——本节内容为Bilibili王道考研《数据结构》P60视频内容笔记。
目录
一、与树的深度优先遍历之间的联系
1.图的深度优先遍历类似于树的深度优先遍历,也就是先根遍历(递归实现);
2.代码:
void PreOrder(TreeNode *R)
{
if(R!=NULL)
{
visit(R); //访问根结点
while(R还有下一个子树T)
PreOrder(T); //先根遍历下一棵子树
}
}二、DFS算法实现
1.图示


2.代码实现
bool visited[MaxVertexNum]; //访问标记数组
void DFSTraverse(MGraph G) //对图G进行深度优先遍历
{
for (int v = 0; v < G.vexnum; ++v)
visited[v] = false; //初始化已访问标记数据
for (int v = 1; v < G.vexnum; ++v)
if (!visited[v])
DFS(G, v);
}
void DFS(MGraph G, int v) //从顶点v出发,深度优先遍历图G
{
visit(v); //访问顶点v
visited[v] = true; //设已访问标记
for(int w=FirstNeighbor(G,v);w>=0;w=NextNeighbor(G,v,w))
if (!visited[w]) //w为u的尚未访问的邻接顶点
{
DFS(G, w);
}
}
3.代码解释
(1)DFSTraverse(Graph G)函数针对于非连通图无法遍历完所有结点的情况,思想和广度优先遍历中的BFSTraverse一样;
(2)DFS函数递归实现,每次调用DFS函数都会将一个结点的的一个邻接点都遍历完再遍历另一个邻接点;
三、复杂度分析
1.空间复杂度
(1)来自函数调用栈;
(2)最坏情况,递归深度为O(|V|);
 (3)最好情况:O(1);
(3)最好情况:O(1);
2.时间复杂度
(1)时间复杂度=访问各结点所需时间+探索各条边所需时间
(2)邻接矩阵:
①访问|V|个顶点需要O(|V|)的时间;
②查找每个顶点的邻接点都需要O(|V|)的时间,而总共有|V|个顶点;
③时间复杂度;
(3)邻接表:
①访问|V|个顶点需要O(|V|)的时间;
②查找各个顶点的邻接点共需要O(|E|)的时间;
③时间复杂度=O(|V|+|E|);
四、深度优先生成树
1.图示
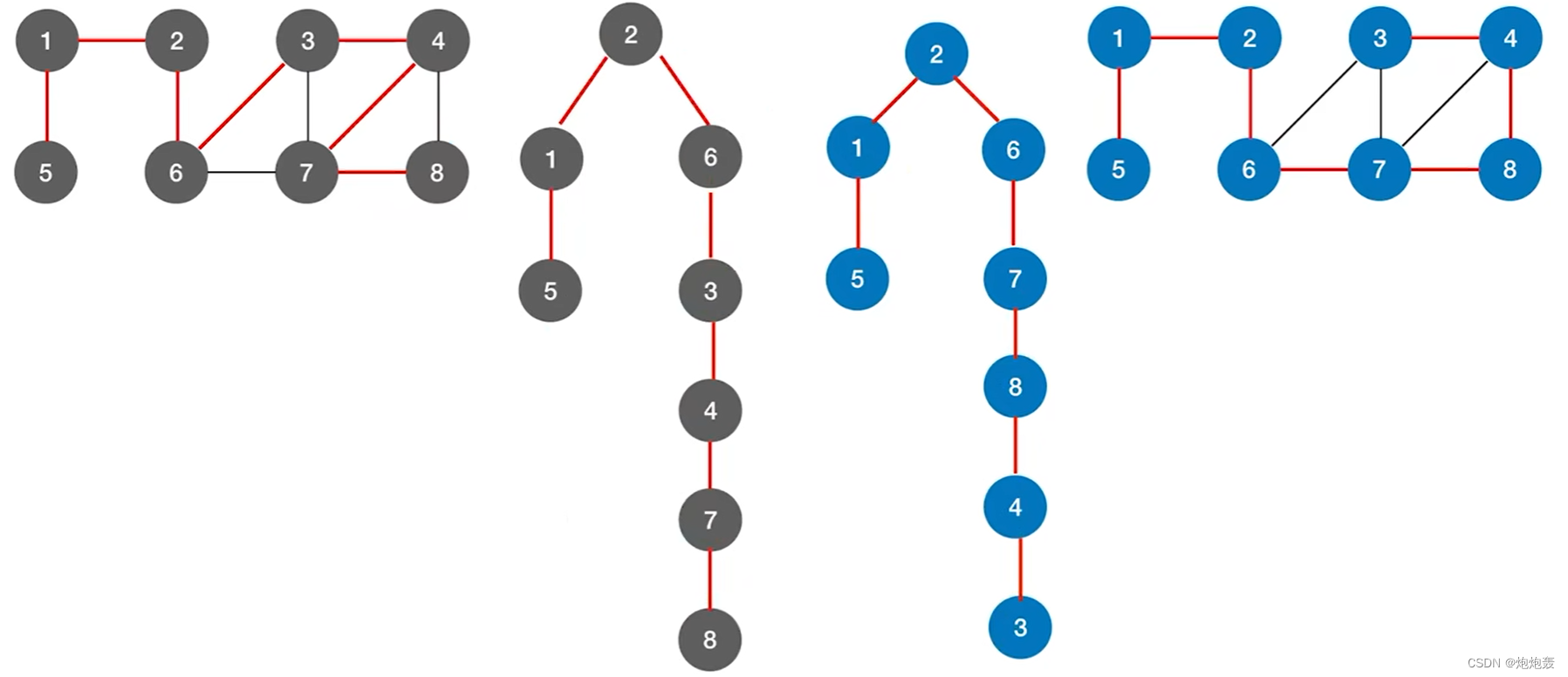
2.唯一性
①同一个图的邻接矩阵表示方式不唯一,因此深度优先遍历序列唯一,深度优先生成树也唯一;
②同一个图的邻接表的表示方式不唯一,因此深度优先遍历序列不唯一,深度优先生成树也不唯一;
3.深度优先生成森林

五、图的遍历和图的连通性
1.无向图

①对无向图进行BFS/DFS遍历,调用BFS/DFS函数的次数=连通分量数;
②对于连通图,只需调用1次BFS/DFS;
2.有向图

①对有向图进行BFS/DFS遍历,调用BFS/DFS函数的次数要具体问题具体分析;
②若起始顶点到其他各顶点都有路径,则只需调用1次BFS/DFS函数;
③对于强连通图,从任一结点出发都只需要调用1次BFS/DFS。