这篇主要是以下这篇文献的阅读笔记: https://towardsdatascience.com/how-to-code-the-transformer-in-pytorch-24db27c8f9ec
同时在YouTube上面有非常详细的代码讲解:https://www.youtube.com/watch?v=ISNdQcPhsts
Github上这个项目非常详细:GitHub - hyunwoongko/transformer: Transformer: PyTorch Implementation of "Attention Is All You Need"
参考文献:
https://medium.com/ching-i/transformer-attention-is-all-you-need-c7967f38af14
13.【李宏毅机器学习2021】Transformer (下)_哔哩哔哩_bilibili
总体结构:
图来自文章《attention is all you need》
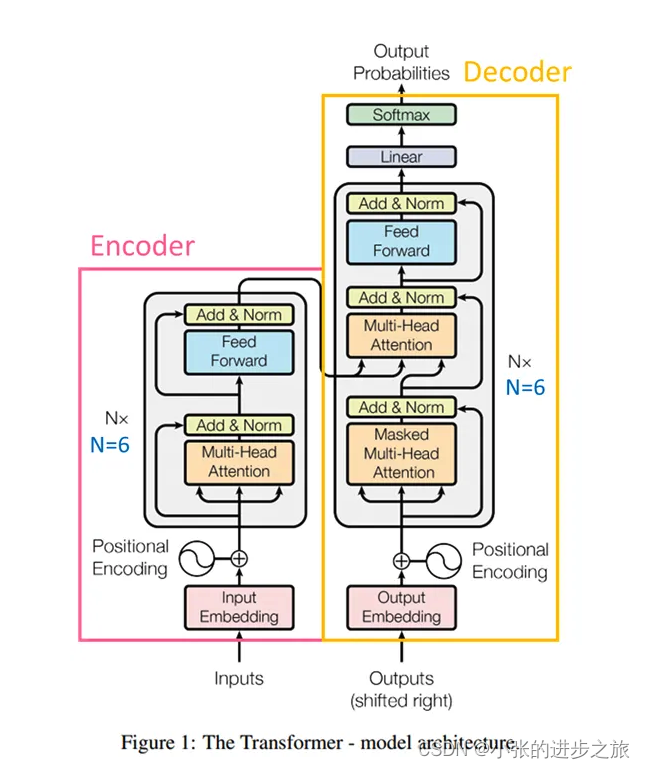
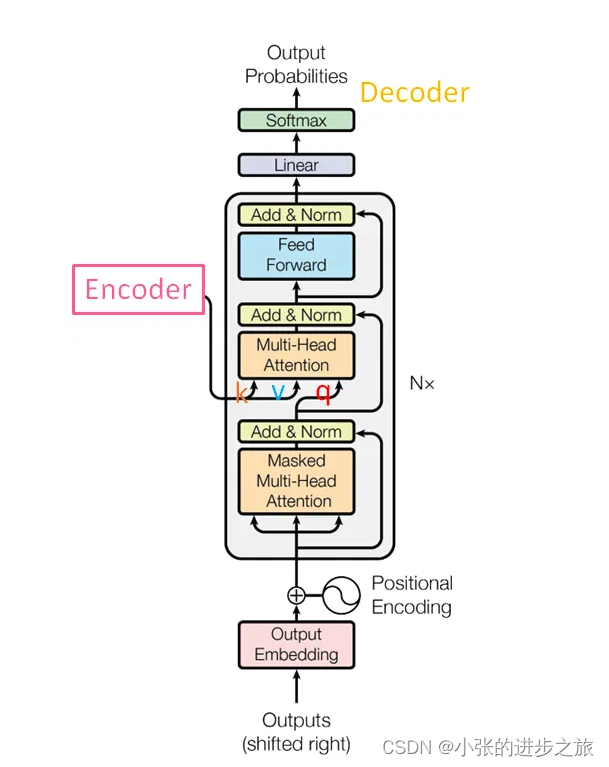
Transfomer主要分为Encoder和Decoder两个部分。 每个模块均为N个完全相同的模块堆叠组成(图中N=6)。 每一个encoder的输入是上一层ecoder的输出。
Encoder中输入的信息为Input,也就是用于预测的那部分信息; Decoder中输入的信息包括预测的结果,包括实际的预测信息和从encoder的输出。 最后是根据预测出来的结果与实际的想要预测的结果进行比较对比,计算loss值。
Encoder
Input Embedding
Encoder的第一步是将input转换为一个向量,第一步得到的数据维度将为: (batch_size, sequence_length, d_model)
#vocab_size是token的数量,d_model是transfomer的输出维度
class Embedder(nn.Module):
def __init__(self, vocab_size, d_model):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model)
def forward(self, x):
return self.embed(x)
Note: 在代码中存在forward, forward方法是 PyTorch 模块中的一个特殊方法。每当你向 PyTorch 模型或自定义模块传递输入时(例如,model(input)),forward 方法就会被调用。一般用于说明input是如何被转化用于output。
Positional encoding
在将input转换为一个向量以后,接着就是加上位置信息(positional encoding),位置信息使用的方法如下:
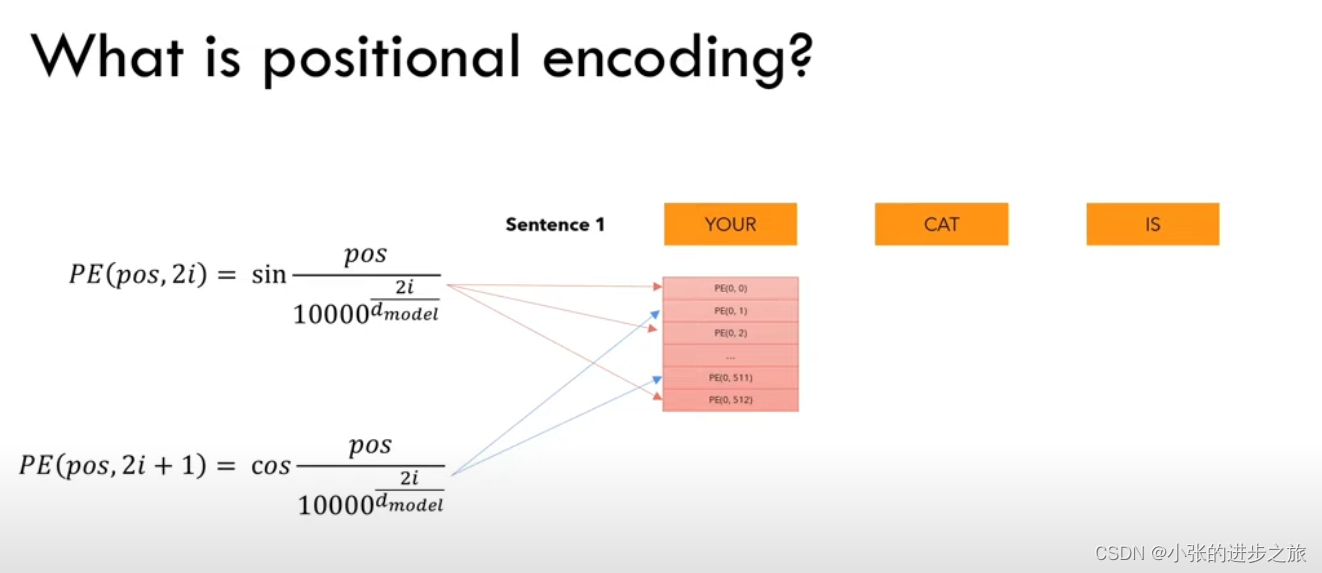
class PositionalEncoder(nn.Module):
def __init__(self, d_model, max_seq_len = 80):
super().__init__()
self.d_model = d_model
# create constant 'pe' matrix with values dependant on
# pos and i
pe = torch.zeros(max_seq_len, d_model)
for pos in range(max_seq_len):
for i in range(0, d_model, 2):
pe[pos, i] = \
math.sin(pos / (10000 ** ((2 * i)/d_model)))
pe[pos, i + 1] = \
math.cos(pos / (10000 ** ((2 * (i + 1))/d_model)))
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
# make embeddings relatively larger
x = x * math.sqrt(self.d_model)
#add constant to embedding
seq_len = x.size(1)
x = x + Variable(self.pe[:,:seq_len], \
requires_grad=False).cuda()
return x下一步就是将位置信息加入到input embedding里面,流程如图所示:
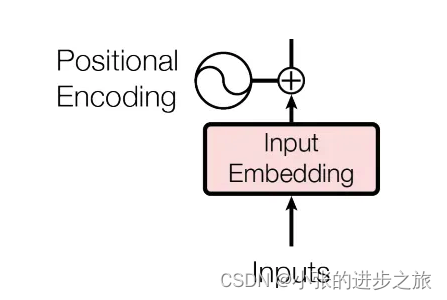
我们之所以在相加之前增加嵌入值,是为了使位置编码相对较小。这意味着当我们将它们相加时,嵌入向量中的原始含义不会丢失。
这一步得到的数据维度为: (batch_size, seq_len, d_model)
Multi-head Attention
以下为multi-head attention的结构:
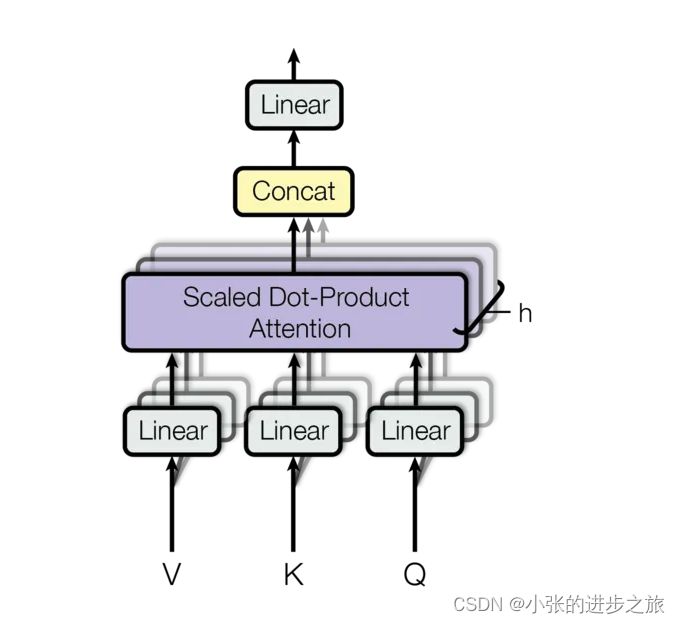
多头注意力机制是由h个相同的注意力机制堆叠形成的,首先对其中一个注意力机制的原理进行介绍:
关于Q,K,V, B站这个视频非常直观:注意力机制的本质|Self-Attention|Transformer|QKV矩阵_哔哩哔哩_bilibili
注意力机制中有三个重要的向量 Q,K,V 分别代表:
Q (Query) :查询通常是你想要查找的信息,代表当前我们关注的内容
K (Key):键与查询配对,与查询配对用来计算注意力分数。这个分数决定了每个值的重要性
V (Value): 注意力分数,这些分数就用于加权“值”。这样,生成的输出是值的加权组合,权重由键和查询之间的相似度决定。
在某一个时刻下,通过 q对每一个k做内积得到q,k之间匹配的相似程度 α1, α2……,然后使用softmax把得分变成概率,除于 (向量的长度)的原因是为了使梯度稳定。
这个步骤叫做:scaled dot-product attention.

在李宏毅老师的课程中,使用了一个例子来说明。
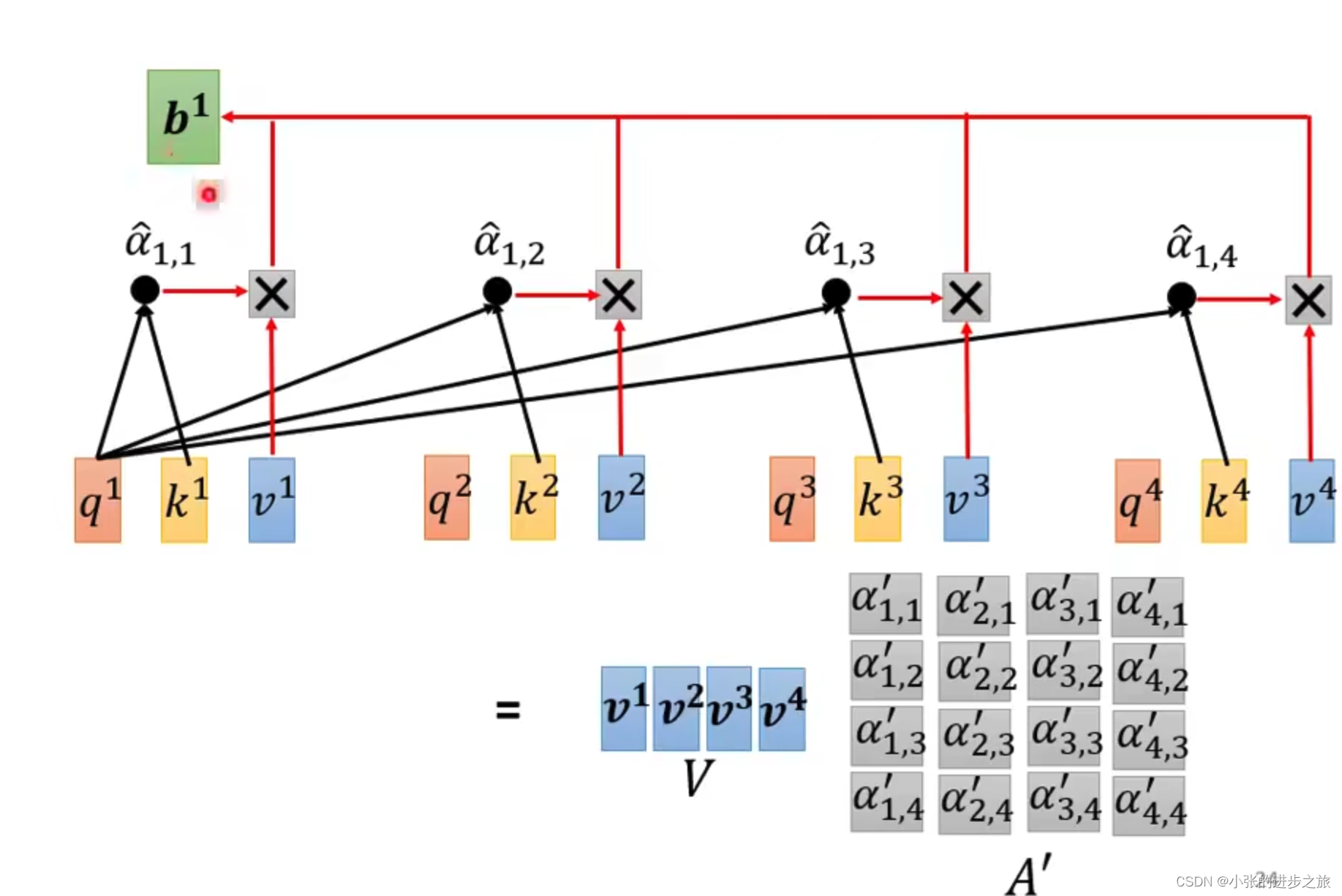
Q,K,V 均是由X投影形成,投影到较低维度。对于Q,K,V而言,他们都是由同一个X产生的,乘上不同的W生成的。投影h次生成不一样的结果,学习到不一样的特征,增加了多样性。在所有的计算中,只有是未知的,在计算的过程中将由算法决定。
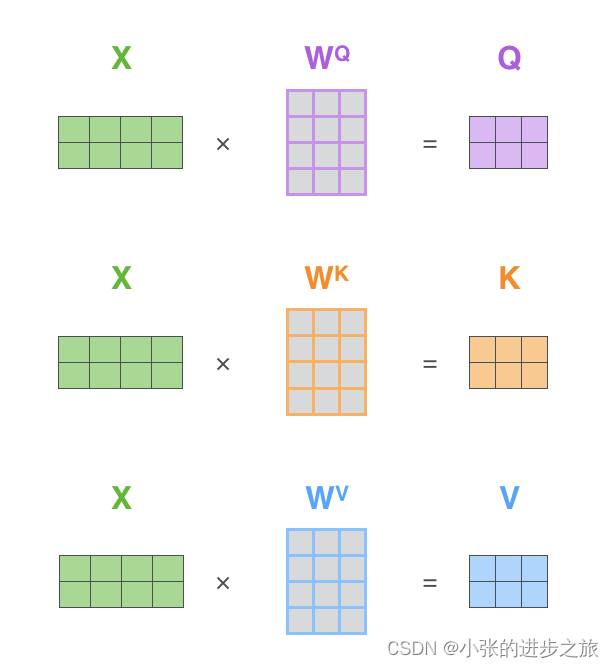
所以得到详细的公式如下: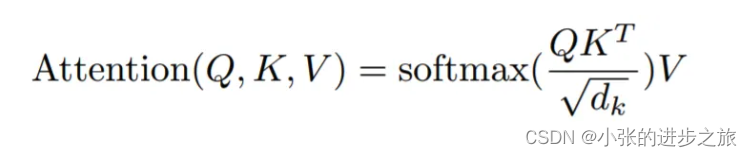
class MultiHeadAttention(nn.Module):
def __init__(self, heads, d_model, dropout = 0.1):
super().__init__()
self.d_model = d_model
self.d_k = d_model // heads
self.h = heads
self.q_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.out = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
bs = q.size(0)
# perform linear operation and split into h heads
在进行分头的时候一般均使用以下的代码,view
k = self.k_linear(k).view(bs, -1, self.h, self.d_k)
q = self.q_linear(q).view(bs, -1, self.h, self.d_k)
v = self.v_linear(v).view(bs, -1, self.h, self.d_k)
# transpose to get dimensions bs * h * sl * d_model
k = k.transpose(1,2)
q = q.transpose(1,2)
v = v.transpose(1,2)
# calculate attention using function we will define next
scores = attention(q, k, v, self.d_k, mask, self.dropout)
# concatenate heads and put through final linear layer
concat = scores.transpose(1,2).contiguous()\
.view(bs, -1, self.d_model)
output = self.out(concat)
return output对于多头注意力机制而言,其实就是以上的程序重复h次,使用h次不一样的投影,来学习不同方向。为什么要做多次的原因在于:是为了使不同的head关注不同的信息。 最后再对多头计算出来的结果进行contact。
Add&Norm
在多头注意力机制以后,后一层是add&norm层,这一层是进行残差连接(Residual)以及layer normalization.

在这张图里更加清晰:也就是通过自注意力层得到的结果还会加上原本的x值来通过全连接层。

归一化在深度神经网络中非常重要。它可以防止层中的数值范围变化过大,这意味着模型的训练速度更快,泛化能力更强。
在tranformer里面中使用的不是batch normalization不是,而是layer normalization。主要的原因是因为对于不同的样本,长度是不相同的,layer normalization的话可以降低不同样本之间长度不同带来的影响。
class Norm(nn.Module):
def __init__(self, d_model, eps = 1e-6):
super().__init__()
self.size = d_model
# create two learnable parameters to calibrate normalisation
self.alpha = nn.Parameter(torch.ones(self.size))
self.bias = nn.Parameter(torch.zeros(self.size))
self.eps = eps
def forward(self, x):
norm = self.alpha * (x - x.mean(dim=-1, keepdim=True)) \
/ (x.std(dim=-1, keepdim=True) + self.eps) + self.bias
return normFeed-Forward Network
这一层其实就是一个MLP。
两层线性计算,首先对上一层的结果进行线性运算,Relu计算再进行线性计算。
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff=2048, dropout = 0.1):
super().__init__()
# We set d_ff as a default to 2048
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
x = self.dropout(F.relu(self.linear_1(x)))
x = self.linear_2(x)
return xDecoder
Decoder是解码层,Decoder的其他部分与encoder基本一致,与encoder只有multi-head attention和feed forward不同的是,在decoder中还有一个block: masked multi-head attention.
Decoder的输入是真实值 (teaching forcing).
Create masks
在这里主要讲述一下Masked Multi-head attention的部分,因为在decoder中预测的信息是一个一个产生的,所以在生产结果的时候需要对之后的预测结果进行遮挡。
masks的目的主要有:
- Padding mask在编码器和解码器中: 如果输入句子中仅有填充(pad),则输出为零。填充是一种特殊的标记,在将多个序列批量处理在一起是,它被添加到时间序列中,使其长度相等。
- Sequence mask 在解码器中: 防止解码器在预测下一个单词时 "峰值 "超前翻译句子的其余部分。
batch = next(iter(train_iter))
input_seq = batch.English.transpose(0,1)
input_pad = EN_TEXT.vocab.stoi['<pad>']
# creates mask with 0s wherever there is padding in the input
input_msk = (input_seq != input_pad).unsqueeze(1)
# create mask as before
target_seq = batch.French.transpose(0,1)
target_pad = FR_TEXT.vocab.stoi['<pad>']
target_msk = (target_seq != target_pad).unsqueeze(1)
size = target_seq.size(1) # get seq_len for matrix
nopeak_mask = np.triu(np.ones(1, size, size),
k=1).astype('uint8')
nopeak_mask = Variable(torch.from_numpy(nopeak_mask) == 0)
target_msk = target_msk & nopeak_maskmask的工作原理:
从个体的角度来看:
对于来说,在masked self-attention的时候,使用
只对
和
进行查询,后面的
和
则是被挡住的状态,这与self-attention的机制是不一样的。

从矩阵的角度来看:
使用一个非常大的数来做后面的K对应的V。也就是使用一个上三角为1的矩阵来使当前单词之后的信息看不到

Cross attention
中间层的multi-head attention的输入q来自于本身前一层的输出,而k,v 均属于N个encoder中最后一层输出的结果。当decoder生成一个新词时,它会使用自己的输出作为查询(Q),并使用encoder的输出作为键(K)和值(V),以此来决定输入序列的哪些部分是与当前生成的词最相关的。
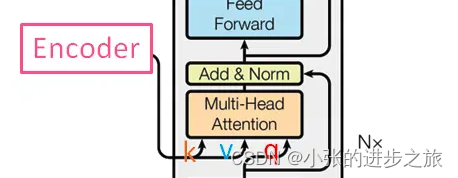
以下图为例,在decoder中生成q, 然后分别与encoder中的k和v进行查询,得到生成的结果,得到后续的结果。用一个通俗的话来说就是:解码器的这个q在编码器的k里面挑选与自己关联度高的值。

这一步主要是考虑在建模的时候考虑上下文的信息。