一、深度优先遍历的定义
深度优先遍历(Depth_First_Search),也称为深度优先搜索,简称DFS;
深度优先其实是一个递归过程,类似于树的前序遍历;它从图的某个顶点出发,访问此顶点,然后从该顶点的未被访问的邻接顶点出发深度优先遍历图,直至图中所有和该顶点有路径相通的顶点都被访问到了;若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点做起始点,重复上述过程,直至图中所有顶点都被访问到为止;
二、深度优先代码实现
bool visited[20];访问标志数组,与顶点表对应,当标志为true时,说明该顶点已经被访问过;
if(graph.arc[i][j] && !visited[j]);这里是在判断顶点i是否与j邻接,如果邻接,那么判断j是否已经被访问过,如果未访问过,那么递归调用DFS(graph,j);
bool visited[20];
void DFS(Graph& graph, int i){
visited[i] = true;
cout << graph.vexs[i] << " ";
for(int j = 0; j < graph.vexNum; ++j) {
if(graph.arc[i][j] && !visited[j]) {
DFS(graph, j);
}
}
}
void DFSTraverse(Graph &graph) {
//初始化访问标志数组
for(int i = 0; i < graph.vexNum; ++i) {
visited[i] = false;
}
//这里遍历是为了防止该图不是连通图,一次遍历不完的情况发生
for(int i = 0; i < graph.vexNum; ++i) {
if(!visited[i]) {
DFS(graph, i);
}
}
}
DFSTraverse和邻接矩阵市面没有区别的,DFS遍历方式有些差异,邻接矩阵是遍历该顶点的在矩阵中的一个横行,邻接表遍历的是该顶点的邻接链表;if(!visited[p->vexOrderNum]),这里就能很明显比较两种存储结构的差异,邻接表上的节点一定是邻接顶点,而邻接矩阵是需要判断的,感觉自己好像在说废话一样;
bool visited[MAXVEX];
void DFS(Graph& graph, int i){
visited[i] = true;
cout << graph.vexArr[i].vexName << " ";
eNode* p = graph.vexArr[i].vNext;
while(p) {
if(!visited[p->vexOrderNum]) {
DFS(graph, p->vexOrderNum);
}
p = p->next;
}
}
void DFSTraverse(Graph &graph) {
for(int i = 0; i < graph.vexNum; ++i) {
visited[i] = false;
}
for(int i = 0; i < graph.vexNum; ++i) {
if(!visited[i]) {
DFS(graph, i);
}
}
}
三、测试
#include<iostream>
using namespace std;
typedef struct Graph {
char vexs[20];
int arc[20][20];
int vexNum, edgeNum;
}*pGraph;
void CreateGraph(Graph &graph) {
cout << "输入顶点数和边数:";
cin >> graph.vexNum >> graph.edgeNum;
for(int i = 0; i < graph.vexNum; ++i) {
cout << "输入第" << i+1 << "个顶点的名称:";
cin >> graph.vexs[i];
}
for(int i = 0; i < graph.vexNum; ++i) {
for(int j = 0; j < graph.vexNum; ++j) {
graph.arc[i][j] = 0;
}
}
int x, y, w;
for(int i = 0; i < graph.edgeNum; ++i) {
cout << "请输入第" << i+1 << "条边的两个顶点x,y和权值w:";
cin >> x >> y >>w;
graph.arc[x][y] = w;
graph.arc[y][x] = w;
}
}
bool visited[20];
void DFS(Graph& graph, int i){
visited[i] = true;
cout << graph.vexs[i] << " ";
for(int j = 0; j < graph.vexNum; ++j) {
if(graph.arc[i][j] && !visited[j]) {
DFS(graph, j);
}
}
}
void DFSTraverse(Graph &graph) {
for(int i = 0; i < graph.vexNum; ++i) {
visited[i] = false;
}
for(int i = 0; i < graph.vexNum; ++i) {
if(!visited[i]) {
DFS(graph, i);
}
}
}
int main() {
Graph graph;
CreateGraph(graph);
for(int i = 0; i < graph.vexNum; ++i) {
cout << "\t" << graph.vexs[i];
}
cout << "\n\n";
for(int i = 0; i < graph.vexNum; ++i) {
cout << graph.vexs[i] << "\t";
for(int j = 0; j < graph.vexNum; ++j) {
cout << graph.arc[i][j] << "\t";
}
cout << "\n\n";
}
cout << "深度优先遍历结果:";
DFSTraverse(graph);
getchar();
return 0;
}
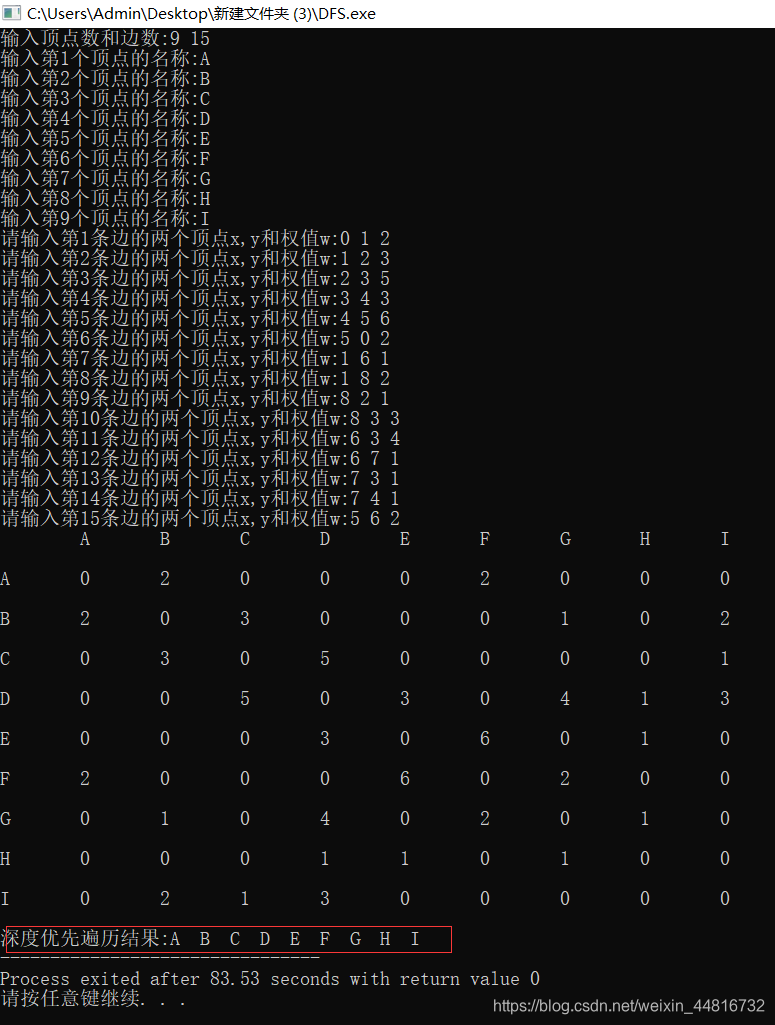
这个遍历结果刚好是按顺序的从A到I,这不是个巧合,其实在上面的邻接矩阵中就可以看出来为什么刚好是这样的遍历顺序~
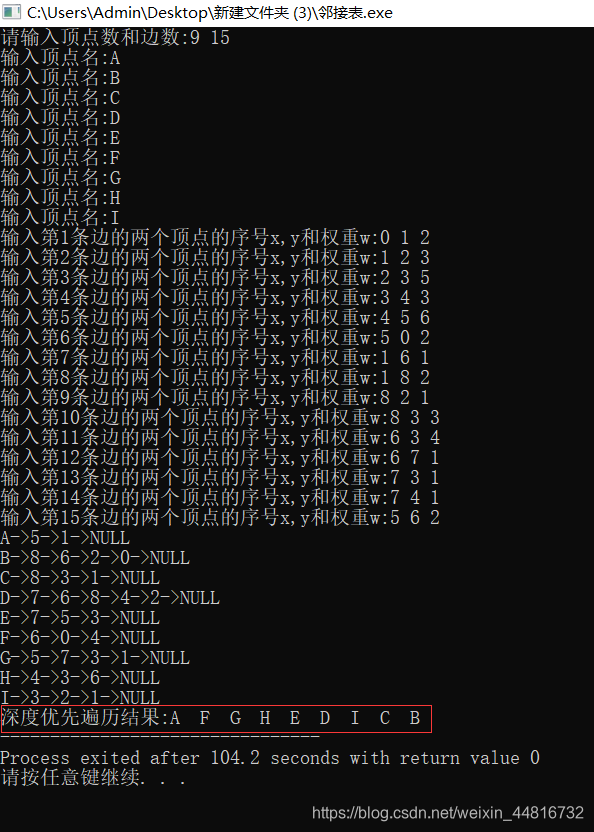
其实邻接表遍历的顺序在上面打印的表结构也能可看出来~
四、总结
其实深度遍历的思路就是,利用图的顶点之间的邻接关系来遍历,为了防止重复遍历,给访问过的顶点打上tag;如果你对邻接表和邻接矩阵理解的比较透彻的话,深度优先遍历是很好理解的;
针对邻接矩阵和邻接表两种存储方式的深度优先遍历来说,n个顶点,e个边的图,时间复杂度分别为O(n2)和O(n + e);所以如何做选择存储结构还是需要根据实际情况来看;
