文章目录
Introduction
Bert是无监督学习的transformer,transformer是一个seq2seq的model,而transformer的重点就是其里面大量的用到了self-attention这种特殊的layer。
其实Transformer在17年的时候就已经出现,paper链接:Attention is all you need。在此之前,一般想要处理一个sequence的问题,首先想到的是单向RNN结构,或者是双向RNN结构。RNN非常适合处理input是有序列的一个状况,但是其有一个问题,那就是无法并行化计算。
以下面一个双向RNN结构为例:
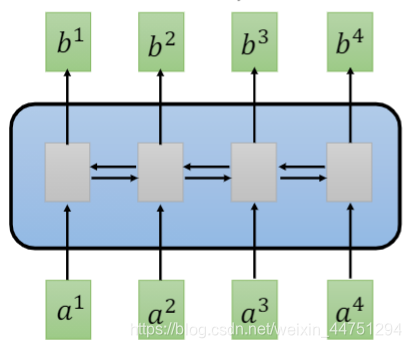
在单向RNN结构中,需要先看a1,a2,a3,a4后,才可以输出b4;而双向RNN结构还需从后往前递推计算,这显然是不可以平行化计算的,因为在计算a4之前,要先得到输入a3后的结果;而在计算a3前,要先得到输入a2后的结果,在这个计算的过程中,存在了一个等待的时间。
而这个等待的时间,可以由CNN来解决。可以知道CNN也可以做到输入是一个sequence,输出也是一个sequence。而如果想要CNN可以观测到更多的信息甚至是全局的信息,可以将输出的结果再丢去一个filter中。而CNN的卷积操作,是可以平行华处理的,也就是不需要等待的时间。不需要像RNN一样,等待前一个才能处理后一个,对于CNN结构来说,所以的filter都是可以同时的计算的。但是其有一个缺点,就是一定要叠很多层才能观测到比较长期的咨询,而对于一些全局的咨询,他是无法满足的,其只能看到比较局部的咨询。
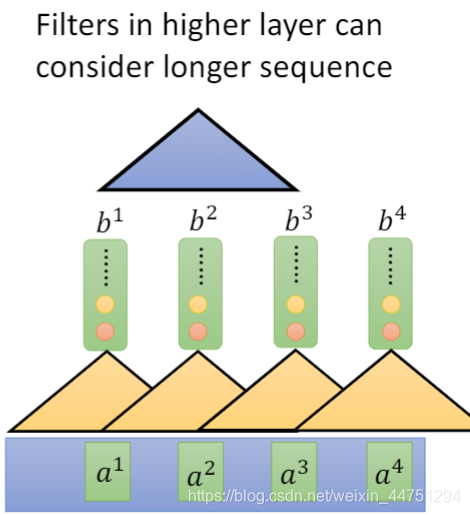
所以,如何既可以实现运算的并行化处理,同时可以不局限于局部的咨询,可以查看全局的咨询呢?Transformer中用到的self-attention就可以做到这一点。self-attention也是输入是一个sequence,而且输出是一个sequence,而且这个计算的过程还是同时计算的。
所以,self-attention layer其实可以完全取代RNN结构,RNN能够做到的,self-attention layer也可以做到,甚至做得更好更快。
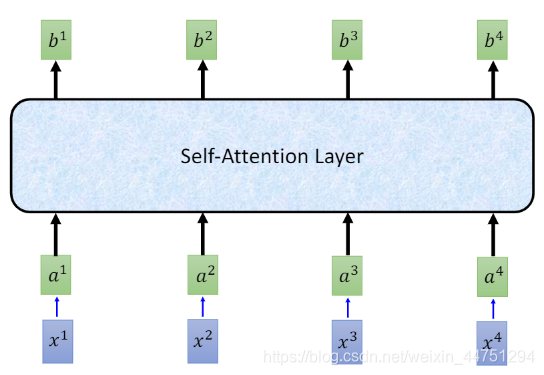
下面正式开始介绍self-attention layer
一、self-attention
1.直观展示
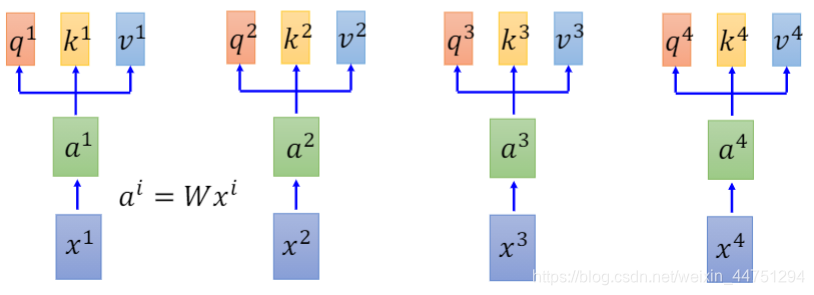
首先,对于输入分别进行Embedding操作,将其变成一个vector。假设有四个输入{ x 1 , x 2 , x 3 , x 4 x_{1},x_{2},x_{3},x_{4} x1,x2,x3,x4},分别进行embedding操作,使其变成{ a 1 , a 2 , a 3 , a 4 a_{1},a_{2},a_{3},a_{4} a1,a2,a3,a4}。这个转换关系可以通过一个矩阵运算实现: a i = W x i a_{i} = Wx_{i} ai=Wxi.
现在得到了embedding后的输入{ a 1 , a 2 , a 3 , a 4 a_{1},a_{2},a_{3},a_{4} a1,a2,a3,a4},将这些输入分别乘上三个不同的transformation,也就是再次进行三次的矩阵运算,与三个不同的矩阵相乘得到三个不同的vector。这三个不同的vector将其命名为 q , k , v q,k,v q,k,v。
其含义分别如下:其中 W q , W k , W v W_{q},W_{k},W_{v} Wq,Wk,Wv可以通过训练而改变的参数
- q:query(to match other) 用来与其他k计算match程度
q i = W q a i q_{i} = W_{q}a_{i} qi=Wqai - k:key(to be matched)用来被其他q计算match程度
k i = W k a i k_{i} = W_{k}a_{i} ki=Wkai - v:information to be extracted
v i = W v a i v_{i} = W_{v}a_{i} vi=Wvai
所以,现在每一个时间戳都有 q , k , v q,k,v q,k,v三个不同的vector。
然后,需要对每一个 q q q,去对每一个 k k k做attention,这一步类似于之前提到的attention model中做weight sum提取information的操作。
所以,对于上图的四个输入,以 q 1 q_{1} q1为例,分别将其与 k 1 , k 2 , k 3 , k 4 k_{1},k_{2},k_{3},k_{4} k1,k2,k3,k4做attention操作。attnetion操作其实就是输出一个分数,来描述输入的两个vector有多匹配。做完attention操作后得到了四个结果: α 1 , 1 , α 1 , 2 , α 1 , 3 , α 1 , 4 α_{1,1},α_{1,2},α_{1,3},α_{1,4} α1,1,α1,2,α1,3,α1,4,而此处的attention操作是Scaled Dot-Product Attention:
α 1 , i = q 1 ⋅ k i / d α_{1,i} = q_{1}·k_{i}/ \sqrt{d} α1,i=q1⋅ki/d
其中,d是q与k的dim。矩阵点乘后会得到一个数值,而这个数值会随着q与k的dim增大而增大,方差也会增大。所以会除以 d \sqrt{d} d来平衡数值。

然后会将 α 1 , 1 , α 1 , 2 , α 1 , 3 , α 1 , 4 α_{1,1},α_{1,2},α_{1,3},α_{1,4} α1,1,α1,2,α1,3,α1,4作一个softmax操作,变成 α ^ 1 , 1 , α ^ 1 , 2 , α ^ 1 , 3 , α ^ 1 , 4 \hat{α}_{1,1},\hat{α}_{1,2},\hat{α}_{1,3},\hat{α}_{1,4} α^1,1,α^1,2,α^1,3,α^1,4
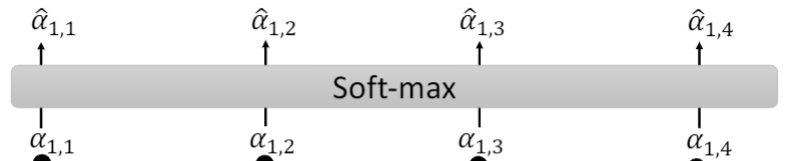
而现在得到了softmax结果之后,会分别用 α ^ 1 , i \hat{α}_{1,i} α^1,i与 v i v_{i} vi相乘,然后类似的,将这些结果作一个weight sum,就得到了一个输出结果 b 1 b_{1} b1,其中weight sum具体的公式为:
b 1 = ∑ α ^ 1 , i v i b_{1} = \sum{\hat{α}_{1,i}v_{i}} b1=∑α^1,ivi
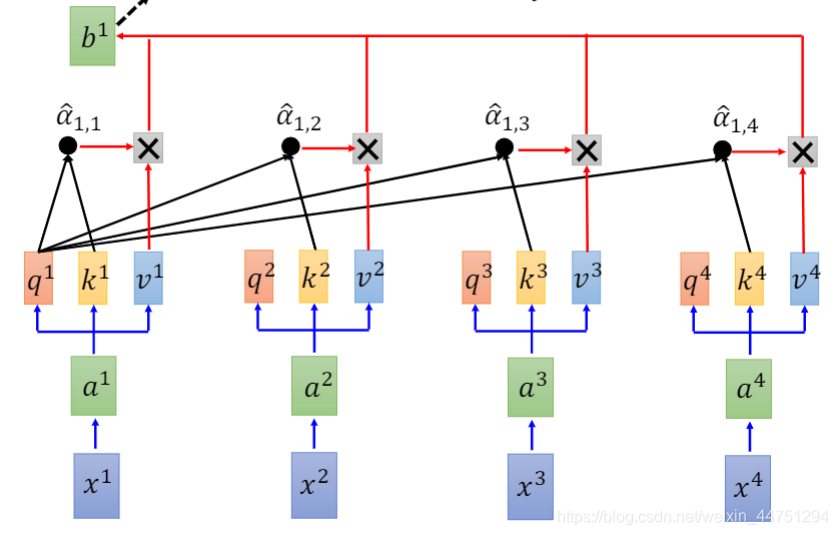
可以发现,在得到 b 1 b_{1} b1的时候,也就是第一个时间戳的输出值时,已经是参考了全部的sequence信息。同样的,其他的任何的一个输出 b i b_{i} bi,同样也是参考了整个序列信息之后得到的结果。
而对于self-attention来说,如果不想考虑整个sequence的信息,而只想考虑局部的信息,对于 b 1 b_{1} b1来说,只需要将 α ^ 1 , 2 , α ^ 1 , 3 , α ^ 1 , 4 \hat{α}_{1,2},\hat{α}_{1,3},\hat{α}_{1,4} α^1,2,α^1,3,α^1,4置0即可,这样就不会考虑其他的咨询。而对于self-attention来说,默认是考虑全局的vector的。
同样的,将以上的这个操作同时计算出 b 2 , b 4 , b 4 b_{2},b_{4},b_{4} b2,b4,b4
b 2 = ∑ α ^ 2 , i v i b_{2} = \sum{\hat{α}_{2,i}v_{i}} b2=∑α^2,ivi

可以注意到,在计算 b 1 b_{1} b1的时候,也可以同时计算其他的输出 b i b_{i} bi,所以对于self-attention来说是可以平行化操作的。下一节会进一步详细说明。
所以,self-attention做的事情其实是和RNN类似的,只是 b 1 b_{1} b1到 b 4 b_{4} b4可以平行的计算出来。
2.矩阵展示
在上面的直观展示中,已经知道了为什么self-attention可以考虑全局的咨询。而以下进一步用矩阵运算来表示以上的操作流程,以说明为什么self-attention是如何实现平行化操作的。(其实就是基于矩阵运算)
上面有提到,输入 x i x_{i} xi经过embedding处理之后会得到 a i a_{i} ai,而基于这个 a i a_{i} ai,分别乘上不同的矩阵 W q , W k , W v W_{q},W_{k},W_{v} Wq,Wk,Wv会得到三个vector,分别是 q , k , v q,k,v q,k,v。
q i = W q a i k i = W k a i v i = W v a i q_{i} = W_{q}a_{i} \\ k_{i} = W_{k}a_{i} \\ v_{i} = W_{v}a_{i} qi=Wqaiki=Wkaivi=Wvai
而现在,对于整个序列来说。 a 1 a_{1} a1乘以一个矩阵参数 W q W_{q} Wq就会变成 q 1 q_{1} q1,而 a 2 a_{2} a2乘以一个矩阵参数 W q W_{q} Wq就会变成 q 2 q_{2} q2, a 3 a_{3} a3乘以一个矩阵参数 W q W_{q} Wq就会变成 q 3 q_{3} q3,同样的 a 4 a_{4} a4乘以一个矩阵参数 W q W_{q} Wq就会变成 q 4 q_{4} q4。
所以,其实可以把 a 1 , a 2 , a 3 , a 4 a_{1},a_{2},a_{3},a_{4} a1,a2,a3,a4拼接成一个矩阵,同样的其输出就变成了 q i q_{i} qi的矩阵,将其称为矩阵 Q Q Q。在线性代数中是可以这样实现的。
同样的,将 a 1 , a 2 , a 3 , a 4 a_{1},a_{2},a_{3},a_{4} a1,a2,a3,a4串起来,分别乘上 W k W_{k} Wk与 W v W_{v} Wv,就得到了矩阵 K , V K,V K,V。其中矩阵 Q , K , V Q,K,V Q,K,V中的每一列就代表着 q i , k i , v i q_{i},k_{i},v_{i} qi,ki,vi。
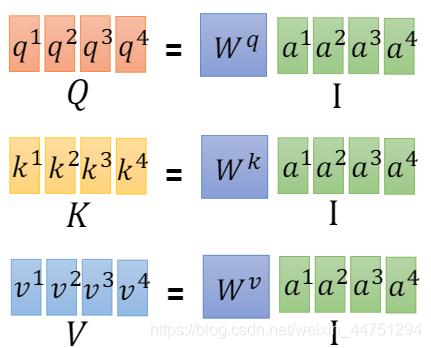
接下来,可以观察 α 1 , 1 , α 1 , 2 , α 1 , 3 , α 1 , 4 α_{1,1},α_{1,2},α_{1,3},α_{1,4} α1,1,α1,2,α1,3,α1,4的计算,可以得出一个公式:
α 1 , i = k i ⋅ q 1 / d α_{1,i} = k_{i}·q_{1}/\sqrt{d} α1,i=ki⋅q1/d
所以, α 1 , 1 , α 1 , 2 , α 1 , 3 , α 1 , 4 α_{1,1},α_{1,2},α_{1,3},α_{1,4} α1,1,α1,2,α1,3,α1,4的计算也是可以平行化的。
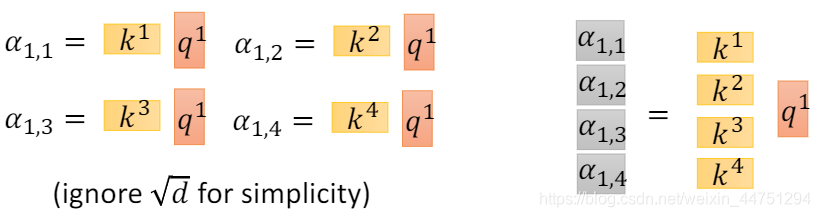
而以上操作是对于 q 1 q_{1} q1作的操作,对其余的 q 2 , q 3 , q 4 q_{2},q_{3},q_{4} q2,q3,q4也是一样的,所以可以把 q 1 , q 2 , q 3 , q 4 q_{1},q_{2},q_{3},q_{4} q1,q2,q3,q4拼接成一个矩阵,同样的把 k 1 , k 2 , k 3 , k 4 k_{1},k_{2},k_{3},k_{4} k1,k2,k3,k4也拼接成一个矩阵,矩阵乘法得到的结果便是提取到的attention值 α j , i α_{j,i} αj,i。然后对 α j , i α_{j,i} αj,i作一个softmax操作,便得到 α ^ j , i \hat{α}_{j,i} α^j,i。

而最后作weight sum计算出的结果 b i b_{i} bi,同样是可以做矩阵运算的。
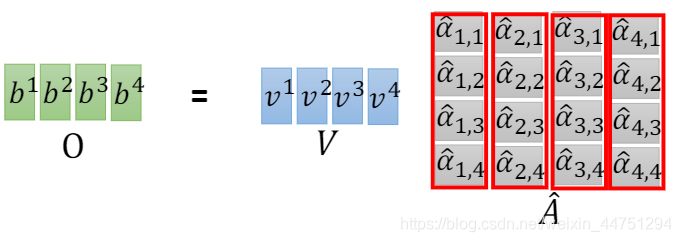
总结:
self-attention的整个流程可以如图所示
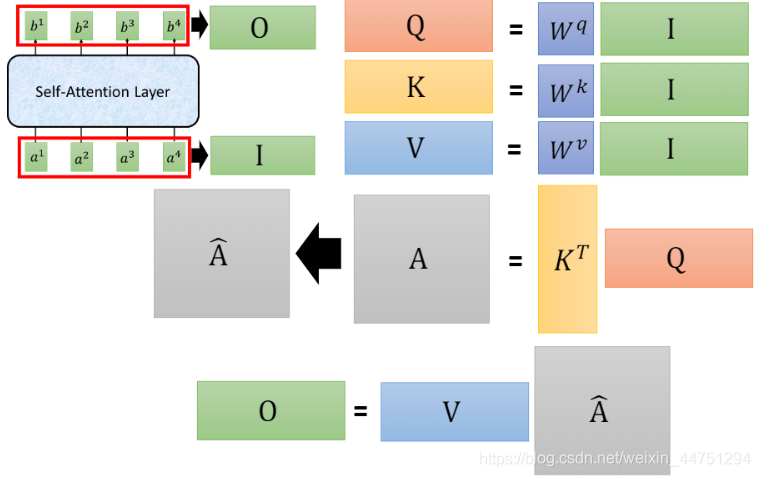
所以,可以看出,self-attention的整个流程其实就是一堆的矩阵乘法。所以是可以用GPU加速,实现平行化处理的。
二、Multi-head self-attention
Multi-head self-attention其实就是在原来一个 a i a_{i} ai分别乘上三个矩阵 W q , W k , W v W_{q},W_{k},W_{v} Wq,Wk,Wv之后,得到的 q i , k i , v i q_{i},k_{i},v_{i} qi,ki,vi的基础上,对 q i , k i , v i q_{i},k_{i},v_{i} qi,ki,vi进一步划分。
以2 heads为例,就是将 q i q_{i} qi进一步分成两个 q q q,分别为 q i , 1 , q i , 2 q_{i,1},q_{i,2} qi,1,qi,2。也就是将 q i q_{i} qi分别乘上两个不同的矩阵 W q , 1 , W q , 2 W_{q,1},W_{q,2} Wq,1,Wq,2得到 q i , 1 , q i , 2 q_{i,1},q_{i,2} qi,1,qi,2。
q i , 1 = W q , 1 q i q i , 2 = W q , 2 q i q_{i,1} = W_{q,1}q_{i} \\ q_{i,2} = W_{q,2}q_{i} qi,1=Wq,1qiqi,2=Wq,2qi
同样的,对 k , v k,v k,v也一样,分别得到 k i , 1 , k i , 2 k_{i,1},k_{i,2} ki,1,ki,2与 v i , 1 , v i , 2 v_{i,1},v_{i,2} vi,1,vi,2
而接下来,同是做上述所介绍的self-attention。但是,只会跟对应位置的vector做一个attention。比如 q i , 1 q_{i,1} qi,1只与 k i , 1 , k j , 1 k_{i,1},k_{j,1} ki,1,kj,1做self-attention, q i , 2 q_{i,2} qi,2只与 k i , 2 , k j , 2 k_{i,2},k_{j,2} ki,2,kj,2做self-attention。然后再分别与 v i , 1 , v j , 1 v_{i,1},v_{j,1} vi,1,vj,1相乘,作一个weight sum计算出结果 b i , 1 b_{i,1} bi,1。
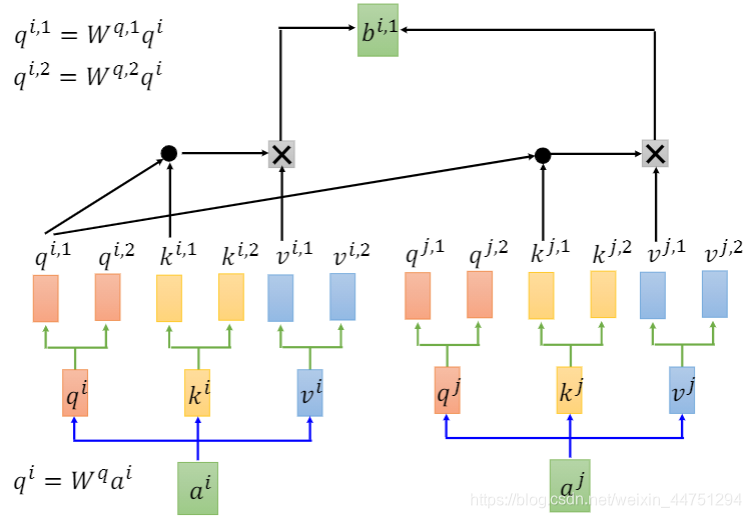
而对于 q i , 2 q_{i,2} qi,2计算出 b i , 2 b_{i,2} bi,2是一样的操作过程:
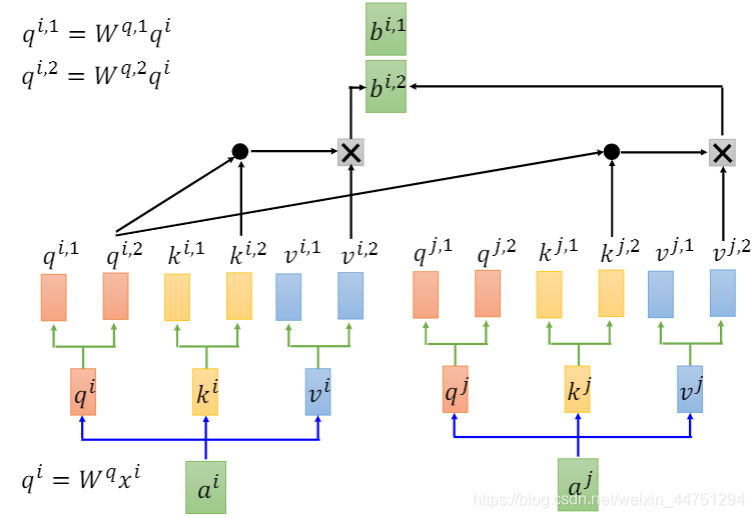
然后会将 b i , 1 b_{i,1} bi,1与 b i , 2 b_{i,2} bi,2作一个拼接,然后可以再乘以一个矩阵来降维,变成 b i b_{i} bi
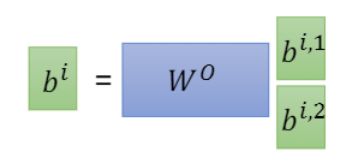
Multi-head self-attention的好处是不同的head关注的点可能是不一样的,有些head关注局部咨询,而有些head关注全局咨询。
三、Positional Encoding
根据以上的介绍,现在基本上对self-attention或者是Multi-head self-attention有一个基本的了解。
但是,其实可以发现,这样做对于输入的序列信息是不重要的,其做的事情就是跟每一个输入的vector作一个attention。所以对每一个时间戳来说,资讯的远近其实是一样,所以其没有位置的概念。这不是我们想要的,所以需要将输入sequence的顺序考虑进去。
所以,现在不单单只是将输入 x i x_{i} xi经过embedding变成 a i a_{i} ai,还需要加上一个表示位置信息的vector e i e_{i} ei。对于每个位置信息,都有一个唯一的向量,将其称为positional vector e i e_{i} ei。注意这不是learn出来的,而是人为设定的,其代表了位置的资讯。
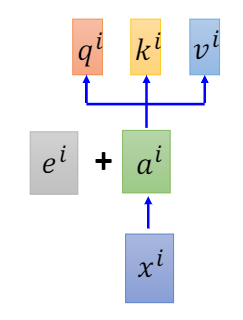
其中可能会有一个问题,为什么是两个vector相加而不是作concat操作?
李宏毅老师的一个解释是,现在可以将输入 x i x_{i} xi再追加一个独热编码的vector p i p_{i} pi,用这个vector的dim来表示其位置,如果第i th的dim为1,则表示现在是第i个位置。只有1维是1其他都是0。用其表示与哪一个x做concat。如此操作后再与一个矩阵相乘。
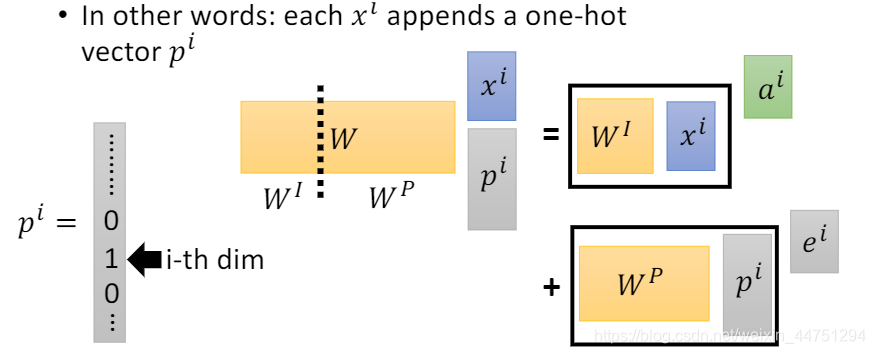
而这个矩阵 W W W其实也可以切分成两份,分别是 W I , W P W_{I},W_{P} WI,WP,经过矩阵乘法,其实看成是两部分是相乘,如图所示。而其中, W I ∗ x i W_{I}*x_{i} WI∗xi可以理解为 a i a_{i} ai,而 W P ∗ x p W_{P}*x_{p} WP∗xp可以理解为 e i e_{i} ei。
所以直接把 x i x_{i} xi与 e i e_{i} ei相加,其实也相当于作concat操作。这个操作是可以行得通的。
而其中, W P W_{P} WP是可以learn出来的,也是可以手动设置的。
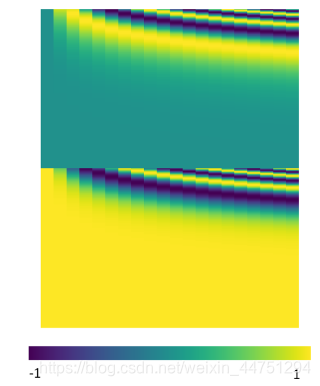
source of image: http://jalammar.github.io/illustrated-transformer/
手动设置的 W P W_{P} WP大概长这个样子
四、Transformer
接下来了解一下Transformer的整体结构,其有Encoder与Decoder两部分组成,整体结构如图所示,左边的部分是Encoder,右边的部分是Decoder。

1.Encoder
现在的Encoder里面会分成很多的block,如左图所示的Nx,也就是会重复N遍这个block结构。每一个block都是输入一排vector,然后输出一排vector;而输出的这一排vector再输入到下一个block,再输出一排vector;最后一个block会输出最终的vector sequence。
这里的一个block其实不算是一个layer,而且有好几个layer做事情。其做的事情大致如下:
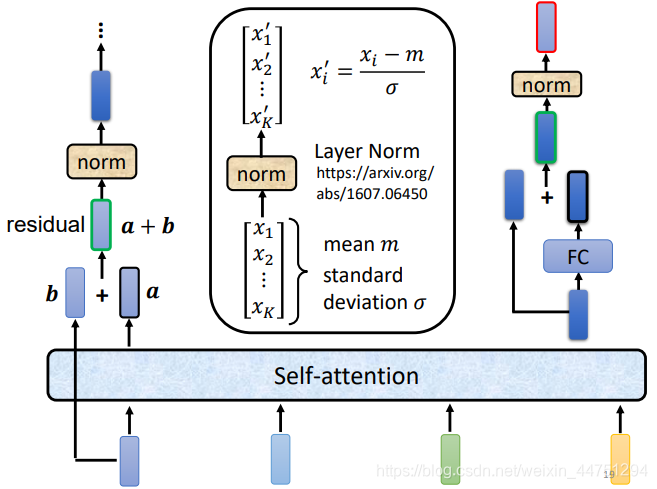
首先输入的vector b会进行一个self-attention,在考虑整个sequence的资讯,然后输出另外的一排vector a,同时得到的这个输出的vector a与原来输入的vector b做一个相加,也就是结合了ResNet的思想,然后得到新的输出a+b.这个操作称为residual connection。(可以避免梯度弥散,也就是深度网络中梯度信息可能会太小而得不到更新)
得到了residual的输出之后,会进行layer normalization(也就是对layer作归一化而不是对batch)。经过layer normalization之后,再接入一个全连接层,同时这个fc层也有residual connection的操作,得到一个新的输出,然后再进行layer normalization。至此,得到的结果才是Encoder中一个block的输出。
这时候,来看一下Encoder的结构,手写将输入经过embedding操作之后,需要加上一个位置的资讯,也就是与一个Positional Encoding相加。然后就不断的堆叠block,经过一个Multi-head self-attention,注意需要作residual connection,然后作一个layer normalization。然后再进行全连接层处理,同样需要作residual connection,然后作一个layer normalization,输出再进行下一个block的堆叠。(图中的Add & Norm就是residual connection + layer normalization操作)
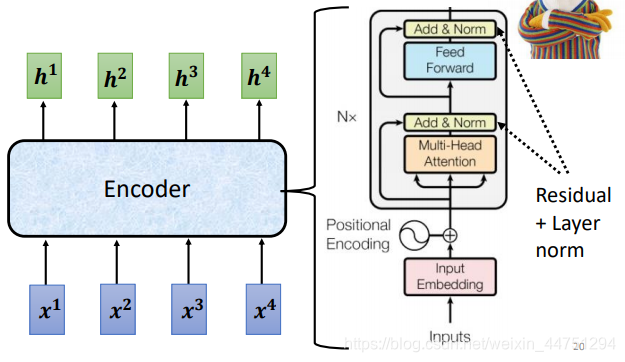
paper中的Encoder就是这样设计的,但是其实不这样设计也是可以的,所以后来又出现了一些改进结构的Transformer。原始paper的结构不一定是最好的。
2.Decoder
Decoder的结构如下:
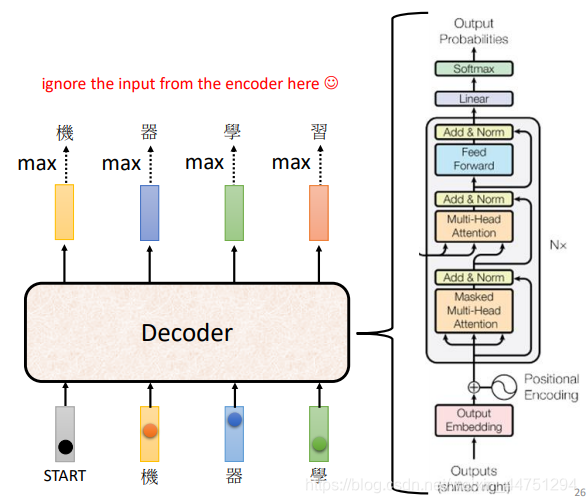
对于Decoder的结构,其实如果盖住中间的部分,Decoder与Encoder是结构是差不多的,但是需要主要,Decoder结构中block的第一个操作是Masked Multi-Head Attention,这是与Multi-Head Attention不一样的。
1)Masked Multi-Head Attention
对于Self-Attention来说,每一个输入都是考虑了全部的序列信息后再作出的输出。如下图所示,Self-Attention在输出 b 1 b_{1} b1的时候,其实是参考了 a 1 a_{1} a1到 a 4 a_{4} a4的所有资讯。
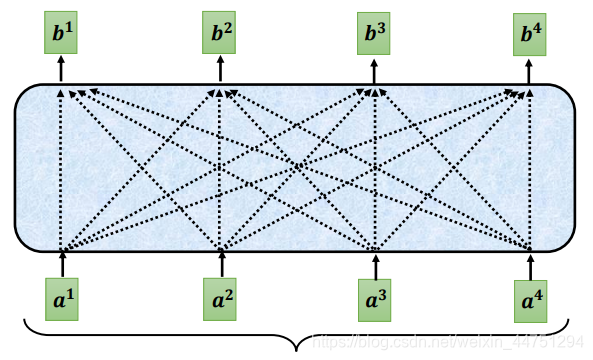
而对于Masked Self-Attention,现在不能在看右边的部分,也就是输出 b 1 b_{1} b1的时候只可以考虑 a 1 a_{1} a1的资讯,而不能考虑 a 2 , a 3 , a 4 a_{2},a_{3},a_{4} a2,a3,a4的资讯;而输出 b 2 b_{2} b2的时候只可以考虑 a 1 , a 2 a_{1},a_{2} a1,a2的资讯,而不能考虑 a 3 , a 4 a_{3},a_{4} a3,a4的资讯…
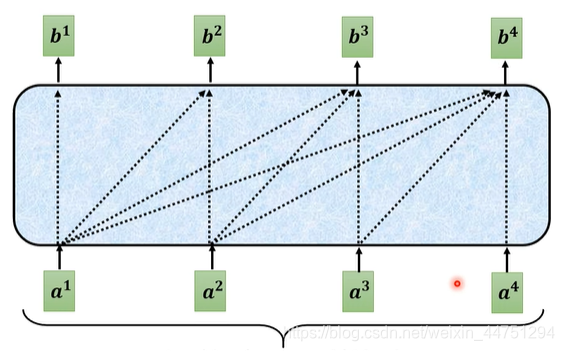
也就是在做self-attention的时候, q 2 q_{2} q2只与 k 1 , k 2 k_{1},k_{2} k1,k2作attention操作,而不与 k 3 , k 4 k_{3},k_{4} k3,k4作attention操作.

为什么需要这么做?因为Decoder一开始的运作方式是一个个的输出的,先有 a 1 a_{1} a1,再有 a 2 a_{2} a2,再有 a 3 a_{3} a3,再有 a 4 a_{4} a4的,这与self-attention的方式是不一样的。
Decoder有两种运作的方式,一种是Autoregressive,另外一种是Non-autoregressive,以下内容只介绍前者。
2)Autoregressive
一般来说,对于seq2seq模型的输出应该是没有固定大小的,有时候长有时候段,也就是我们是不知道Decoder的输出大小的,而如何解决这个不知道输出长度的问题?
其实比较简单,对于原本的一个输出,可能产生N的结果,而现在需要对这些结果作一个softmax操作,看看最应该输出那个结果。以机器翻译为例,将英语翻译成中文,而常用的中文汉字大概有4k中,所以输出是一个4k长的vector,做softmax之后得到其中概率最大的那一个来做结果。
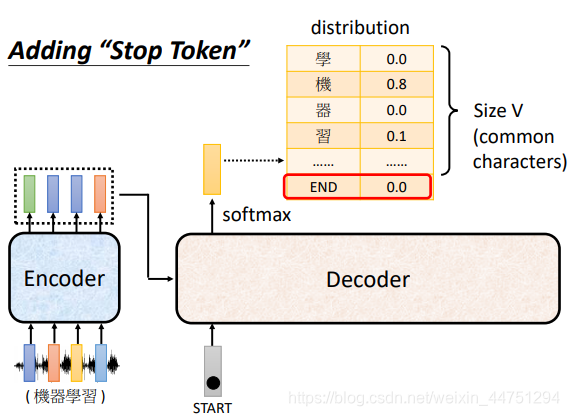
而其实,只需要在4k长的vector中append一个END结束符,让Decoder输出END的时候,就表示输出seuence已经结束,此时便可以实现不固定输出长度,但是可以输出有长有短的序列信息了。
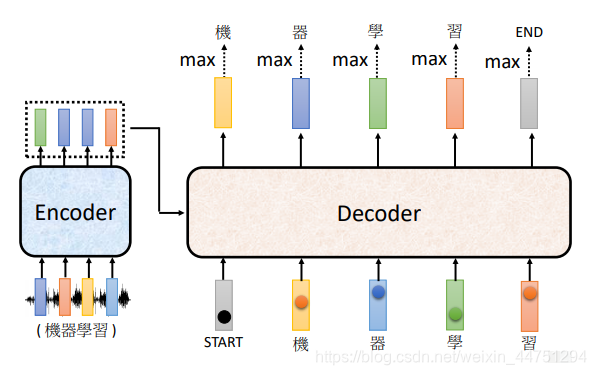
这个就是Decoder的Autoregressive的运作方式,就是Adding Stop Token的操作。
3.Cross attention
Cross attention是刚刚盖住Decoder的那一部分,其是Encoder与Decoder之间沟通的桥梁。
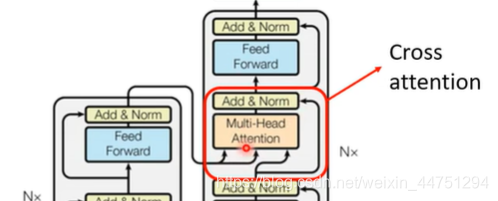
在Cross attention这一部分中,有两个输入是来自于Encoder的,只有一个输入是来自于Decoder,所以由于这两个箭头,Decoder可以得到Encoder的输出。
具体的操作过程:
对于Decoder部分来说,一开始的输入是Begin,然后经过Masked Self-attention得到一个输出,这个输出乘上矩阵 W q W_{q} Wq得到vector q。而在Encoder这边,同样的,由输入经过Self-attention得到了输出 a i a_{i} ai,然后分别乘上矩阵 W k , W v W_{k},W_{v} Wk,Wv,得到向量 k i , v i k_{i},v_{i} ki,vi。
然后的操作就是用Decoder产生的q,去对Encoder产生的k,v做attention操作,然后做一个weight sum得到最后的输出结构。然后将这个结果通过全连接层,再做一个残差连接与layer normalization。
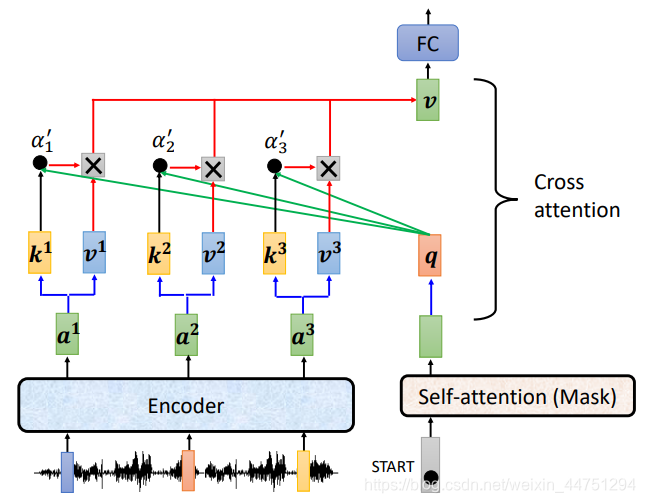
Cross attention部分产生的输出之后,会继续经过下一个Feed forward模块,再进行Add&Norm操作,然后最后Decoder这一轮输出的结果可能是输出一个 ‘机’ 字。随后,再丢到Decoder的block中先进行Multi-head self-attention,然后再进行刚刚介绍的Cross attention,重复这个过程,其中这个block会堆叠N次,执行完后才会再得到下一个输出。
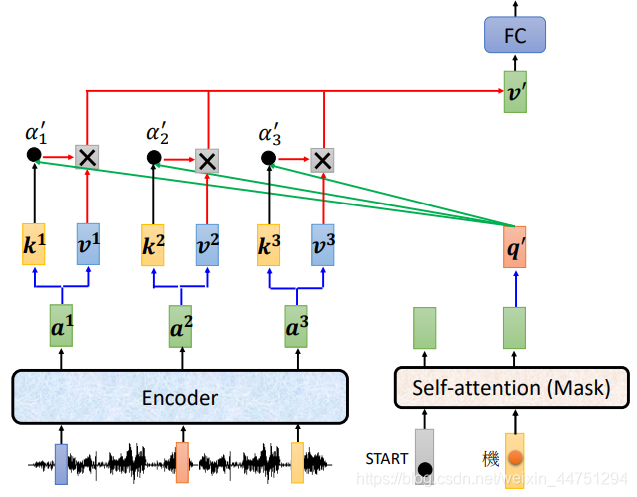
以上是原paper的Cross attention结构。其实可以理解到,Encoder与Decoder都有很多层,而在原始paper的操作中,在Decoder的block结构的Cross attention结构,它的输入都是来自与Encoder的最后一层,也就是如图所示的结构。
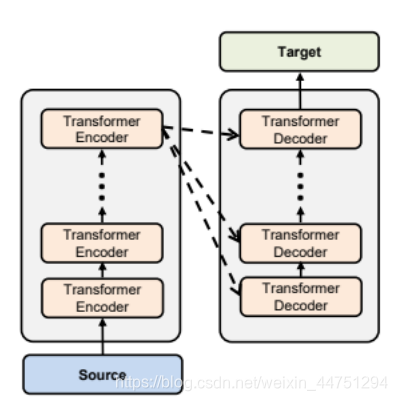
但是,这个结构是可以改变,其实有很多种不同的Cross attention的方式。所以以上就是Transformer的全部结构,如何输入一个sequence,输出一个sequence的全部流程。
五、Tips for Generation
其中这一部分是从我另外一篇blog中截取的一小节,完整内容可以查看:学习笔记——seq2seq模型介绍
以下是介绍训练阶段与测试阶段不匹配的两种处理方法。
当我们训练RNN的时候,后一个component的输入是前一个component的reference
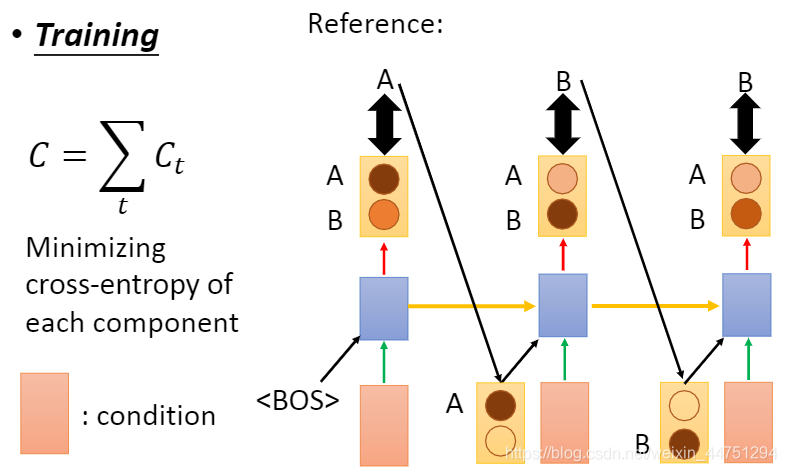
而当我们测试RNN的时候,这时候由于已经没有了reference,所以后一个后一个component的输入是前一个component的输出
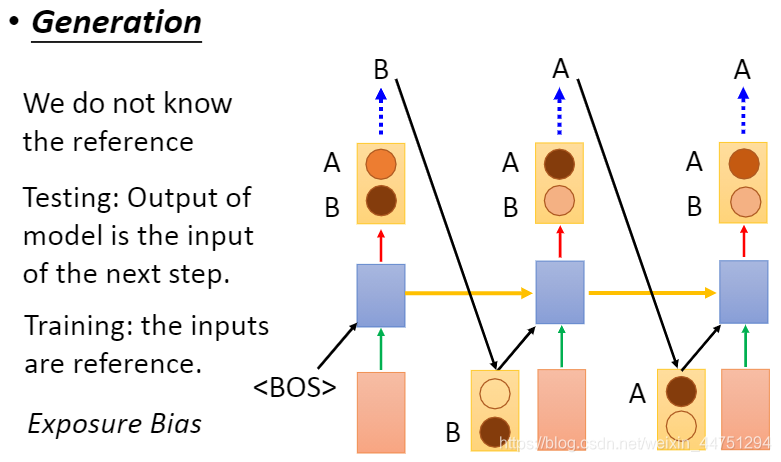
由上可知,由于训练过程与测试过程的输入点不一样,这样就会导致了不相匹配。有可能会出现一步错,步步错的情况。
所以,现在纠结的问题就是下一个时间点的input应该是从model的output中来还是从reference中来
1.Schedualed Sampling
随机挑选model的output中或者reference这两者之一。也就是随机的选择from model或者是from reference
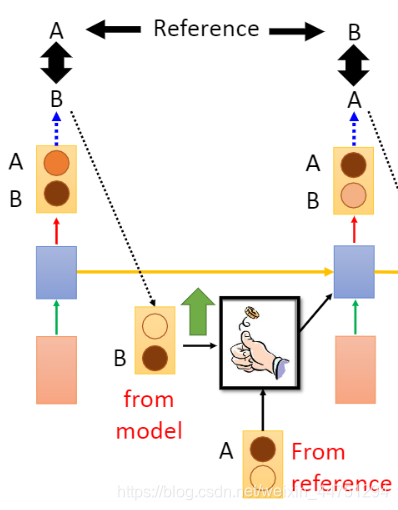
而结果显示,这种随机的选择去train,比任意挑选其中的一种去train确实要好。
一些解决方法的paper链接:
- Original ScheduledSampling:https://arxiv.org/abs/1506.03099
- Scheduled Sampling forTransformer:https://arxiv.org/abs/1906.07651
- Parallel ScheduledSampling:https://arxiv.org/abs/1906.04331
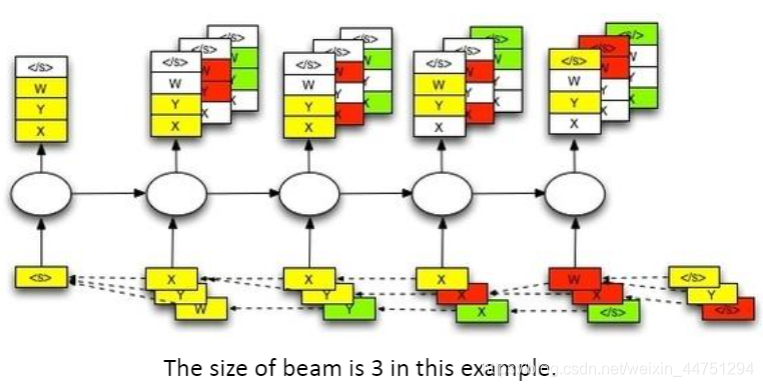
2.Beam Search
思想就是想要找到一组置信度最高得分的一组output来当作输入,如何去寻找这一组output就是Beam Search,其会keep分数最高的某几条path,保存这个分数最高的数量就是Beam Size。