Transformer模型学习笔记
前言
Google研究菌曰: 在transformer模型之前,我们做机器翻译等事情(论文原话: 我们做转录模型(transduction model)) 都是用循环神经网络(RNN)或者卷积神经网络(CNN)作为基本单元,搭建一个包含encoder和decoder的模型. 虽然效果不错,但是显然还有很多进步空间. 既然拿那么多钱,上班又不是996,不如整点新的东西? 于是有了transformer模型.
回顾
回顾下整体流程, 为啥会想到要去创造transformer这个东西.
做机器翻译?
–>那咱们搭一个具有encoder-decoder结构的模型. 其中seq2seq是最常用的encoder-decoder模型–>模型里的小单元用基本结构的RNN或者基本结构的CNN.
训练完发现对长句记忆效果不理想,模型记不住之前的信息?发生梯度消失?
–>采用RNN的变体结构LSTM
翻译效果不太好?不同输入单词对后面的影响以及重要程度没有体现? (这种情况被称为分心模型)
–>加入注意力机制(attention),让每个单词都关注它最应该关心的信息,即从"分心模型"变成了"带注意力模型"(打比方: 听老师上课时,要有目的的开小差,而不是肆无忌惮的开小差或者从头认真听到尾)
比起seq2seq有什么改进?
–> 原始的seq2seq模型,decoder部分用的信息全来自encoder部分最后一个时间片产生的向量, 显然向量长度有限->导致记录的信息也有限. 加入attention后, encoder部分每个单词都会产生额外信息,decoder部分模型会加入这个额外信息.
那现在效果还可以,但是attention机制依旧无法并行运算, 所以训练速度仍然很慢, 咋滴办? (且attention忽略了输入句中文字间和目标句中文字间的关系)
–>Transformer模型!! Transformer模型里的self-attention机制可以实现并行计算,并且代替seq2seq结构.
参考资料
论文原文: Attention is all you need
英文解读–> https://jalammar.github.io/illustrated-transformer/
解读的中文翻译–> https://blog.csdn.net/yujianmin1990/article/details/85221271
解读
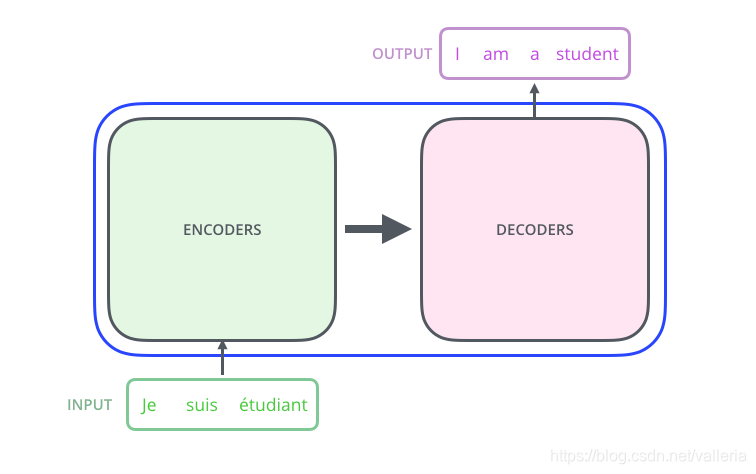
1. High-level的看一下,transformer大致是个什么样子
就是下面这个样子. 整个模型包含encoder部分和decoder部分,依旧是encoder输入,decoder输出.
稍微画仔细点,长这样
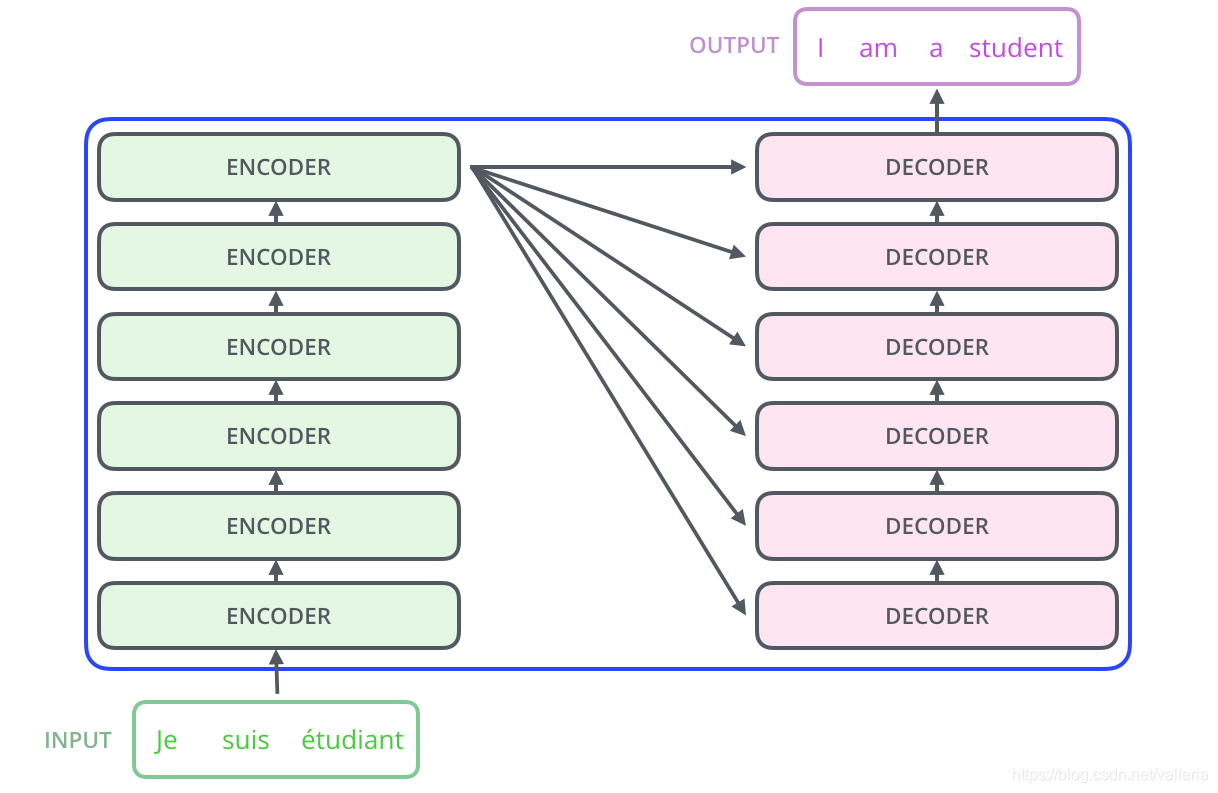
需要注意的是:
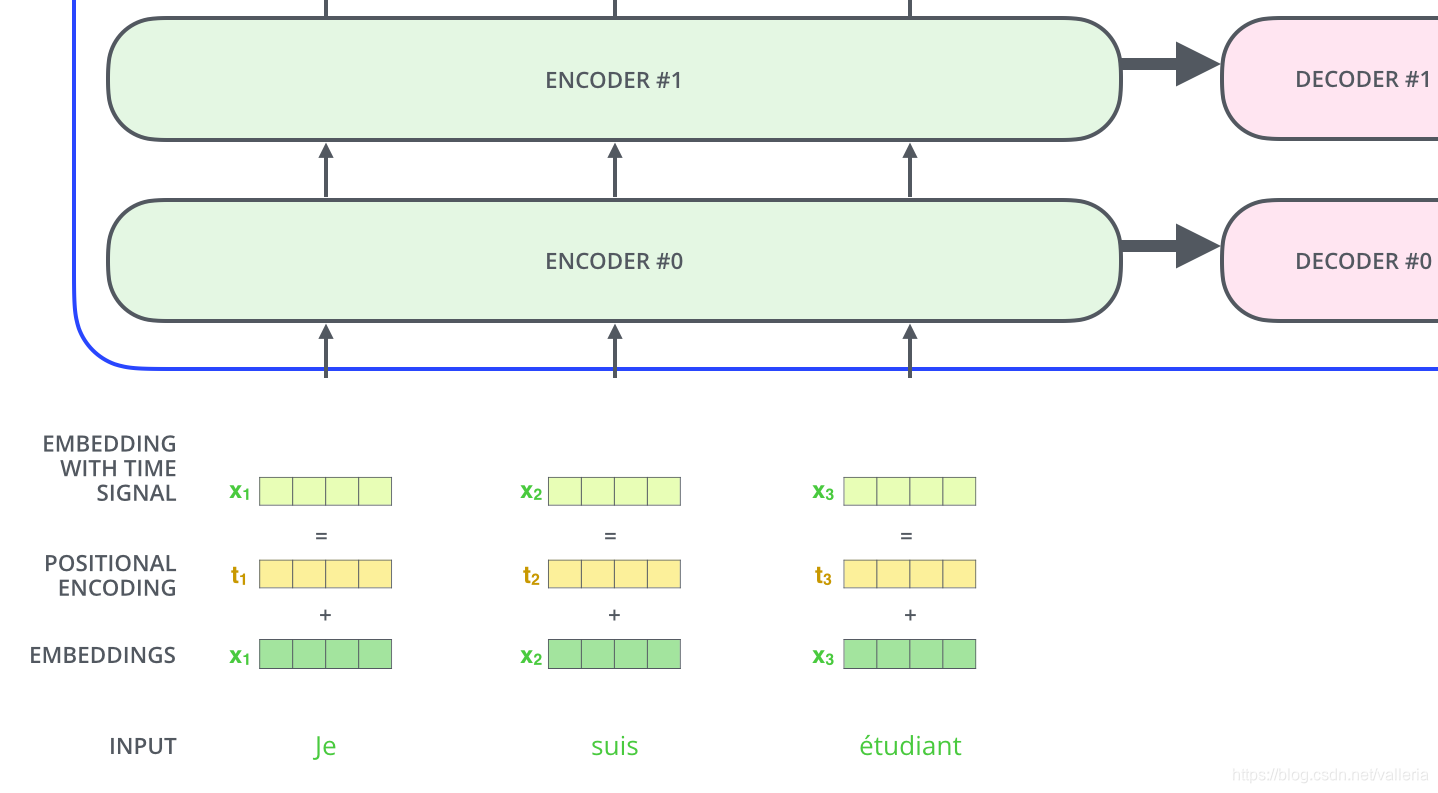
6个encoder结构互相相同,但是不共享参数.
6个decoder结构互相相同,但是也不共享参数.
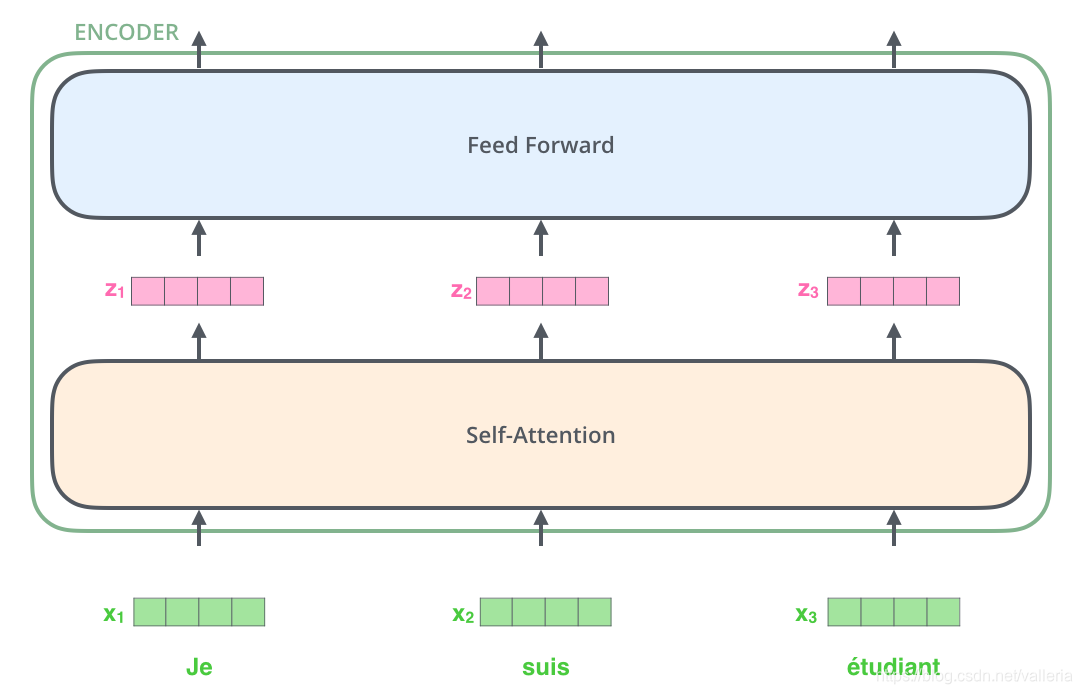
看完了,那看看每个encoder编码器里的具体结构. 长这样↓
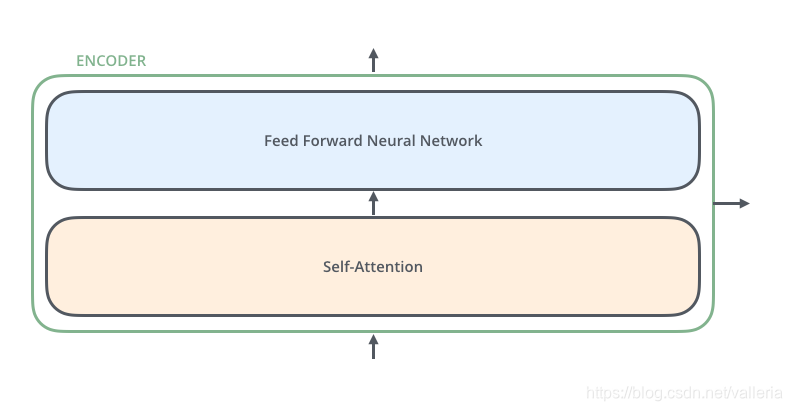
encoder里的第一个结构叫做 self-attention 层. 所有向量进入encoder后,都会进入self-attention层. self-attention层帮助encoder编码器在编码(处理)某个特定单词时,同时关注同一个输入句子里其他单词的信息.
然后self-attention层的输出流向一个前向网络层(Feed Forward Neural Network),每个输入位置对应的前向网络是独立互不干扰的.
decoder和encoder长得差不多,结构如下
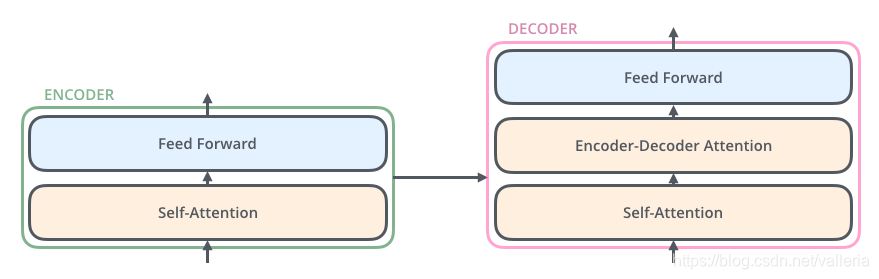
OK,到这里,整个Transformer最粗略的结构讲完了.
下一节深入每个结构的细节
2.详细看下, 具体结构,以及输入都长什么样
- 首先开始讲编码器部分(encoder)
在NLP里,拿到单词,比较常见的情况下,我们都会把它转成向量.
我们假设每个单词已经转换成1*4的一个向量(或者叫Tensor), 比如下图 (当然实际场景里尺寸没有那么小,通常尺寸是1*512或者1*1024)

由这些向量组成一个list. [x1,x2,x3…], 至于一个list的尺寸是多少, list的尺寸是可以设置的超参,通常是训练集的最长句子的长度. (长度不足的在后面补[PAD])
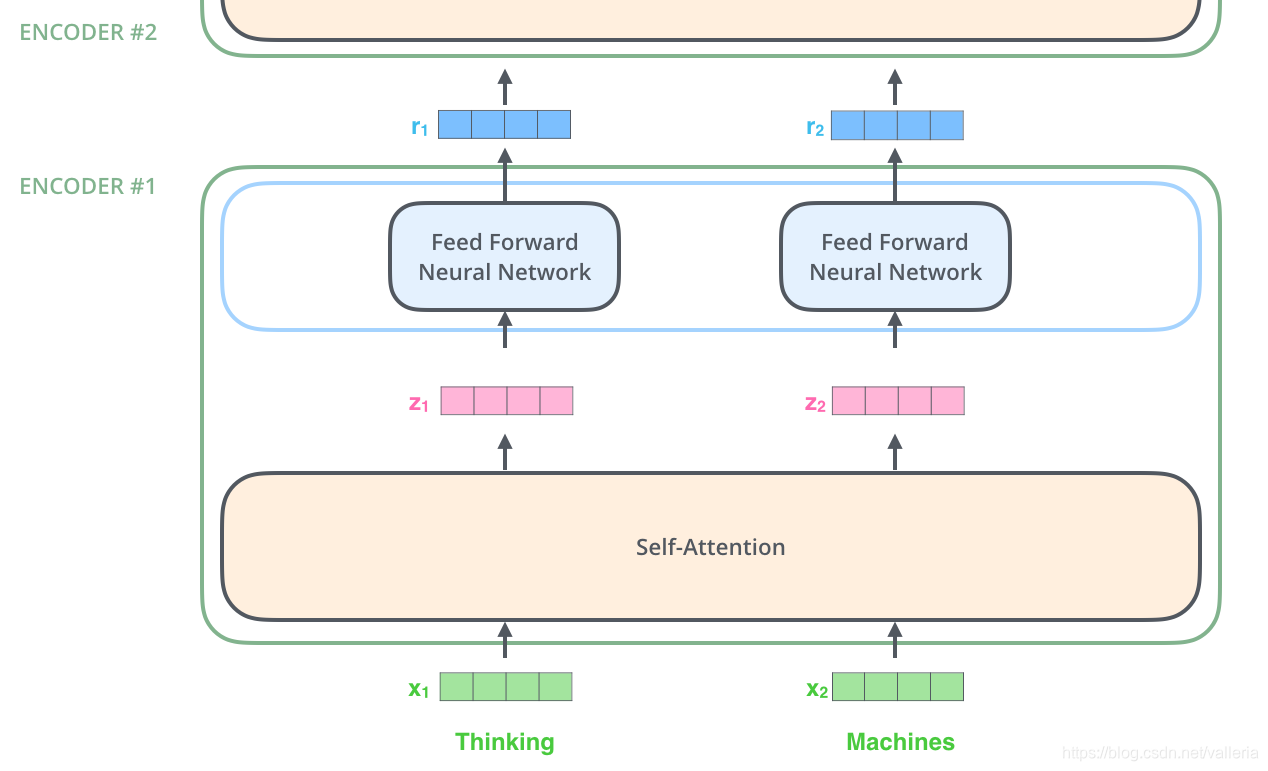
这里能看到Transformer的一个关键特性,每个位置的词仅仅流过它自己的编码器路径。在self-attention层中,这些路径两两之间是相互依赖的。重点之一来了!!! 前向网络层没有这些依赖性,但这些路径在流经前向网络时可以并行执行. (记忆前文所说的,为什么transformer能够实现并行计算)
3.self-attention层
self-attention比普通attention有什么改进. 举个别人的例子, 这句话
The animal didn’t cross the street because it was too tired
普通attention无法获取it和animal之间的关联. 因为decoder部分取用encoder部分的信息. 但encoder部分内部之间没有作关联处理.
而self-attention, encoder可以取用来源于自己的句子信息, 即可以取到it和animal之前的信息(我取用了我自己的信息)
Self-attention即K=V=Q,例如输入一个句子,那么里面的每个词都要和该句子中的所有词进行attention计算。目的是学习句子内部的词依赖关系,捕获句子的内部结构。
这里就再强调一下为什么需要self-attention: 实现了seq2seq不能做到的并行计算,并且从结构上代替了seq2seq.
self-attention具体如何计算===
(这里别人讲的比较清楚,直接复制了,只做了小修改和备注)
我们先看下如何计算self-attention的向量,再看下如何以矩阵方式计算。
简单向量计算:
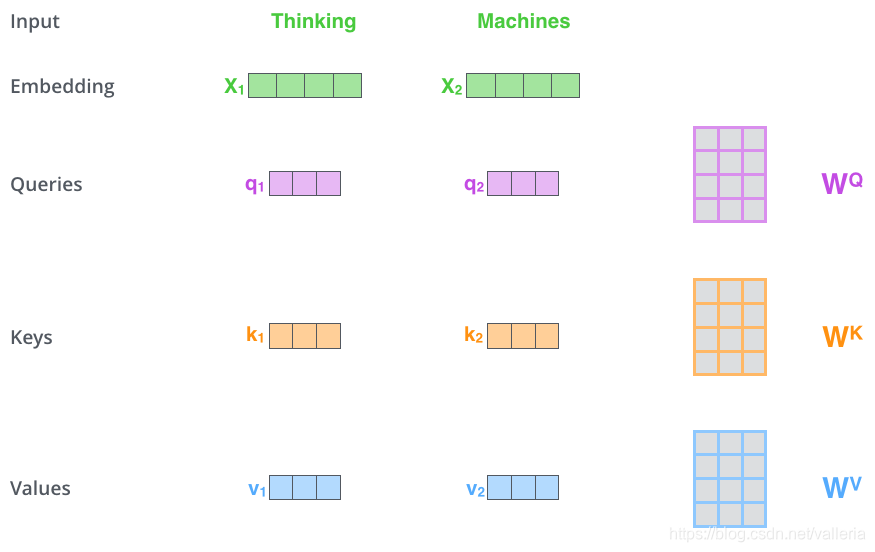
第一步,根据编码器的输入向量,生成三个向量,比如,对每个词向量,生成query-vec(查询向量), key-vec(键向量), value-vec(值向量),生成方法为分别乘以三个矩阵,这些矩阵在训练过程中需要学习。【注意:不是每个词向量独享3个matrix,而是所有输入共享3个转换矩阵;权重矩阵是基于输入位置的转换矩阵;有个可以尝试的点,如果每个词独享一个转换矩阵,会不会效果更厉害呢?】
注意到这些新向量的维度比输入词向量的维度要小(512–>64),并不是必须要小的,是为了让多头attention的计算更稳定。
看图, queries就是我们的查询向量, keys是键向量, values是值向量, q1,k1,v1这三个向量一开始其实是相等的
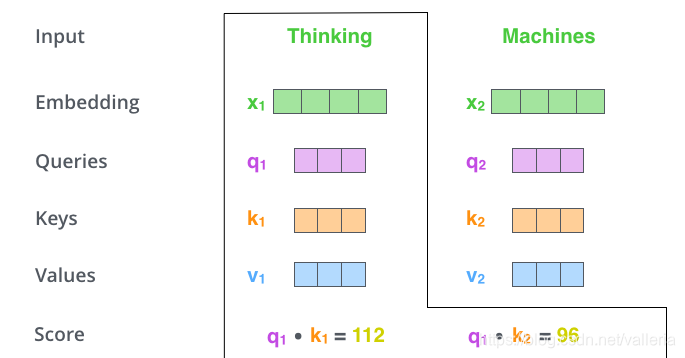
第二步,计算attention就是计算一个分值。对“Thinking Matchines”这句话,对“Thinking”计算attention 分值。我们需要计算每个词与“Thinking”的评估分,这个分决定着编码“Thinking”时(某个固定位置时),每个输入词需要集中多少关注度。
这个分,通过“Thing”对应query-vector与所有词的key-vec依次做点积得到。所以当我们处理位置#1时,第一个分值是q1和k1的点积,第二个分值是q1和k2的点积。
第三步和第四步,除以8(√64=8, 64来源于原论文里键向量key-vec的维数)
这样做目的, 按照论文作者说梯度会更稳定. 然后加上softmax操作,归一化.
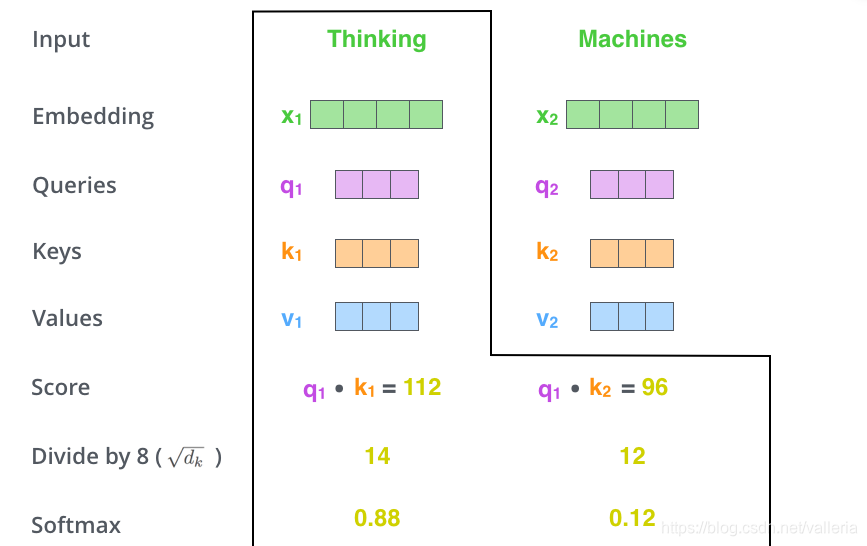
softmax分值决定着在这个位置,每个词的表达程度(关注度)。很明显,这个位置的词应该有最高的归一化分数,但大部分时候总是有助于关注该词的相关的词。
第五步,将softmax分值与value-vec按位相乘。保留关注词的value值,削弱非相关词的value值。
第六步,将所有加权向量加和,产生该位置的self-attention的输出结果。
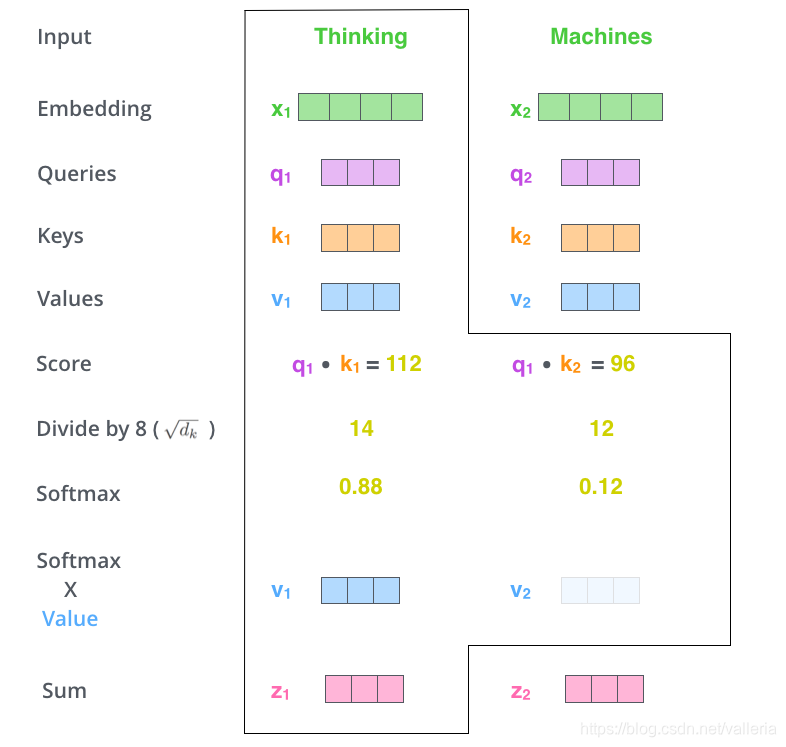 即z1=v1*0.88+v2*0.12
即z1=v1*0.88+v2*0.12
实际操作中的运算:
实际操作中,就变成了矩阵运算.
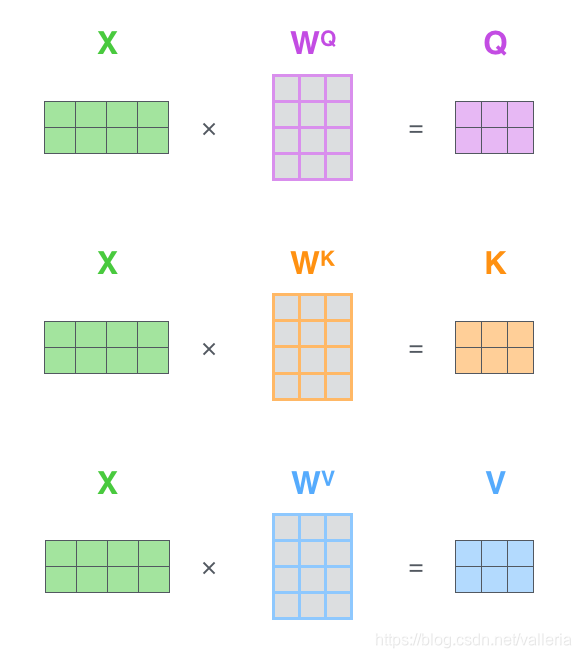
首先, 计算为我们的查询矩阵,键矩阵和值矩阵(query/key/value matrix), 将所有输入词向量合并成输入矩阵X, 并且将其分别乘以权重矩阵Wq,Wk,Wv
然后, 将步骤2~6合并成一个计算self-attention层输出的公式
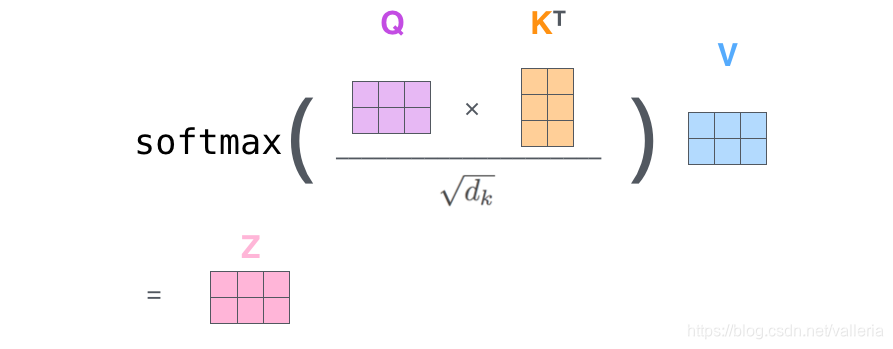
这里 Q(查询矩阵)*KT(键矩阵的转置)计算结果为一个2*2矩阵, 2*2 乘以v(2*3形状的值矩阵)= z(2*3形状的输出), 在和z相乘的过程中,已经自动完成了上一小节所说的加权向量加和, z的第一行就是上一小节里的z1, 第二行就是上一小节里的z2.
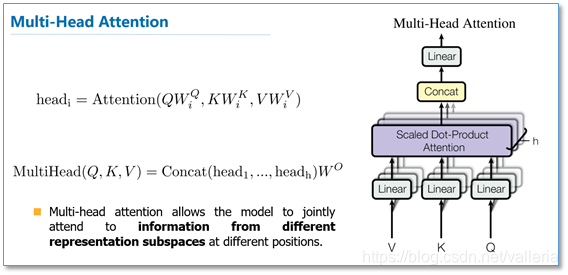
4.多头机制 Multi-head
多头机制有什么好处?
- 提高了模型关注不同位置的能力.
一般情况下,一个注意力机制下,模型可能只能关注到一两个单词, 多头注意力机制可以使模型有机会关注到其他更多的单词.
比如说"我在外滩肯德基吃饭".
提问:“你在哪里吃饭?” “你在吃什么?” 显然这两个问题需要关注到句子里不同的部分.
2.提供了多种"子空间表达方式". 如下图,我们会设定8个查询矩阵,键矩阵和值矩阵(query/key/value matrix)(共计24个=8*3) 每个矩阵都会单独随机初始化. 经过训练之后,输入向量可以被映射到不同的子表达空间中.
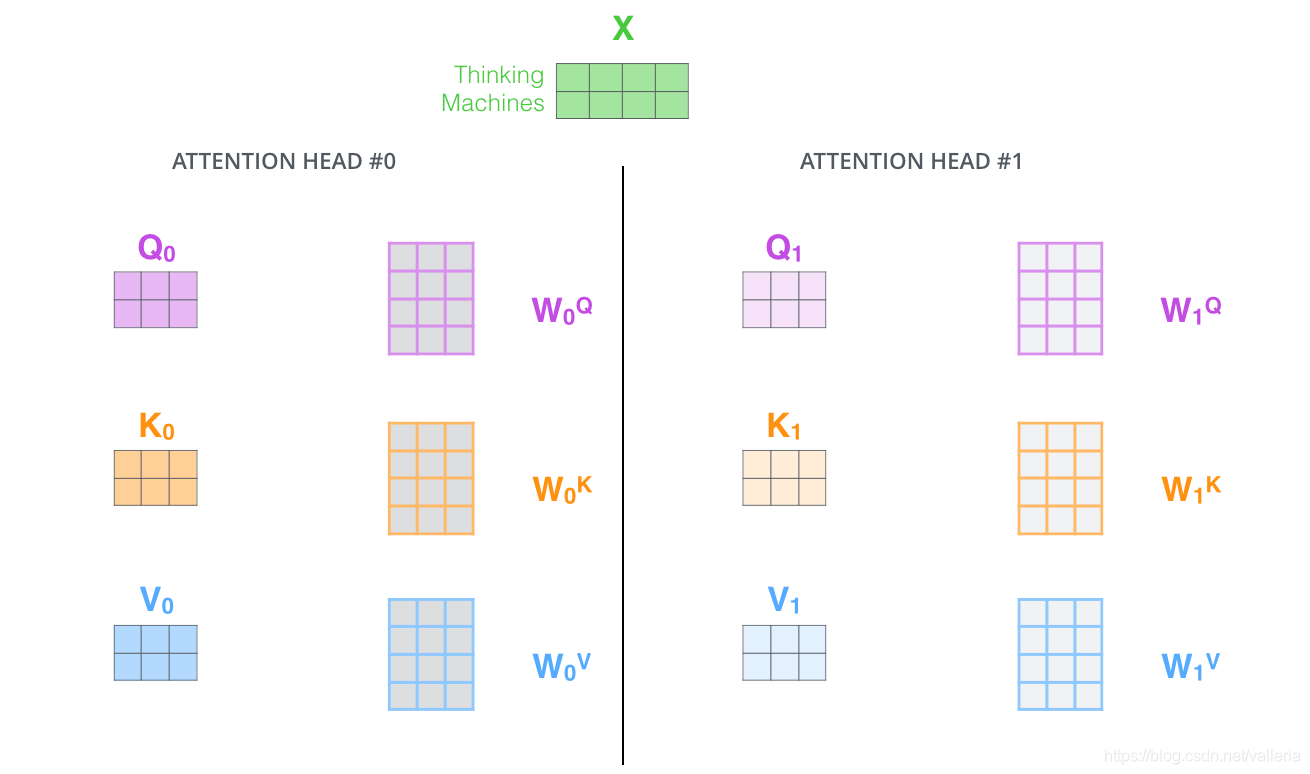
区别: BERT里是怎么做的? 初始化同一个Q,K,V, 但是让他们经过(乘以)8个不同的linear层. 这8个linear层参数是随机初始化的. 这么做也可以达到同样目的.
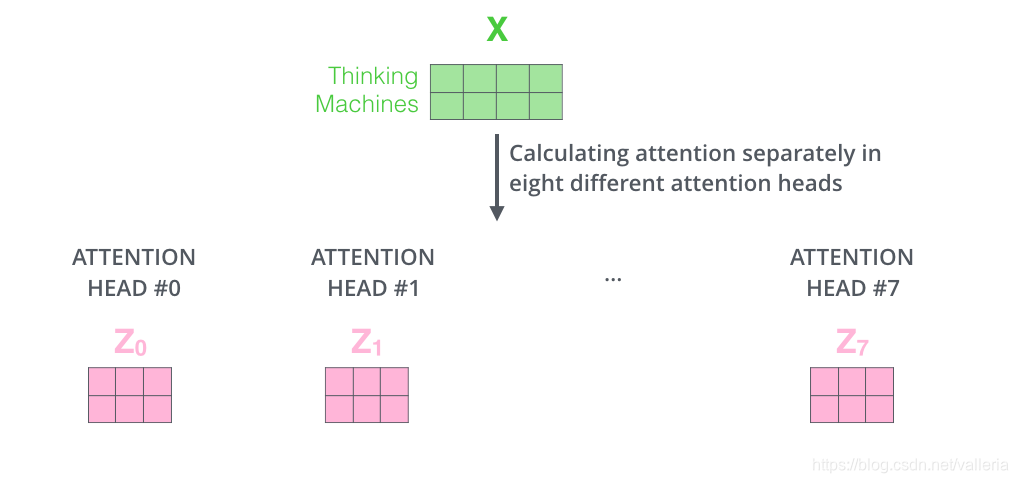
计算self-attention的方法和上一节提到的一样,只是做了8次, 得到8个z, 即z0,z1,z2,…z7
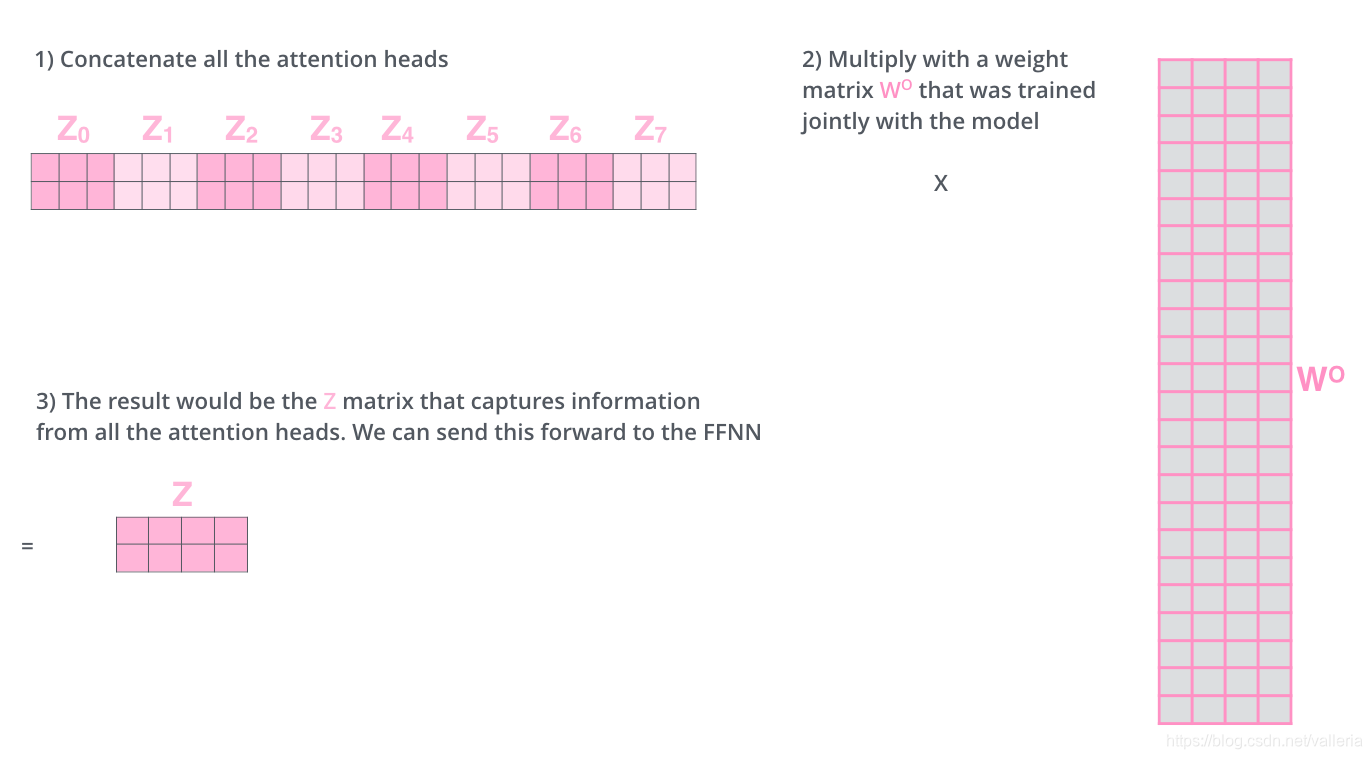
因为前向网络并不能接收八个矩阵,而是希望输入是一个矩阵,所以就把八个矩阵合并成一个矩阵(concat操作)
1) 八个矩阵连在一起
2) 然后和一个权重矩阵w0相乘. 这个w0也是跟随者着模型一起训练的.
3) 按照下图尺寸, 2*24 矩阵 乘以 24*4矩阵=Z矩阵 (2*4矩阵), 这个Z矩阵会被送入下一步的"前向网络层"
下图是完整流程
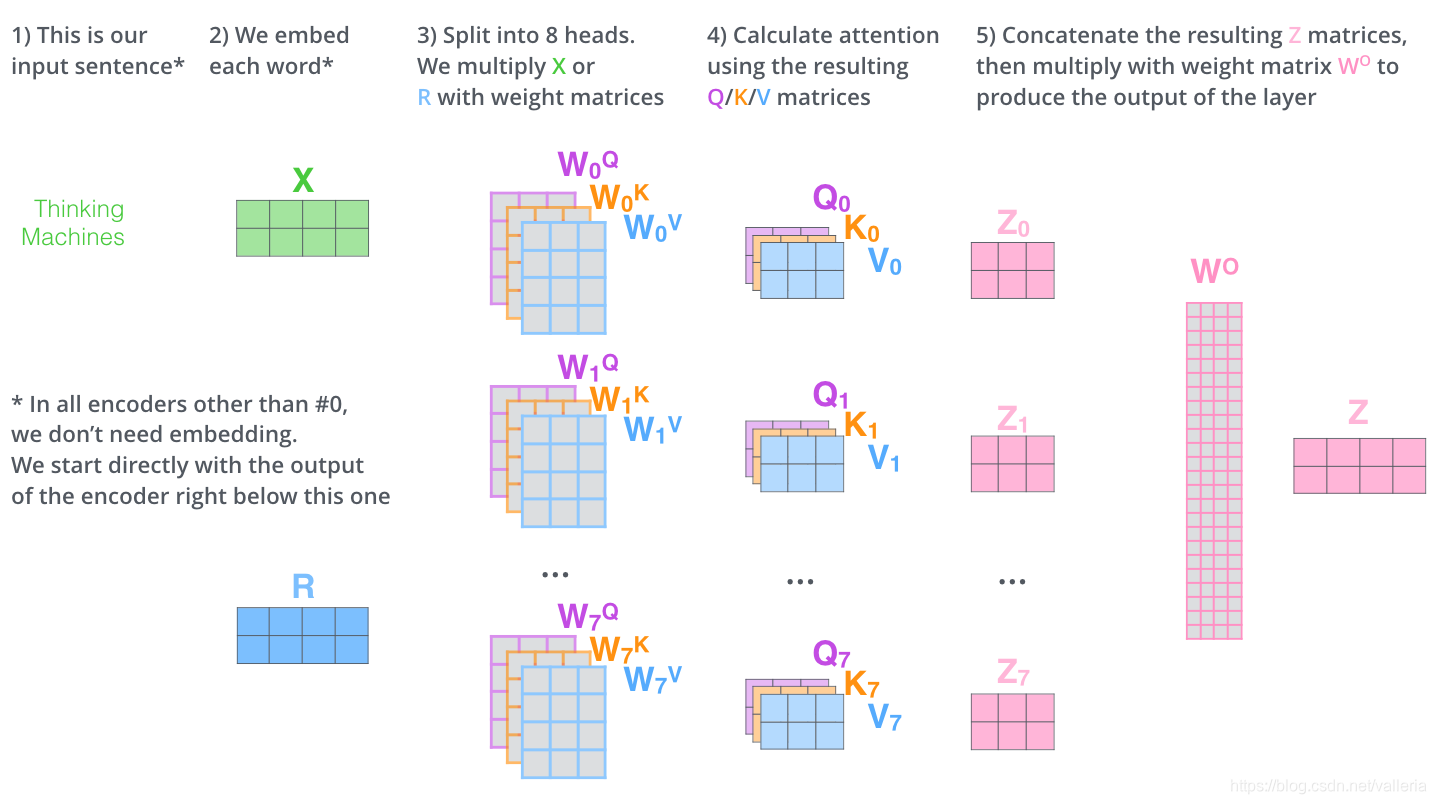
注意, 其实八个QKV有可能训练到最后长一样.
5.输入语句中词的顺序(Positional Encoding)
由于本模型没有使用循环或者卷积神经网络,我们需要额外的信息来表达词的顺序.
transformer模型对每个输入词嵌入(embedding,就是上文中绿色格子的小x矩阵)额外加入了一个向量,这些向量遵循模型学习的指定模式. 这样可以帮助词定位自己的位置,或者在句子中不同词之间的距离. 直觉上看,在词嵌入中加入这些向量,可以让他们之后在映射到Q/K/V三个矩阵以及做attention乘法的过程中,提供有意义的词嵌入间的距离.
说人话就是, 在词嵌入送入encoder之前,再加上一个位置编码(positional encoding),使得词嵌入具有一定的位置信息.
这个位置编码大概长这样↓*(图里数字存在疑问, 按照公式算出来并不对,也可能我算错了)*
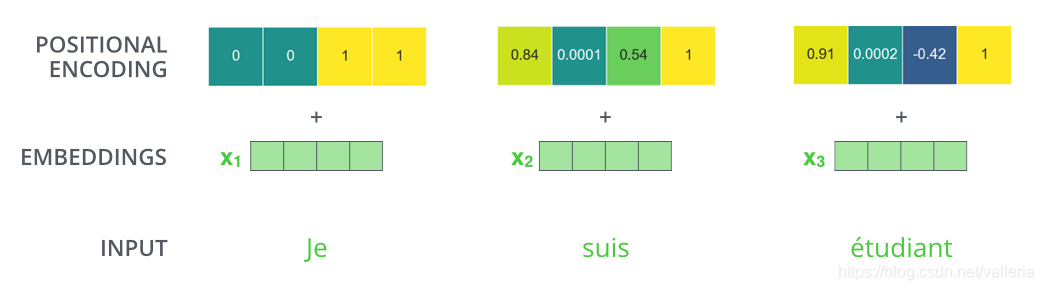
那么这个东西怎么产生?
在论文里, 用的是这样的公式:
公式里, pos就是词在输入句子(或者说输入的sequence)里的位置, i是词向量位置,即 2i 表示偶数位置,2i+1 表示奇数位置. dmodel的大小就是单词embedding的大小(在上图中,就是4)
这样PE是一个二维矩阵, 列数=词向量(embedding)大小, 行数=输入句子中词的个数(或者说输入sequence的长度). 举例,PE(0,3)就是句子里第一个词的第4个词向量.
这样, 上述公式表示在每个词语的词向量的偶数位置添加sin变量,奇数位置添加cos变量. 注意i是从0开始的.
解说参考: https://blog.csdn.net/Flying_sfeng/article/details/100996524
代码实现
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0.0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
return self.dropout
6.剩余东西
再具体一点,其实每个self-attention层和前向层后,都还要跟一个normalization.
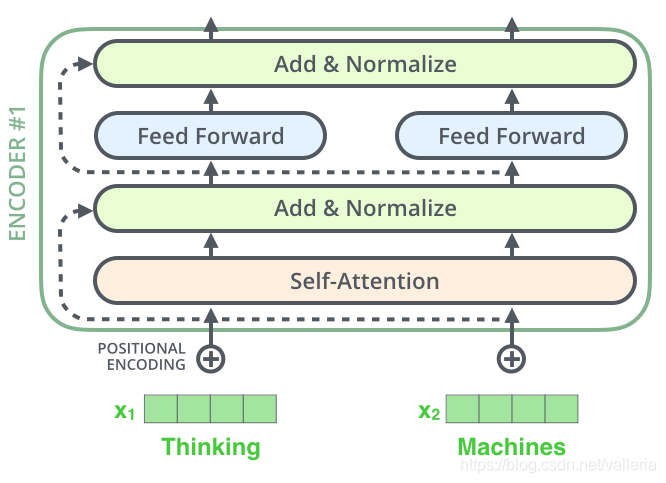
再细一点看下Add&Normalize这层,长这样,将X和Z相加后,做一个layer normalization:
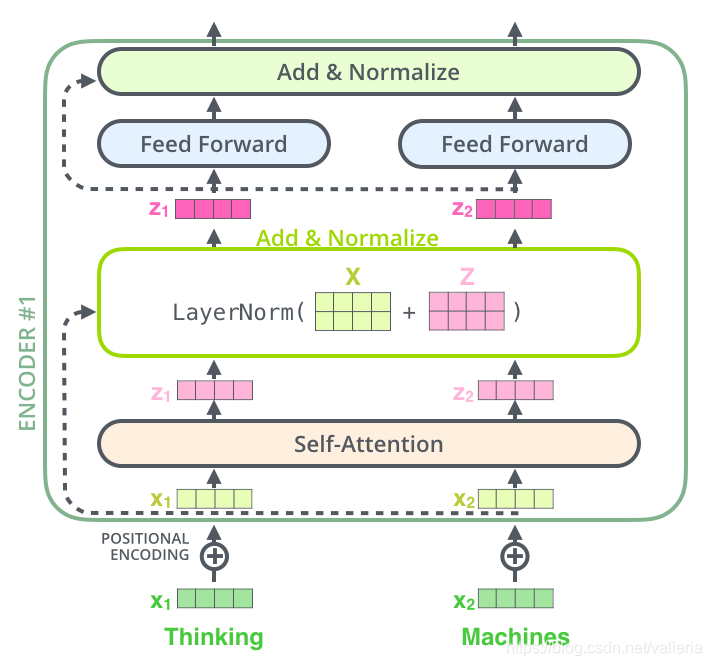
解码器中也是一样:

编码器(Encoder)部分到此为止================================
7.解码器(Decoder)
看个GIF:
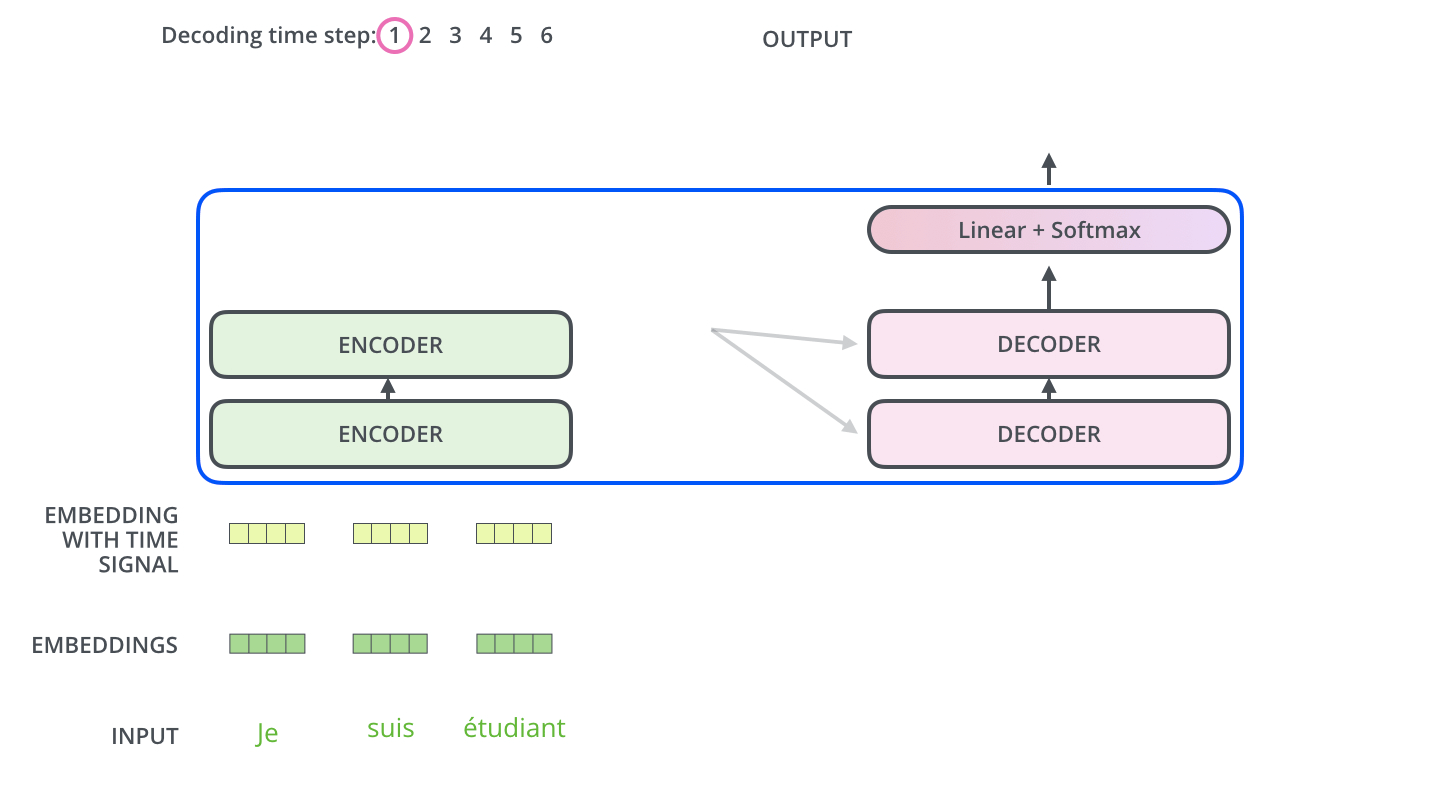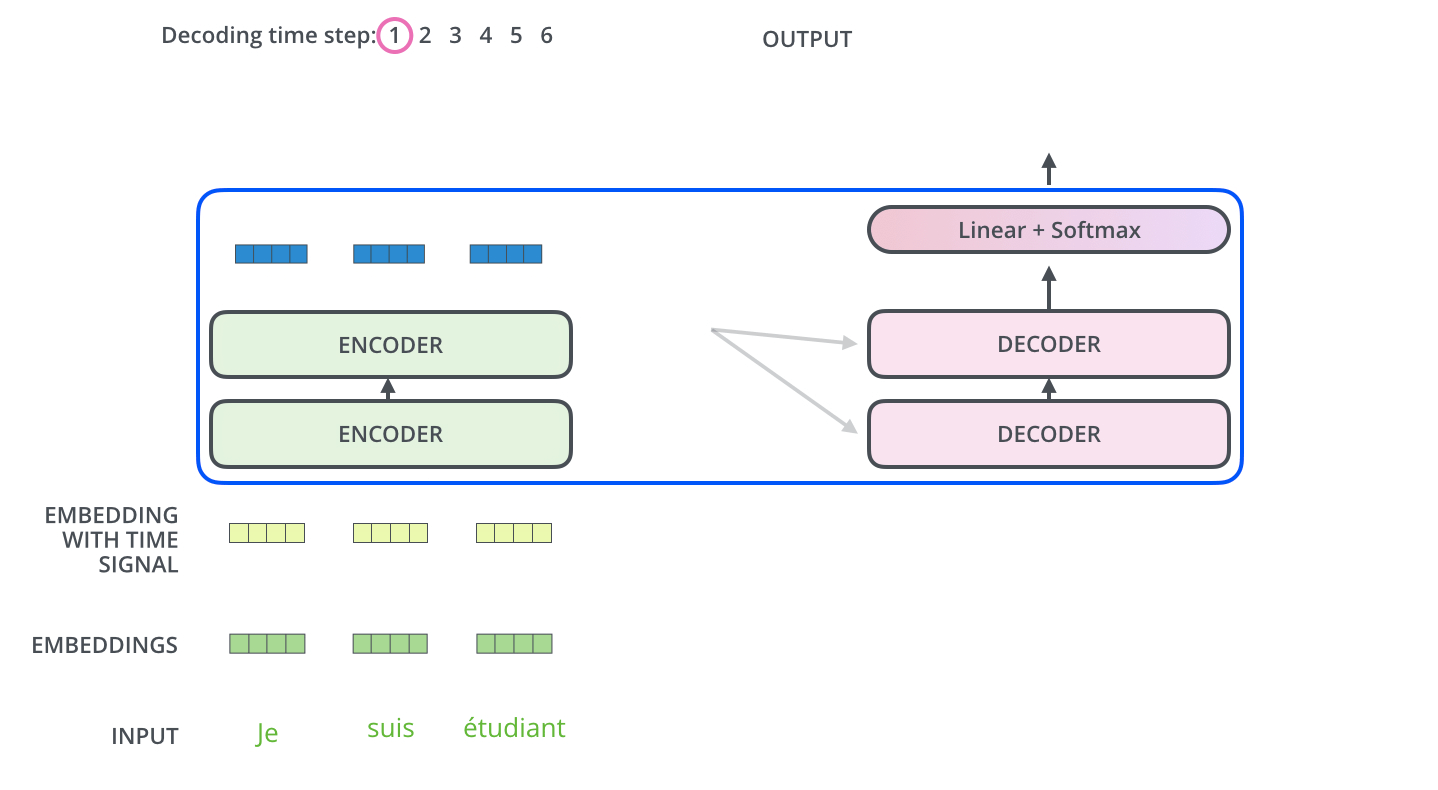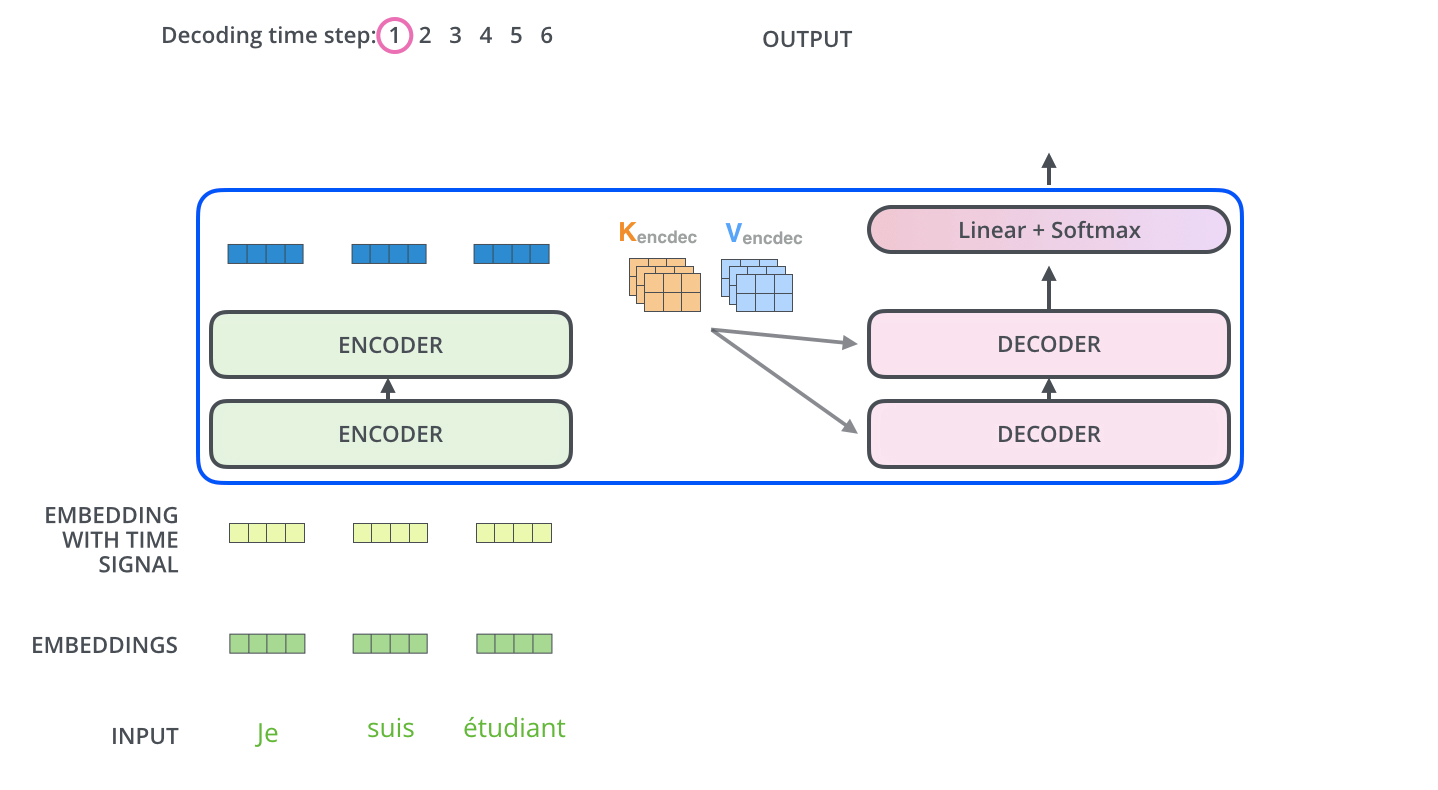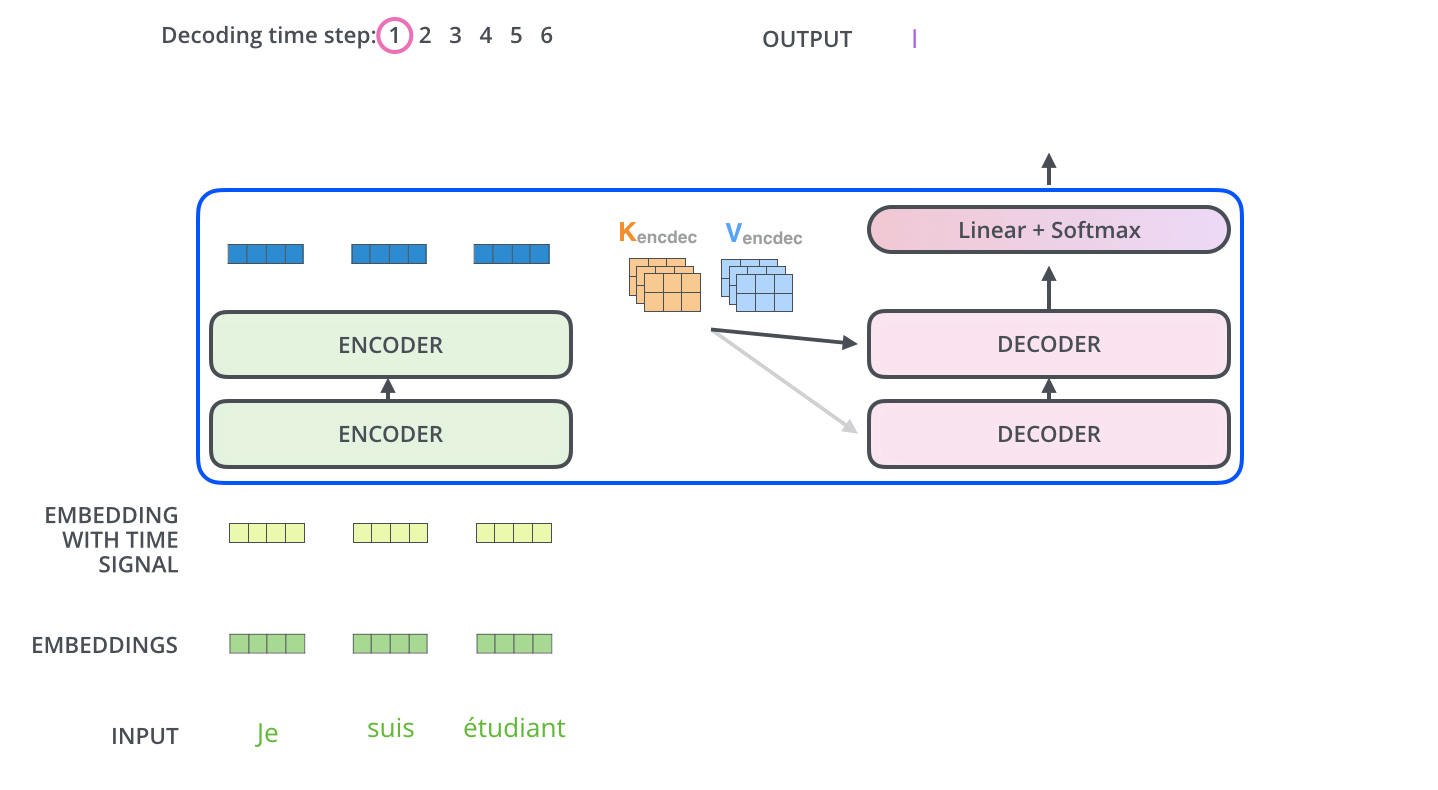
在编码之后,是解码过程;解码的每一步输出一个元素作输出序列,动画已经蛮清楚了.
在解码器中的self attention 层与编码器中的稍有不同,在解码器中,self-attention 层仅仅允许关注早于当前输出的位置. 在softmax之前,通过遮挡未来位置(将它们设置为-inf,即mask)来实现.
8.最后输出层
decoder出来后会经过一个线性层(linear)和softmax层. 线性层就是一个FC(全连接层), 用softmax看哪个词概率最高就输出哪个.
