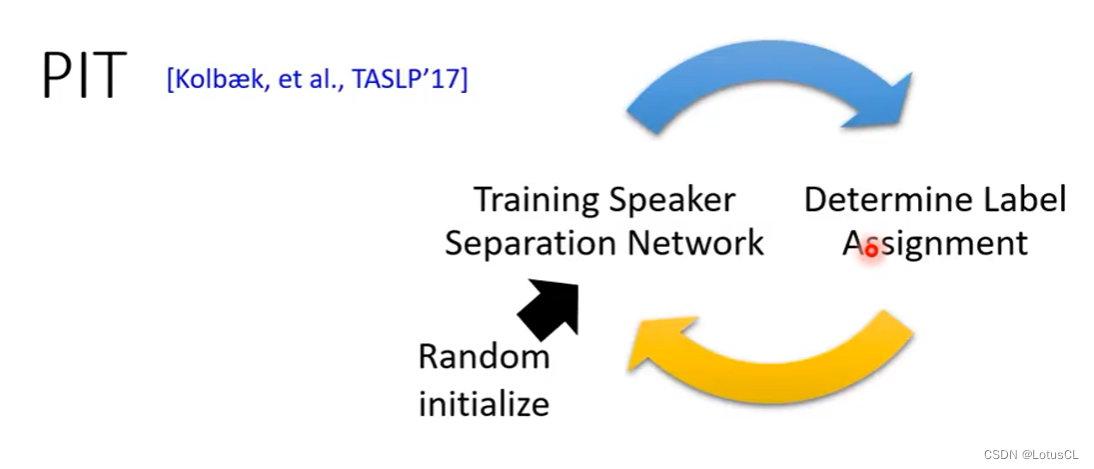
五、Permutation Invariant Training(PIT)
-
腾讯家开发的,使用这个就可以真正进行端到端的训练,弥补Deep Clustering的遗憾。其思想很简单,就是将 Ground Truth 的排列方式全都算一遍 Loss,哪种排列方式的Loss小,哪种就适合这个模型。不过前提是我们有现成的Separation Model,才能算Loss。
-
因此我们在初始化后,先随机给一种排列方式,训练出第一轮的模型,然后就可以进行循环往复的【计算Loss、比较大小、更新排列方式、再训练】,这就是PIT。
-
那么理所应当的,这种方法能最终收敛下来吗?答案是可以滴。这是老师做的结果,如图所示,蓝色线为模型随着迭代增加的准确率,它是很稳定的。而黑色线为这一次排列和上一次排列不同的比例。它在前期是很不稳定的,但随着模型的收敛,它也渐渐收敛。
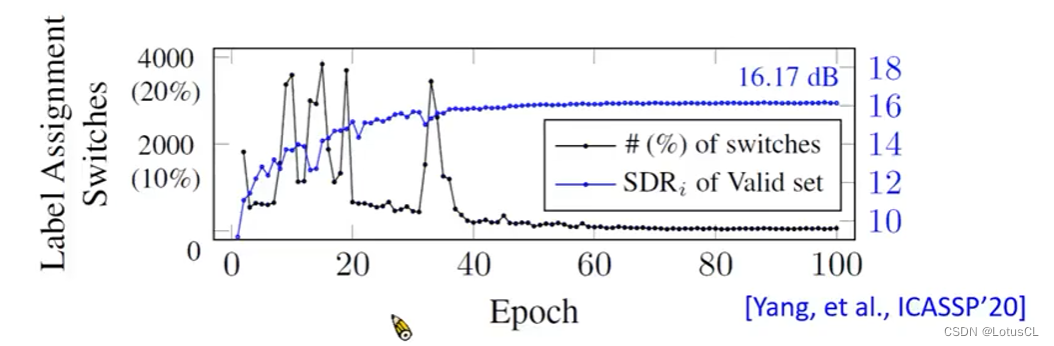
-
我们也可以拿PIT去比较其他方法。在下图中,a为基于声音的音量排列,b基于语者特征排列,而PIT很明显都比它们好。还有一个神奇的操作,我们拿最终收敛的最佳的PIT的排列方法,去作为排列的初始化重新使用PIT训练一个新的Network,最终的训练结果会更好,再套个娃,结果还会更好。
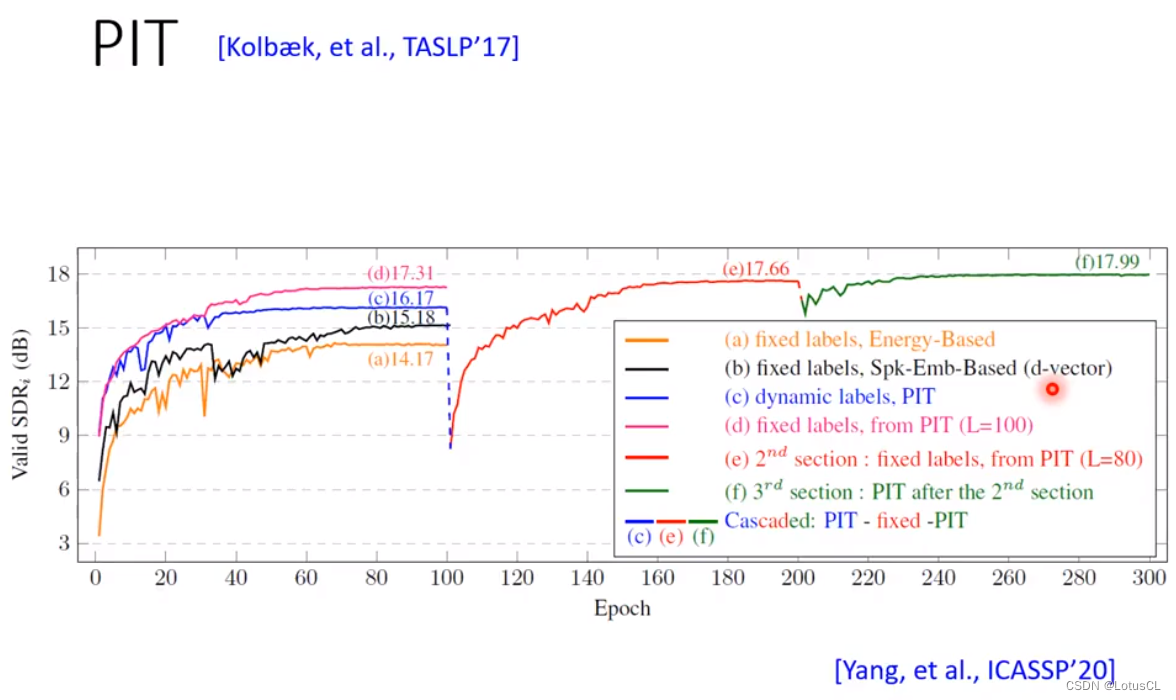
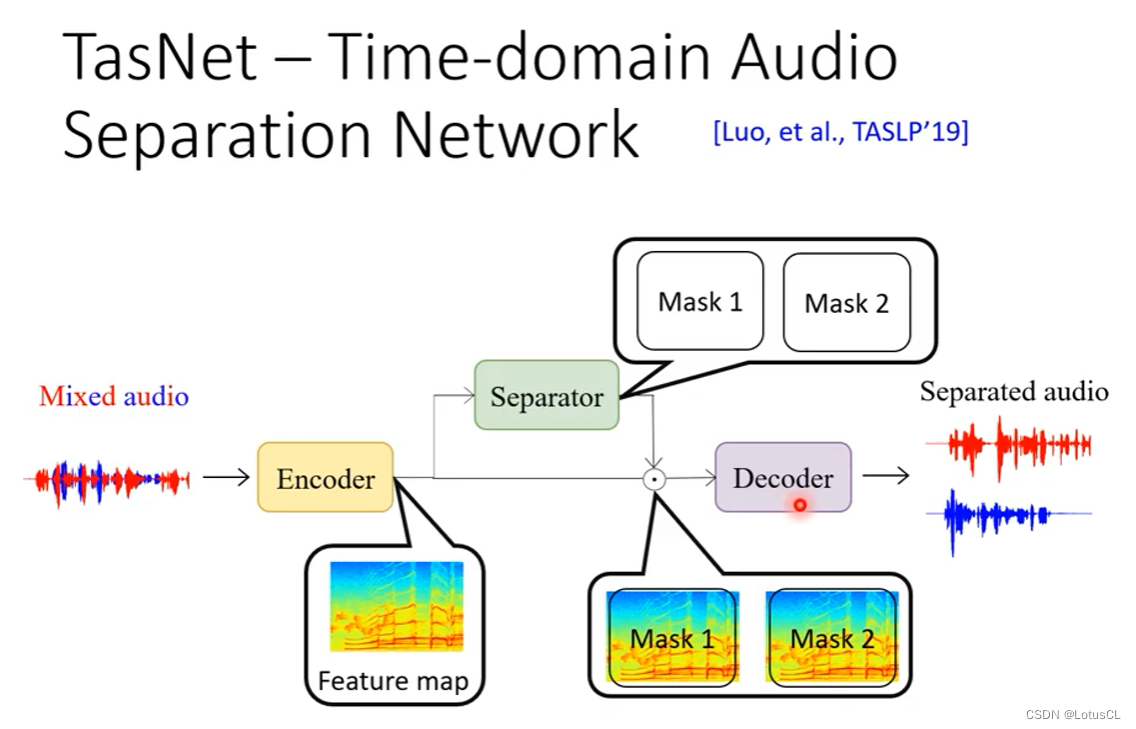
六、Time-domain Audio Separation Network(TasNet)
-
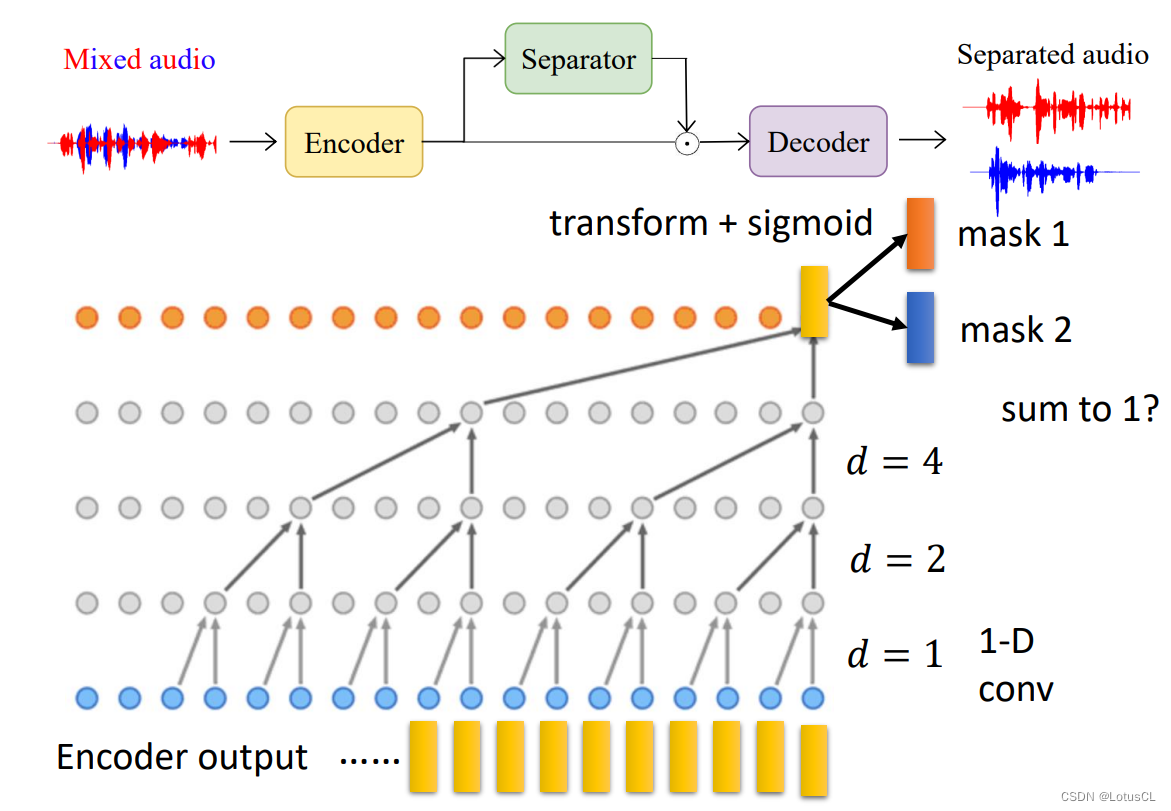
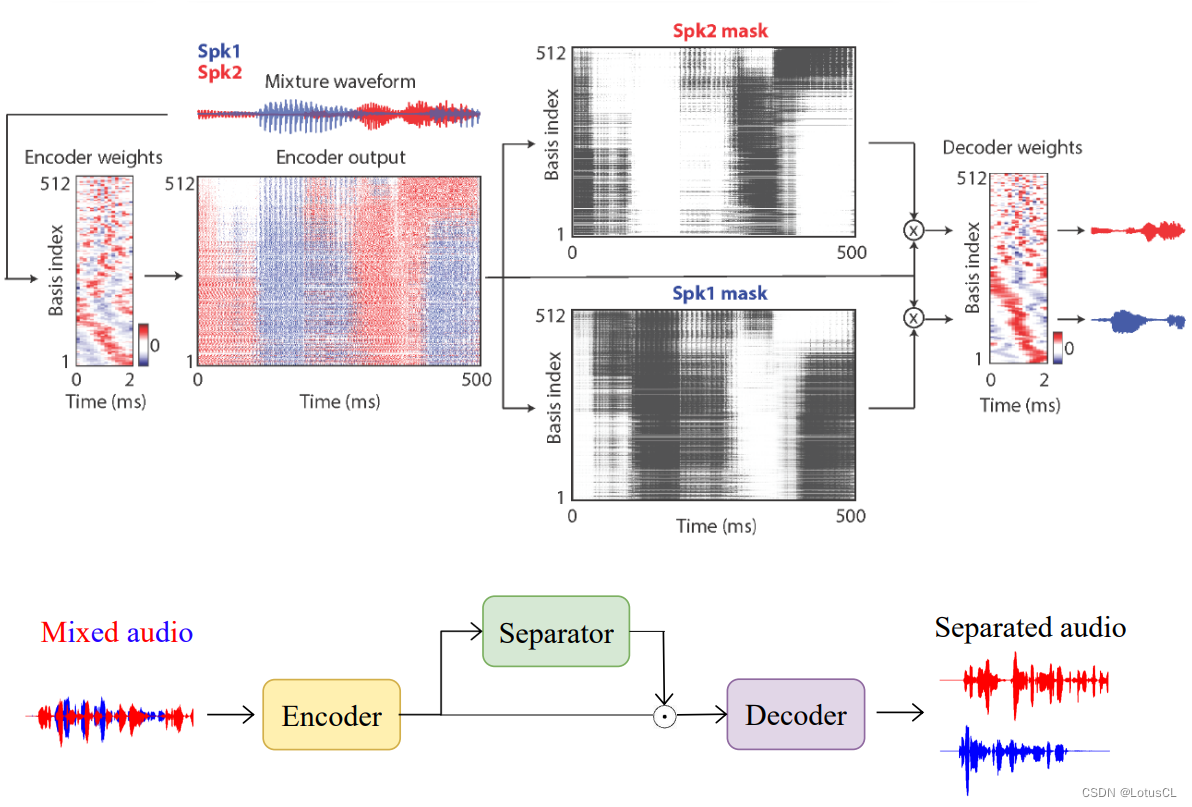
简单阐述对应结构,TasNet 由 Encoder,Separator 和 Decoder 三个部分组成。其输入是直接的声音波形,输出还是声音波形。输入的这串波形是一串非常长的数值。编码器会把这串波形变成一个特征矩阵。与声学特征矩阵用模板产生的不同。这里的编码器模板是学习出来的。特征矩阵喂给 Separator 会输出两个 MASK,分别乘在特征矩阵上,再分别通过解码器来获得输出波形。训练的时候,考虑到 Pemutation Issue,它是需要用到之前讲的 PIT 的技巧。
Encoder 与 Decoder
整体的示意图如下:
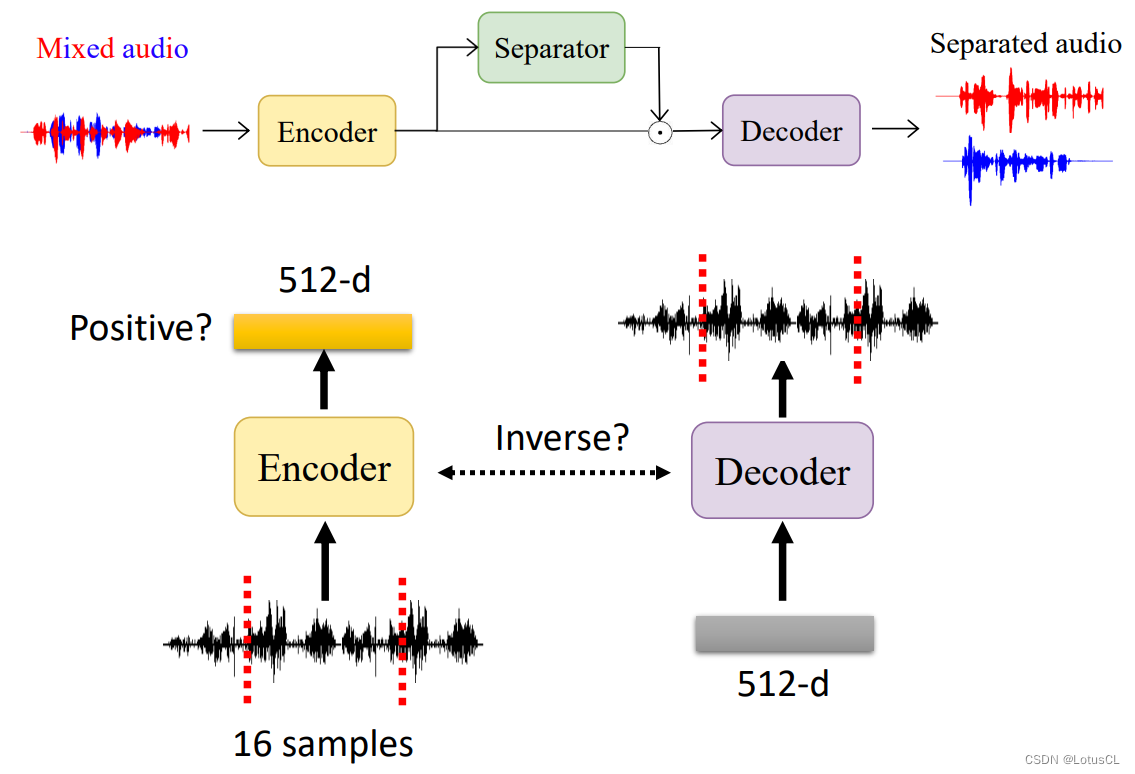
-
Encoder:
-
就是一个权重矩阵
-
输入是一段非常小的声音信号,只有16个采样,即16维的向量。通过 Encoder 之后,会产生一个 512 维度的向量。
-
需要输出为正吗?加一个ReLU?结论:效果不好!
-
最后学习出来的样子:
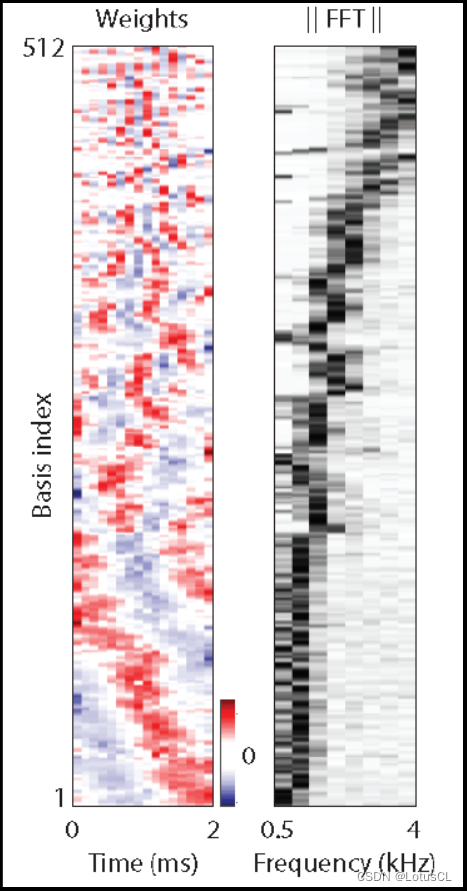
Match Filter(匹配滤波器):匹配滤波器是一种信号处理滤波器,用于在信号中检测特定的预定义模式或信号特征。在音频处理中,匹配滤波器可以用来检测或增强特定频率成分,通常与频谱分析有关。它可以用于提取或强调信号中的特定频率信息,例如语音信号中的声音成分。
Phases(相位):相位是指信号的周期性变化,它通常是一个周期性波形的周期性特征。在音频信号中,声音波形的相位描述了振荡的周期性变化,通常以角度或弧度表示。不同相位表示不同的周期性状态,这在音频信号的频谱表示中很重要。
basis(基础元素):在声音信号处理和信号处理中,"basis" 通常指的是一组基本函数或基础元素,用于表示和分解复杂信号。这组基础函数可以用来构建或表示信号的结构,通常用于分析和合成信号。
-
可见,x轴就是16 samples(2 ms)
-
y轴,有512个维度。每一行(row)就是一个basis,也就是所谓的一个个match filter。
-
我们从热力图中可以看出,每个filter都在过滤不同的内容,也就是会编码不同频率的信号,有高频的有低频的。低频的 phases 会比较多,因为人声在低频部分比较多。同样,Encoder也将 phases 信息给编码了进去。(以前我们在做完傅里叶变换后就会把 phases 信息丢掉)
-
-
-
Decoder:
-
也是一个线性映射权重矩阵
-
吃一个 512 维的向量,转回为 16 维的声音信号。
-
需要是Encoder矩阵的Inverse吗?结论:效果不好!
-
Separator
WaveNet:WaveNet 是一种深度学习模型,特别是一种深度卷积神经网络(CNN)结构,用于生成音频波形数据的模型。它被广泛用于音频合成、语音识别、音频增强和其他音频处理任务。
扩张卷积神经网络(Dilated Convolutional Neural Network,DCNN):传统的卷积操作是通过在输入特征图上使用固定大小的卷积核进行滑动操作来提取特征。而扩张卷积引入了一个新的参数叫做扩张率(dilation rate),用来控制卷积核中元素之间的间隔。通过调整扩张率,可以在保持卷积核尺寸不变的情况下增大感受野(receptive field),从而可以更好地捕获输入数据中的远距离依赖关系。
深度可分离卷积(Depthwise Separable Convolution,DSC):是一种卷积神经网络中常用的卷积操作,它可以在保持较好的特征提取能力的同时,大幅减少模型参数量和计算量。DSC 主要由两部分组成:深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。深度卷积阶段对每个输入通道进行独立的卷积运算,而逐点卷积阶段则使用 1x1 的卷积核对深度卷积的输出进行线性组合,以得到最终的输出特征图。
长短期记忆(Long Short-Term Memory,LSTM):是一种常用于处理序列数据的循环神经网络(Recurrent Neural Network,RNN)的变体,它能够有效地解决传统 RNN 在处理长序列数据时的梯度消失和梯度爆炸等问题。LSTM 通过引入门控结构来显式地保存和更新输入序列中的信息,从而更好地捕获长期依赖关系。LSTM 单元中包括了三个门:输入门(input gate)、遗忘门(forget gate)和输出门(output gate),以及一个单元状态(cell state)。这些门控结构能够根据当前输入信息和上一时刻的状态来控制信息的流动,使得网络可以有选择性地记忆和遗忘信息,从而更好地处理长序列数据。
-
采用经典 WaveNet 架构,有很多层的 1-D CNN。同时,也采用了扩张卷积神经网络(Dilated Convolutional Neural Network,DCNN)。
-
第一层 CNN 会把相邻两个向量一组,用 filter 变成一个向量。相当于当前向量往左跳一步的邻居。第二层 CNN 会把跳格相邻的向量变成一个向量。相当于当前向量往左跳两步的邻居。第三层 CNN 则是把当前向量往左跳4格的邻居,用 filter 变成一个向量。第四层则是跳8格的邻居。
-
最终得到的vector就包含了很多信息。它会接上一个线性映射(transform),再通过 sigmoid (将值转为0~1)得到两个 MASK。
-
需要将两个mask的对应位置的值和为1吗?结论:不需要!
-
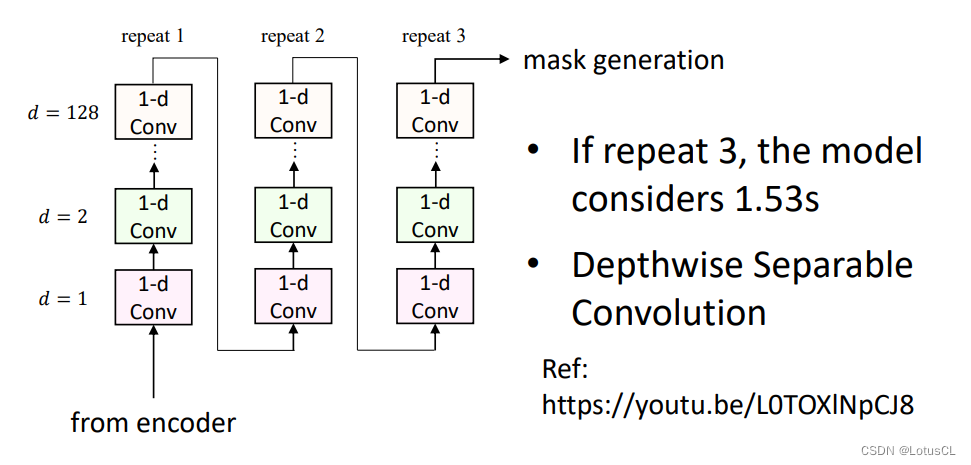
上面的只是separator的一小部分,真正的 Separator 有更多的 CNN,有更多的循环操作。

-
为什么需要反复用这么多的 CNN 呢?因为如果 CNN 能反复更多次,就可以看到更长的信息。比如像经过下面示意图的3轮循环后,模型就可以看到 1.53s 的波形语音。
-
同时,这么多的CNN,其参数量将会很多。为了减少 CNN 的参数量,TasNet 采用了一个叫作 Depthwise Separable Convolution (DSC) 的技巧。
-
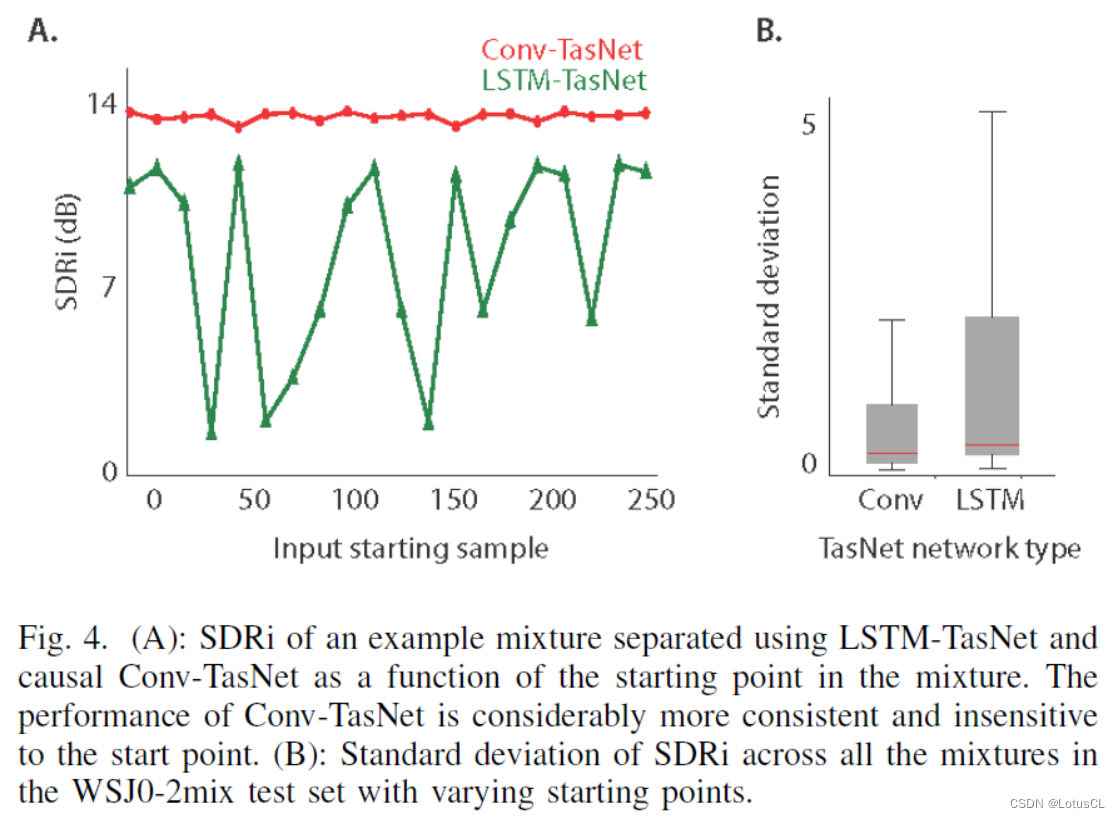
如今的 TasNet 的 Separator 采用的是卷积网络架构,有没有考虑过 LSTM 呢?早期的 TasNet 也有做相关实验,实验结果如下图。结果发现,LSTM 有些过于敏感了。如果我们把声音的前面一部分采样截掉,LSTM的表现会时好时坏。说明 LSTM 已经产生了过拟合(Overfitting),过拟合到,需要要从一个句子的开头读起才奏效。
-
但如果我们用 CNN,就不会有这个问题。为什么会这样呢?因为对于 CNN 来说,从哪个地方读起,根本无差。但 LSTM 开始的信息会影响很大。
总结与问题
-
Encoder 类似于 Fourier Transform(傅里叶变换),将声音信号转为类似 Spectrum gram 的东西,然后将输出丢到 Separator 中去,得到两个 Mask 。然后再将 Mask 与 Encoder 输出进行点乘,结果送入 Decoder中,Decoder在这里就类似于 Inverse Fourier Transform,最终就输出了声音片段。
-
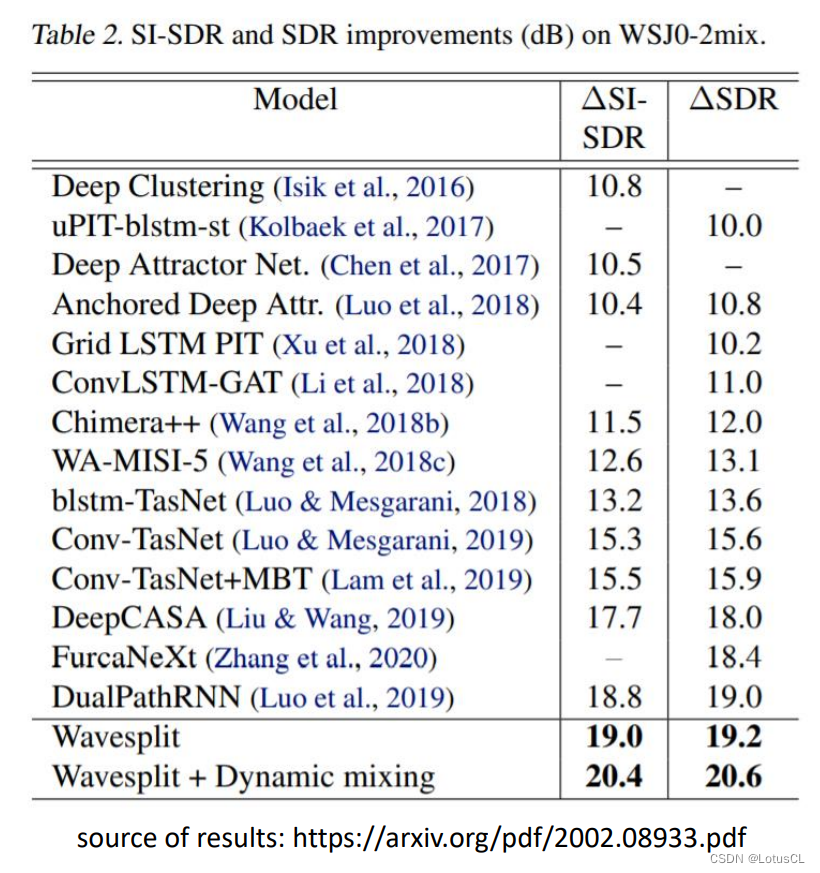
2020 年,今年还有一篇叫 Wavesplit 的论文。它在 WSJ0-2mix 数据集的 Benckmark 上获得了 SOTA 水平。TasNet 的水平在中间,15.3 左右。听起来已经是很接近完美的结果了。而 Deep Clustering 在 10.8 左右。今天看起来并没有很好,不过在当年出来的时候,是一个很惊人的结果。从数值上看,TasNet 似乎是把 Deep Clustering 按在地上摩擦。但真的是这样吗?
-
TasNet 还是存在着一些问题的。如果采用的是两个语者中英文混合的音频,TasNet 输出的结果就没有很好地把中文和英文分离。这是因为 TasNet 训练都是在英文人声的混合数据上做,因此产生了某种意义上的过拟合。反过来看 Deep Clustering,它却很好地做到了分离。很明显,从这个个例中可以看出,Deep Clustering 泛化性能好于 Tasnet。
七、Speech Separator 的其他探索内容
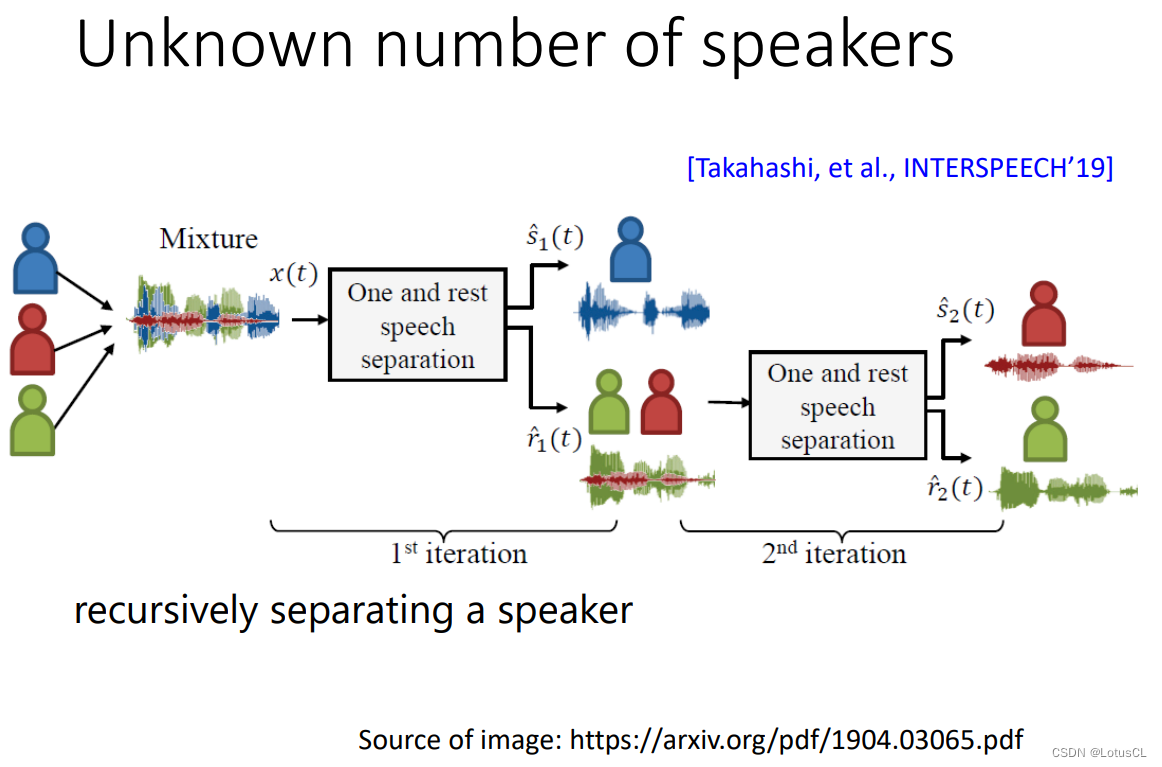
Unknown number of speakers
-
实际应用中,我们很有可能不知道混合的音频中有多少个语者。Deep Clustering 是有机会做到的。比如训练是两个 Speaker,但测试时 是三个 Speaker。但对于 TasNet 就没办法分离了。因为它能够输出几个 MASK 是预先设定好的。由此 TasNet 无法解决输入人声数量不固定的情况。
-
我们要怎样把 TasNet 这样的架构用在未知说话人声数量的情况中呢?一种方法是,训练一个网络每次只分离出一个人声。剩余的为背景声音。这样多个人声就可以通过递归地方式分离出来。不过这需要我们给一种方法检测我们什么时候可以停止分离工作。这不一定是最好的方法。怎样的方式最好,是值得我们去研究的。
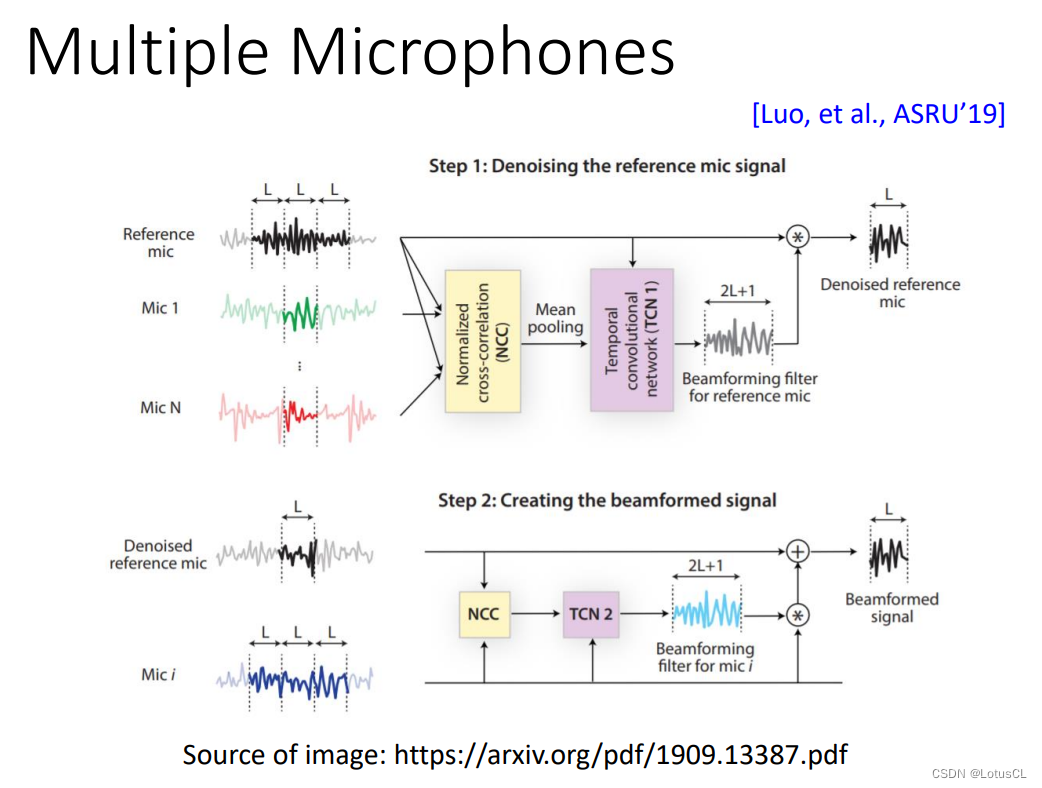
Multiple Microphones
-
另外,之前我们的输入声音信号都是单声道的声音。但现实中很多时候,我们都是用多声道的声音,也就是麦克风矩阵。我们要如何用超过一个麦克风的声音去做人声分离呢?传统上有一系列信号处理的方法。对于 Deep Learning,不过就是输入换成了多声道的声音,然后端到端训练,硬train就结束了。
Visual Information
-
此外,很多的声音来自于视频。我们也可以结合视频中的视觉信息来强化语音分离这个任务。谷歌有做一个 DEMO。要分离哪个人声,可以通过选择哪个人脸。咋做出来的?硬 train 一发就出来啦。
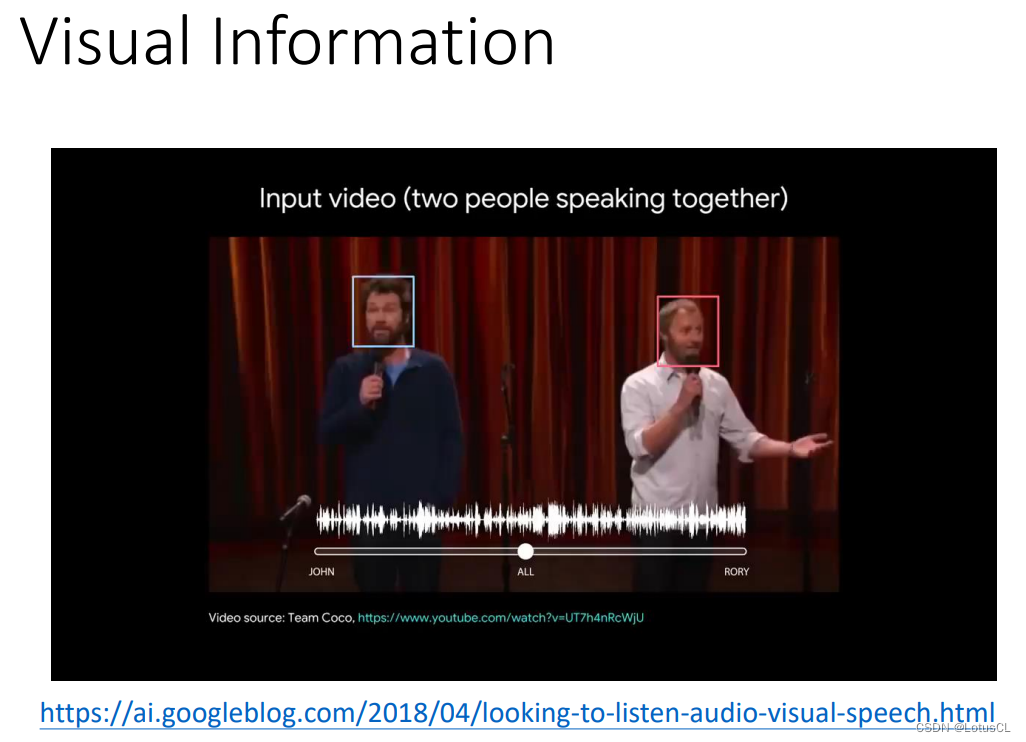
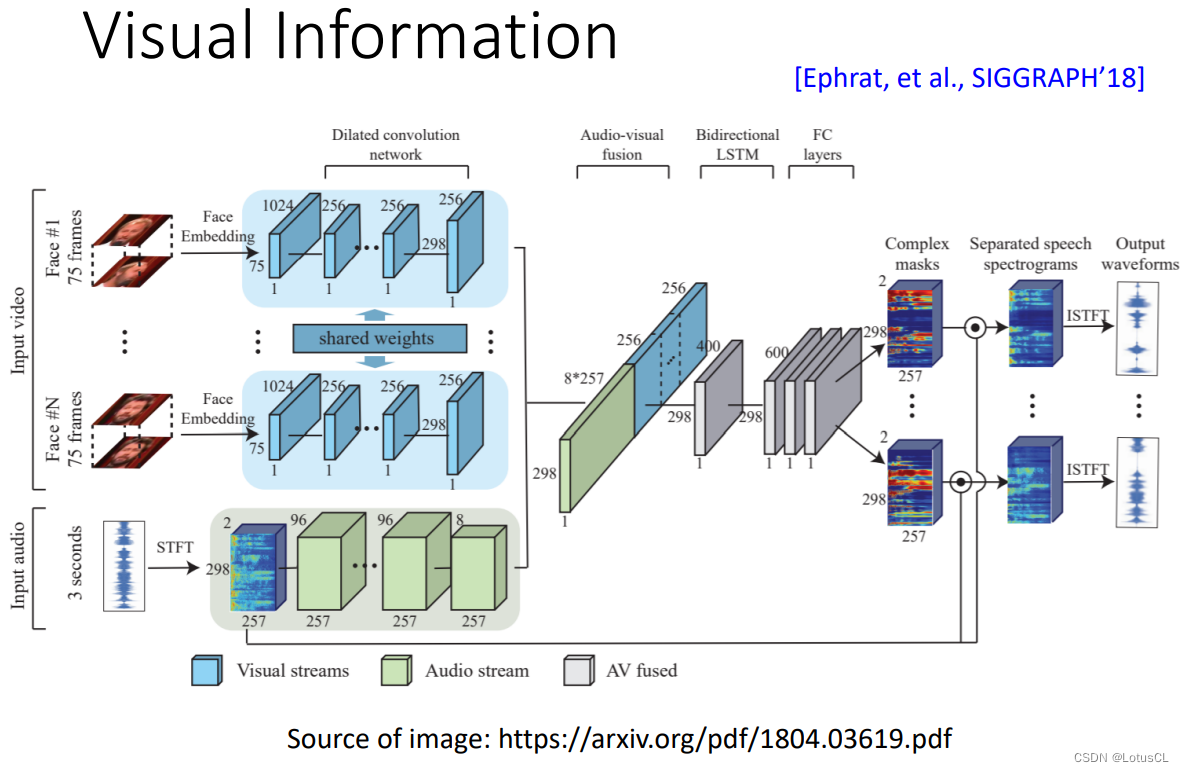
-
这个模型的输入是声音信号和说话时候的图片被分割出来的头像。说话头像部分用共享的 Dilated Convolution 来进行编码。混合人声波形部分会先用 SIFT 转换成频谱特征,再用一个AutoEncoder 来编码成语音嵌入。然后再把两个图像的嵌入和一个语音的嵌入向量拼接在一起。这里我们无需做 PIT。因为人像决定了输出声音的排列顺序。拼接在一起的向量会话先通过一个线性映射层来做图像和声音的融合。接着再用 BiLSTM 和 FC 层,把这个融合的嵌入变成两个数值为复数的 MASK。这两个 MASK 再乘上原来的声音信号,再做频谱到波形的转换,变输出到分离出的波形。
Task-oriented Optimization
-
实际上,我们做语音分离后,去应用的任务也不尽相同。有可能是给人听,也有可能是给机器听。
-
如果是给人听,我们更专注于分离出语音质量的可理解性,即人听到分离声音的感知。我们的优化目标可以是 STOI 和 PESQ。但 PESQ 的衡量方式往往非常复杂,还不能微分,不能直接用它来端对端地训练。由此如何去优化不能微分的优化目标是一个研究课题。
-
假设我们分离的声音不是给人听,而是给机器听。比如说 Speaker Verification。我们的优化目标就不是可理解性,而是整体的系统性能。比如训练完 denoise 模型后,我们并不会将结果直接喂给 ASR(Automatic Speech Recognition),而是会把 ASR 和 denoise 模型串起来再端对端训练一下,然后整体的系统才会好用。如果不串连,直接把各个部分级联起来,最终效果反而不会好。
-
因此,根据不同的任务,我们训练的目标可以很丰富,优化的目标可以很丰富。
其他有价值论文
-
除了目前讲的 Speech Separation 的论文。还有很多值得一看的论文。比如 Speech Enhancement 等等。
