transformer
通过B站up(水论文的程序猿)视频内容记录笔记 https://www.bilibili.com/video/BV1f34y1V7Ch/?share_source=copy_web&vd_source=4df5f191ed6cfa3f54382cfb42a6be35
预训练
深度学习,需要大数据支持,但是研究往往缺少大数据的支持,(ImageNet太大,自己训练没有这样的算力条件)。
预训练就是利用别人训练过的模型结果。

浅层的特征是可以通用的。
一般我们使用的浅层特征(已经训练好的模型)的方法fine-tuning微调。
fine-tuning就是在浅层的特征上,继续我们的训练,加强我们的小数据特征识别并会改变浅层的参数。
预训练的浅层模型,需要找相似的数据训练。
统计语言模型
语言模型
人们说的话+模型=去完成某一个任务。
类似NLP模型的处理,预测一句话的输出。
统计语言模型则是解决预测的词句结果。使用的是概率论里的条件概率链式法则。

通过一句话的序列(如:“我”,“是”,“谁”),判断每个词出现的概率,最后得到一句话出现的概率。
p(w_next |“我”,“是”,“谁” ),通过词库(语言的数据集)整合一个集合进行条件概率链式法则计算。
词量太大的话,计算成本太高。

所以提出了n元统计语言模型
把n个词,取其中几个词,(几元模型)。
计算方法

神经网络语言模型
独热编码(one-hot )
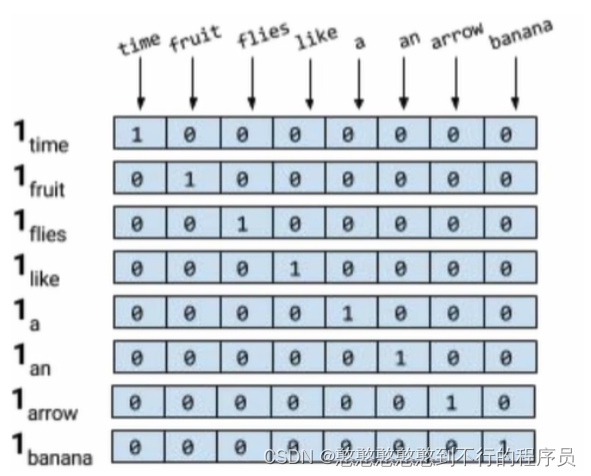
八个单词,给出一个8x8的矩阵,以维度标识单词。
有关联性的单词,就可以用余弦相似度进行计算。
**余弦相似度算法:**一个向量空间中两个向量夹角间的余弦值作为衡量两个个体之间差异的大小,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90度,表明两个向量越不相似。



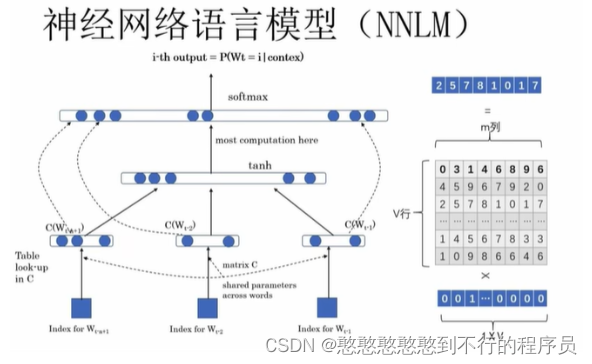

w x + b wx+b wx+b and w ( t a n h ( w x + b ) ) + b w(tanh(wx+b))+b w(tanh(wx+b))+b
Q作为随机矩阵,是一个可学习的参数
词向量
给定一个词,设独热编码, w 1 ∗ q = c 1 w1*q=c1 w1∗q=c1 为这个词的词向量。
用一个向量表示一个词(独热编码)。
词向量可以控制维度
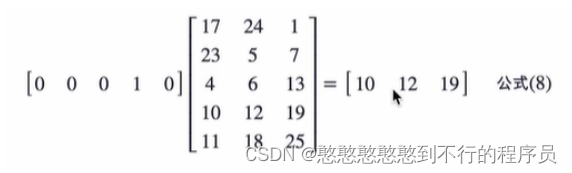
乘以一个词向量,则余弦相似度为零的概率就减低了。
Word2Vec
该模型的主要目标是为了得到词向量。
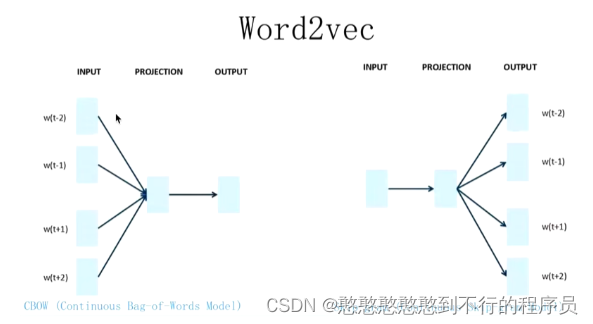
CBOW
给出一句话的上下文,得到中间承上启下的部分。
w t w_t wt作为缺失的部分, w t − 1 w_t-1 wt−1 or w t + 1 w_t+1 wt+1 则是缺失部分的上下两个部分。
eg:一个老师告诉多个学生,Q怎么变
SKIP-GRAM
给出一个词,得到上下文。
eg:多个老师告诉一个同学,Q怎么变。
NNLM重点是预测下一个词,而wodr2vec是为了得到一个Q矩阵。

词向量不可以做到一词多义。
ELMo
该模型主要解决多义词问题

不只是训练一个Q矩阵,把上下文的信息融入到Q矩阵中,然后将三层的信息进行叠加,T1作为一个新的词向量。
Attention

Q是最适合查找目标的,K是最适合接收查找的,V就是内容,计算QV事物的重要度,相似度计算
Q, K = k 1 , k 2 . . . . . , k n K=k_1,k_2.....,k_n K=k1,k2.....,kn ,一般使用点乘QK,拿到Q和每一个K的相似值 Q ∗ k n = a n Q*k_n=a_n Q∗kn=an 。
做一层 s o f t m a x ( a 1 , a 2 , ⋯ , a n ) softmax(a_1,a_2,\cdots,a_n) softmax(a1,a2,⋯,an) 得到概率。
找到Q最相似的对象。
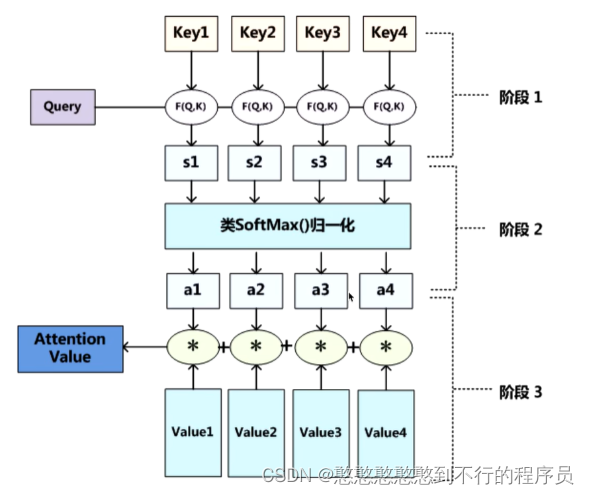
将得到的概率乘上V后进行叠加处理,则现在的V就能体现出谁更重要。
