- 顶点u到顶点v是可达的,意味着:有一条从顶点v到顶点u的路径
- 这种搜索有两种常用的方法:
- 广度优先搜索(breadth first search,BFS)
- 深度优先搜索(depth first search,DFS)
- 要获得效率更高的图的算法,深度优先搜索方法使用得更多
一、广度优先搜索(BFS)
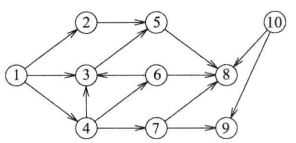
- 假设有下面的有向图,现在要搜索从顶点1可到达的所有顶点,广度优先搜索的方法如下:
- 先确定邻接于顶点1的顶点集合,这个集合是{2,3,4}
- 然后确定邻接于{2,3,4}的新的(即还没有到达过的)顶点集合为{5,6,7}
- 然后确定邻接于{5,6,7}的新的顶点集合为{8,9}
- 最终,从顶点1开始搜索,可以达到的顶点集合为{1,2,3,4,5,6,7,8,9}
伪代码
- 这种搜索方法可以使用队列实现,图的BFS和二叉树的层次遍历是相似的

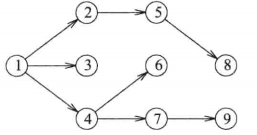
- 如果将该伪代码应用于上面的有向图,则步骤为:
- 伪代码中的v=1,在外层while循环的第一次迭代中,顶点2,3,4被一次加入到队列中
- 第二次迭代中,从队列中删除顶点2,加入顶点5
- 然后从队列中删除顶点3,但是没有加入新顶点;从队列中删除顶点4,加入顶点6和7
- 从队列中删除顶点5,加入顶点8;从队列中删除顶点6,但是没有加入新的顶点;从队列中删除顶点7,加入顶点9
- 最后从队列中删除8和9,队列为空,过程终止
- 下图是遍历所经过的边:
广度优先搜索的代码实现

- 我们使BFS方法成为超类graph的成员,使用graph的迭代器来实现邻接顶点的搜索,这样可以使我们不必为每一个图的实现单独地编写BFS代码
- 独立实现的BFS代码与上面的伪代码联系非常紧密。代码在初始时,对于搜索顶点都有reach[i]=0并且lable!=0.在算法终止时,所有可到达顶点都把对应的reach[i]设置为label
//reach[i]用来标记从顶点v可到达的所有顶点
virtual void bfs(int v, int reach[], int label)
{
arrayQueue<int> q(10);
reach[v] = label;
q.push(v);
while (!q.empty())
{
//从队列中删除一个标记过的顶点
int w = q.front();
q.pop();
//标记所有没有到达的邻接于顶点w的顶点
vertexIterator<T> *iw = iterator(w);
int u;
while ((u = iw->next()) != 0) {
//访问顶点w的一个相邻顶点
if (reach[u] == 0){
//u是一个没有到达的顶点
q.push(u);
reach[u] = label;
}
delete iw;
}
}
}
复杂性分析

- 上面我们是在超类graph中定制BFS代码,其派生类直接调用即可,现在我们来对派生类指定定制BFS的代码:一个是adjacencyWDigraph的成员、一个是linkedWDigraph的成员、一个是linkedDigraph的成员,其余的方法从超类中继承这些定制的代码
- 下面给出了adjacencyWDigraph的定制代码:
//reach[i]用来标记从顶点v可到达的所有顶点
void bfs(int v, int reach[], int label)
{
arrayQueue<int> q(10);
reach[v] = label;
q.push(v);
while (!q.empty())
{
//从队列中删除一个标记过的顶点
int w = q.front();
q.pop();
//标记所有没有到达的邻接于顶点w的顶点
for (int u = 1; u <= n; u++) {
//访问顶点w的一个关联的顶点
if ((a[w][u] != noEdge)&&(reach[u] == 0)) {
//u是一个没有到达的顶点
q.push(u);
reach[u] = label;
}
}
}
}
//reach[i]用来标记从顶点v可到达的所有顶点
void bfs(int v, int reach[], int label)
{
arrayQueue<int> q(10);
reach[v] = label;
q.push(v);
while (!q.empty())
{
//从队列中删除一个标记过的顶点
int w = q.front();
q.pop();
//标记所有没有到达的邻接于顶点w的顶点
for (chainNode<int>* u = aList[w].firstNode; u != NULL;u=u->next) {
//访问顶点w的一个关联的顶点
if (reach[u->element]==0) {
//u是一个没有到达的顶点
q.push(u->element);
reach[u->element] = label;
}
}
}
}
- 在1.7GHz的奔腾4 PC上,对100个顶点的无权完全无向图:
- 用邻接矩阵描述时:graph::mfs用时0.18毫秒。adjacencyWDigraph::mfs用时0.06毫秒。在时间性能上,统一实现的代码graph::bfs是定制代码的3倍
- 用邻接链表描述时:独立的统一代码的执行时间为1.0毫秒,定制的代码是0.9毫秒,前者比后者多了11%
- 总结:使用独立BFS代码,而不是定制的代码,是有性能损失的
- 在邻接矩阵描述中,这种损失会很大,主要是因为使用迭代器
- 然而要记住,使用独立的代码有若干优点。例如,一份代码即可满足所有的图类描述,而定制diamante需要若干个。因此,如果我们引进新的秒数方法(例如邻接数组表),就可以不加修改地使用独立的代码。当我们要开发一个新的图应用程序,我们可以首先开发独立的代码。这个方法使所有应用实现使用这个代码。然后,如果时间和资源允许,我们就可以定制更有效率的代码
二、深度优先搜索(DFS)
- 在前面介绍老鼠迷宫问题中我们已经使用了这种方法,而且它与二叉树的前序遍历很相似
原理与伪代码

- 从一个顶点v出发,DFS按如下过程进行:
- 首先将v标记为已到达的顶点,然后选择一个邻接于v的尚未到达的顶点u
- 如果这样的u不存在,则搜索终止;如果这样的u存在,那么从u又开始一个新的DFS
- 当这种搜索结束时,再选择另外一个邻接于v的尚未到达的顶点。如果这样的顶点不存在,那么搜索终止。如果这样的顶点存在,又从这个顶点开始进行DFS
- 如此继续下去....
原理图解
- 假设v=1,那么顶点2、3、4成为u的候选:
- 假设选择顶点2,从顶点2开始DFS:
- 将顶点2标记为已到达顶点,这时只有顶点5,然后从顶点5开始DFS
- 将顶点5为已到达顶点,这时只有顶点8,从顶点8开始DFS
- 将顶点8为已到达顶点,由于从顶点8开始没有不可到达的邻接顶点,因此返回到顶点5,顶点5也没有新的可到达的邻接顶点,因此在此返回到顶点2,顶点2也没有新的可到达的邻接顶点,再次返回到顶点1
- 现在还剩两个候选顶点3和4,假设从顶点4开始DFS:
- 将顶点4标记为已到达顶点,现在顶点3、6、7都成为候选顶点
- 假设选中顶点6,这时顶点3是唯一的候选,从顶点3开始DFS
- 将顶点3标记为已到达顶点,因为没有邻接于3的顶点,所以返回到顶点6;因为没有邻接于6的新顶点,所以返回到顶点4,这时顶点7成为新的候选,然后从顶点7开始DFS
- 将顶点7标记为已到达顶点,然后达到顶点9,而没有邻接于9的顶点,这一次我们最终返回到顶点1
- 现在没有邻接于1的新顶点了,算法终止
编码实现
- 下面是是公有方法graph::dfs以及保护方法graph::rDfs的代码。它假设graph<T>::reach和graph<T>::label是类graph的静态数据成员。在实现DFS中,令u遍历所有邻接于v的顶点比仅仅遍历不邻接于v的顶点,其代码更容易:
//reach[i]用来标记从顶点v可到达的所有顶点
void dfs(int v, int reach[], int label)
{
graph<T>::reach = reach;
graph<T>::label = label;
rDfs(v);
}
//深度优先搜索递归方法
void rDfs(int v)
{
reach[v] = label;
vertexIterator<T> *iv = iterator(v);
int u;
while ((u->iv->next()) != 0) {
//访问与v相邻的顶点
if (reach[u] == 0)
rDfs(u); //u是一个没有到达的顶点
}
delete iv;
}
复杂性分析
- 可以验证dsf和bfs有相同的时间和空间复杂性。不过使dfs占用空间最大(递归栈空间)的实例确实使bfs占用空间最小(队列空间)的实例,而使bfs占用空间最大的实例确实使dfs占用空间最小的实例
- 下图给出了dfs和bfs的性能在最好和最坏情况下的实例

