现在关于transformer的论文铺天盖地,那这个在自然语言领域的龙头算法框架如何在cv领域大展手脚,最近的一些成果已经带给我们很多震撼,cv是否也能像NLP一样迎来transformer时代还需要cv学者共同探索。就目前来看虽然使用transformer可以达到现有cv水准,但其训练所需的设备直接劝退,家底不厚确实无法开展transformer之旅。下面就将自己的学习过程做好记录去,去领略transformer的神奇之处。

1.论文简介
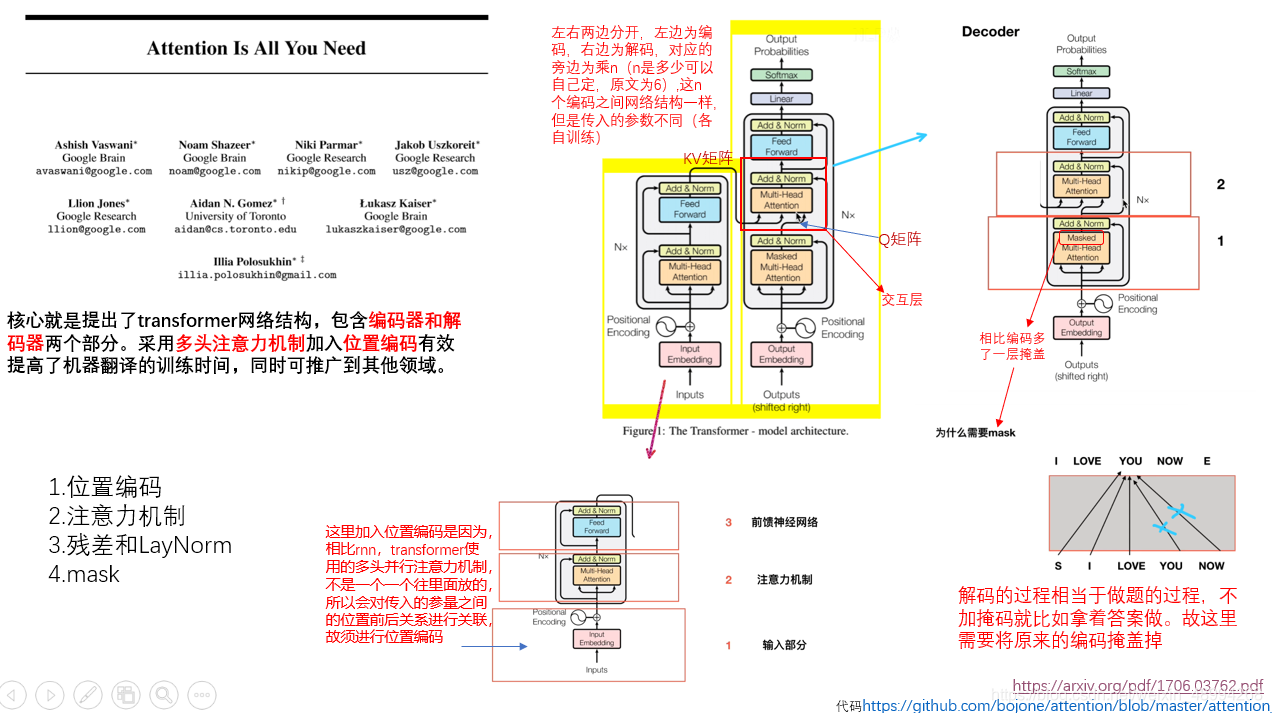
论文的下载地址:Attention Is All You Need
论文的开源代码:link

2.入门资料
3万字长文带你轻松入门视觉Transformer
Transformer从零详细解读(可能是你见过最通俗易懂的讲解)
【唐宇迪】transformer算法解读及其在CV领域应用 (迪哥YYDS,ps:之前opencv也是看的迪哥的,讲的真的太好了)
3.注意力机制
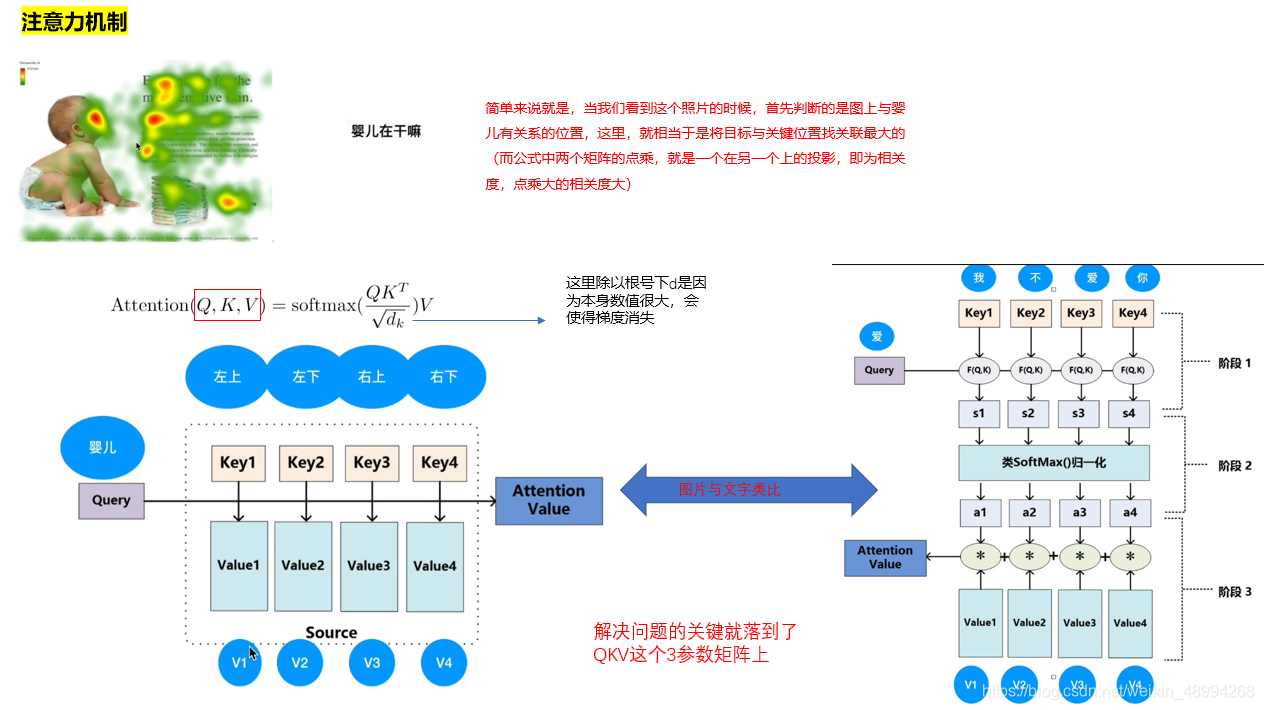
注意力机制是transformer的核心。那啥叫注意力机制,刚开始我看了几个文章及相关博客也感觉似懂非懂的,但迪哥讲透了。看迪哥视频之前建议先看前两个,大概有个了解。下面是学习初做的PPT笔记:
看完迪哥视频后,对上面的过程有了进一步认识。
self-attention就是让计算机去更关注某个部分。对比人就知道,我们关注别的东西时,都有侧重点,而当前cv中的常用卷积操作,是对每个部分平均对待,没有侧重点,逐步提取信息(浅层——更高层信息),逐步提升感受野。就是说刚开始按照卷积核的大小,你只能在这个范围内将图像进行联系,然后逐渐随着卷积层数增加可以和距离自己更远的位置进行关联提特征。


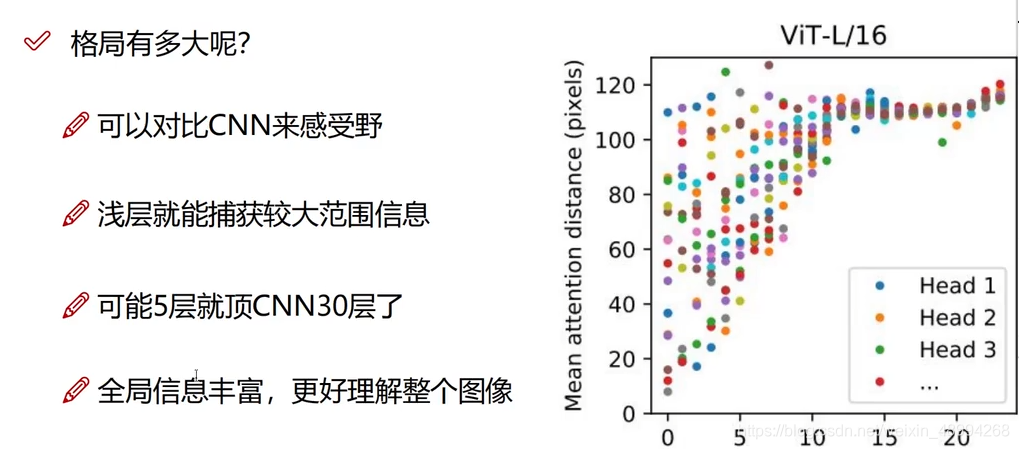
但自注意力机制,直接上来就将自身与其他元素(在nlp中是单词,cv中是图像块)之间的寻求关系度。做完以后可以直接获得全局的一个关系。也就是transformer格局大了。

那接下来看看,它是如何进行自注意力机制的:
以NLP任务为例:
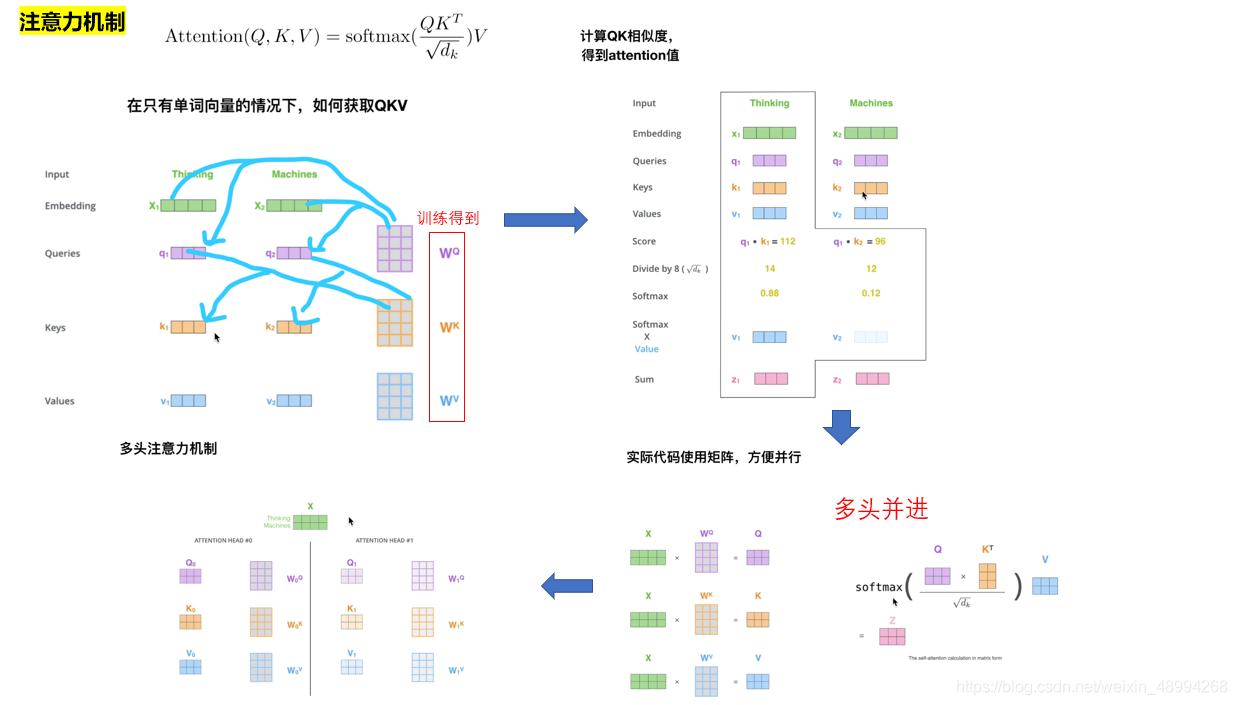
将原始输入数据进行重构,在NLP中每个输入的字都有自己对应的向量表示,利用注意力机制将该词与其他词汇进行关联重构该向量。
假设输入词汇就两个:

其中每个词汇都有个对应的初始代表自身的向量,有Queries(去查和别的词汇关系时用的)、Keys(别人查的时候自身提供的)、Values(自身的特征向量)。这Q,K,V是通过训练的三个权重W得来的:

计算x1得相似度:

以此类推,多个词汇也一样:
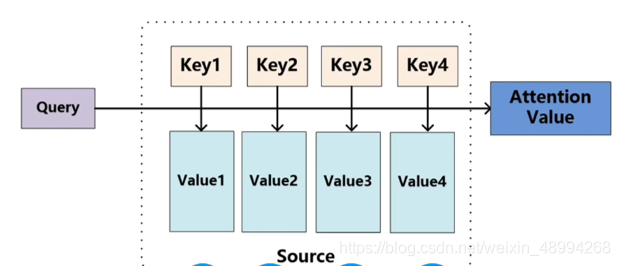
以上就得到了重构后得带有全局得特征向量。
在cv中,亦是如此,只不过词汇换为了切割好的像素块。
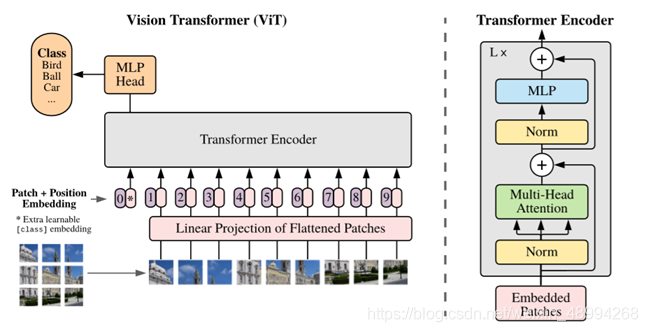
上图论文地址:link,源码地址:link
但是,从重构过程来看,每个词汇都与所有词汇进行了关联,位置信息在该步骤里没没有用到,而位置也是重要特征,故需要位置编码。
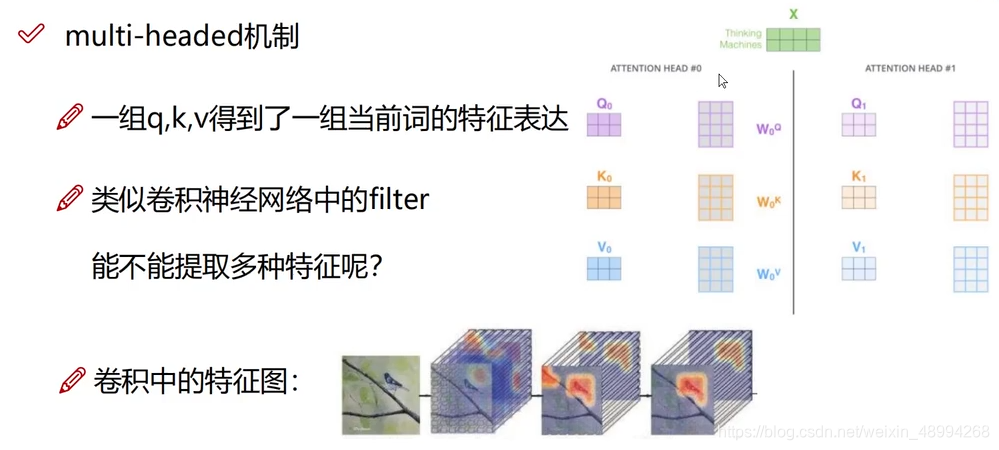
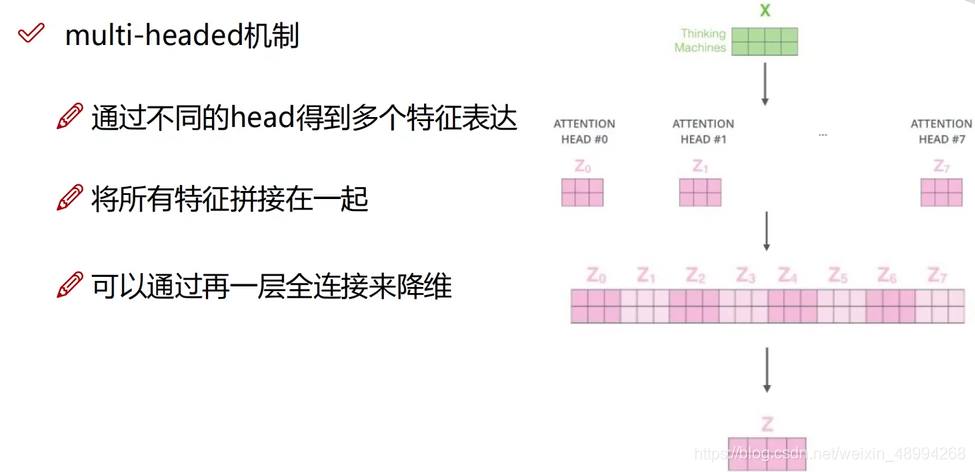
多头注意力机制(multi-header)
为了得到更多更丰富的特征,我们不仅仅使用一个注意力机制,我们在训练时初始化多个权值,齐头并进:
4.位置编码

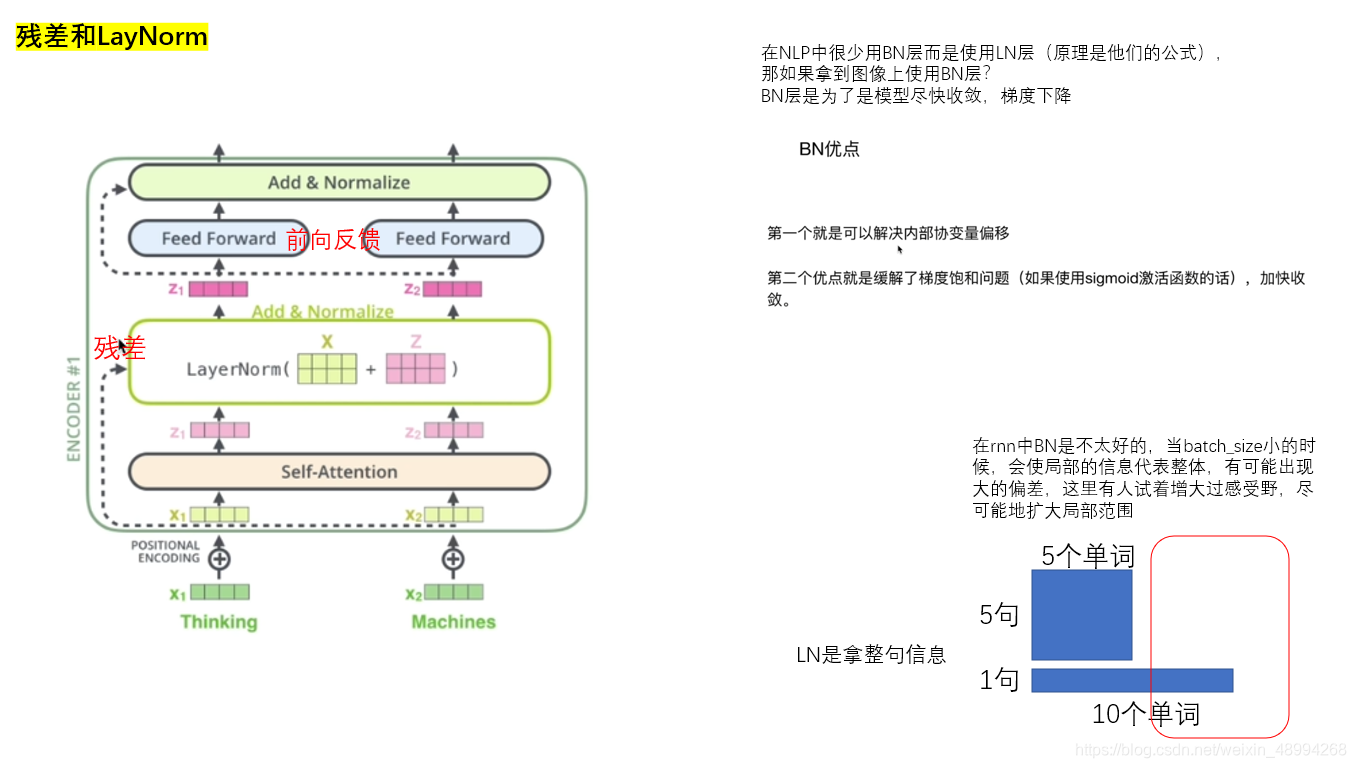
5.残差与LayNorm