Transformer是谷歌2017年发表的论文"Attention is all you need"中的人工智能模型,一经推出便霸占了AI舞台的中心,在某些方面的表现甚至超越了人类。Transformer各种魔改模型更是层出不穷,现有表现优异的人工智能模型无一不与他有关系,虽然该模型结构复杂,学起来比较吃力,但得益于互联网越来越好的开放环境,解读教程越来越通俗易懂,网上各位大神的解读也是一篇比一篇精彩,令人称奇,在阅读不少大神的博客和视频后,我终于对Transformer有了初步的了解,所以,输出这篇博客梳理总结下大脑里的相关知识,也希望大家浏览后觉得有问题的地方积极留言,帮助我改正。
参考:
- Transformer模型中重点结构详解
- 汉语自然语言处理-从零解读碾压循环神经网络的transformer模型(一)
- 如何理解Transformer论文中的positional encoding,和三角函数有什么关系?
目录
一、Transformer模型整体结构示意图
Transformer主要分为encoder和decoder两个部分,两者的连接关系体现在decoder的“Multi-Head Attention”层,该层是自注意力层,三个输入中K、V来自于encoder,Q来自于decoder。
一图胜千言
编码器(encoder)将输入的自然语言序列用数学表达出来(不光有每个字的信息,还有每个字之间的位置关联信息),以隐藏层的形式输入给解码器(decoder),解码器再将隐藏层的表达式输出为自然语言序列,这种结构广泛应用于情感分类、摘要提取、命名实体识别、语义关系提取、机器翻译等,用一个简单的例子来表示模型都做了哪些内容:
- 输入自然语言序列到编码器: Why do we work?(为什么要工作)
- 编码器输出到隐藏层,再输入到解码器
- 输入< start >(起始)符号到解码器
- 得到第一个字:为
- 将第4步的输出作为解码器的输入
- 得到第二个字“什”
- 将第6步的输出作为解码器的输入,直到解码器输出< end >(终止符),即序列生成完成
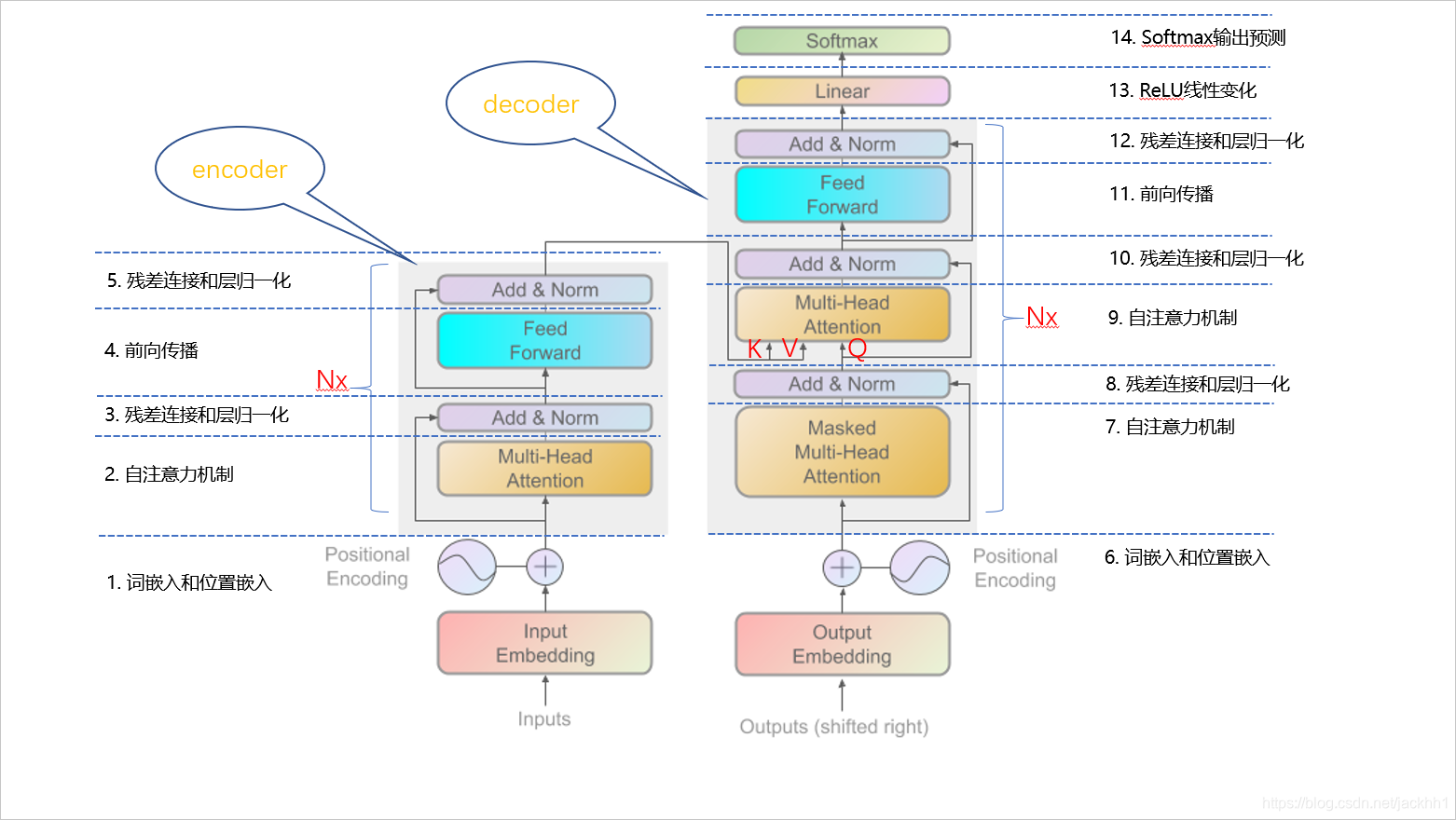
图 1.1 图1.1 图1.1
二、encoder
2.1 词嵌入和位置嵌入矩阵
输入X,形状为[batch_size, seq_len]
经过词嵌入和位置嵌入后得到:
X = X e m b e d d i n g + X P E X = X_{embedding} + X_{PE} X=Xembedding+XPE,形状为[batch_size, seq_len, embedding_size]
Transformer没有循环神经网络那样的迭代操作,它是通过位置嵌入的形式记录每个字的位置信息,这样模型才能识别出语言中的顺序关系。
位置嵌入postional encoding概念:
P E p o s , 2 i = s i n ( p o s 100 0 2 i d m o d e l ) (1) PE_{pos, 2i} = sin({
{pos}\over {1000^{2i\over d_{model}}}})\tag{1} PEpos,2i=sin(1000dmodel2ipos)(1)
P E p o s , 2 i + 1 = c o s ( p o s 100 0 2 i d m o d e l ) (2) PE_{pos, 2i+1} = cos({ {pos}\over {1000^{2i\over d_{model}}}})\tag{2} PEpos,2i+1=cos(1000dmodel2ipos)(2)
上述两个等式中,pos指句子中字的位置,取值范围为[0, max_sequence_length], i 指的是词向量的维度,取值范围是[0, embedding_dimension], d m o d e l = e m b e d d i n g d i m e n s i o n d_{model} = embedding_dimension dmodel=embeddingdimension。

这两个等式表示对于每个字,其奇数和偶数的词嵌入特征列的位置信息
这个公式对应embedding_dimension维度的一组奇数和偶数序号的维度,例如0,1一组,2,3一组,分别用上面的sin和cos函数做处理,从而产生不同的周期性变化,而位置嵌入在embedding_dimension维度上随着维度序号增大,周期变化会越来越慢,而产生一种包含位置信息的纹理,位置嵌入函数的周期从 2 π 到 10000 ∗ 2 π 2\pi到10000*2\pi 2π到10000∗2π变化
( T = 2 π w , w = 1 1000 0 2 i d m o d e l T = {2\pi\over w}, w={1\over{10000^{2i\over d_{model}}}} T=w2π,w=10000dmodel2i1)
通过下面的代码我们可以直观了解下位置函数的意义所在:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import math
def get_positional_encoding(max_seq_len, embed_dim):
# 初始化一个positional encoding
# embed_dim: 字嵌入的维度
# max_seq_len: 最大的序列长度
positional_encoding = np.array([
[pos / np.power(10000, 2 * i / embed_dim) for i in range(embed_dim)]
if pos != 0 else np.zeros(embed_dim) for pos in range(max_seq_len)]) #pos = 0,位置嵌入都是0,如下图中第一行显示条所示
positional_encoding[1:, 0::2] = np.sin(positional_encoding[1:, 0::2]) # dim 2i 偶数
positional_encoding[1:, 1::2] = np.cos(positional_encoding[1:, 1::2]) # dim 2i+1 奇数
return positional_encoding
positional_encoding = get_positional_encoding(max_seq_len=100, embed_dim=16)
plt.figure(figsize=(20,20))
sns.heatmap(positional_encoding)
plt.title("Sinusoidal Function")
plt.xlabel("hidden dimension")
plt.ylabel("sequence length")
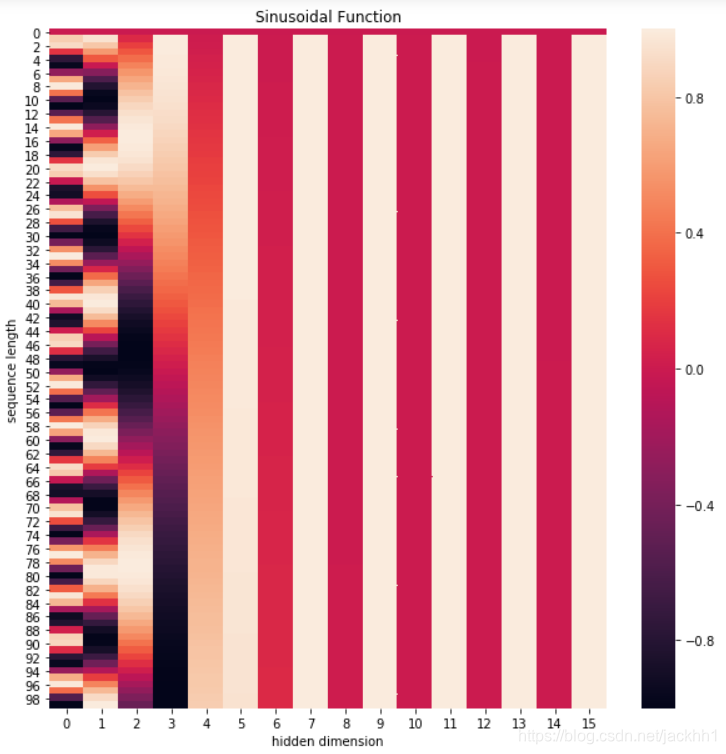
图 2 − 1 图2-1 图2−1
通过下面的代码我们可以看下词嵌入特征1/2/3中各个字之间的位置信息是如何变化的
plt.figure(figsize=(8, 5))
plt.plot(positional_encoding[1:, 1], label="dimension 1")
plt.plot(positional_encoding[1:, 2], label="dimension 2")
plt.plot(positional_encoding[1:, 3], label="dimension 3")
plt.legend()
plt.xlabel("Sequence length")
plt.ylabel("Period of Positional Encoding")
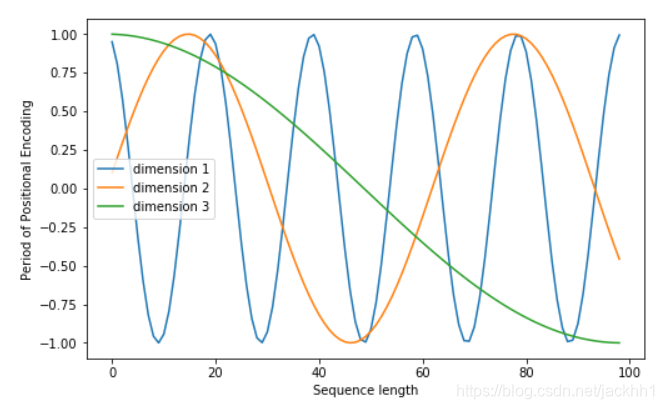
图 2 − 2 图2-2 图2−2
图2-1 和图2-2 可能还是不能很好地解释公式1/2为什么能记录下来各个字之间的位置信息,下面我们联想下正余弦函数的特性来思考:
根据三角函数的性质:
{ sin ( α + β ) = sin α cos β + cos α sin β cos ( α + β ) = cos α cos β − sin α sin β (3) \left\{ \begin{array}{c} \sin(\alpha+\beta) = \sin\alpha\cos\beta + \cos\alpha\sin\beta \\ \cos(\alpha+\beta) =\cos\alpha\cos\beta - \sin\alpha\sin\beta \end{array} \right. \tag{3} {
sin(α+β)=sinαcosβ+cosαsinβcos(α+β)=cosαcosβ−sinαsinβ(3)
我们可以得到
{ P E ( p o s + k , 2 i ) = P E ( p o s , 2 i ) x P E ( k , 2 i + 1 ) + P E ( p o s , 2 i + 1 ) x P E ( k , 2 i ) P E ( p o s + k , 2 i + 1 ) = P E ( p o s , 2 i + 1 ) x P E ( k , 2 i + 1 ) − P E ( p o s , 2 i ) x P E ( k , 2 i ) (4) \left\{ \begin{array}{c} PE(pos +k, 2i) = PE(pos, 2i)xPE(k,2i+1) + PE(pos, 2i+1)xPE(k,2i) \\ PE(pos+k, 2i+1) = PE(pos, 2i+1) x PE(k,2i+1) - PE(pos,2i)xPE(k,2i) \end{array} \right. \tag{4} {
PE(pos+k,2i)=PE(pos,2i)xPE(k,2i+1)+PE(pos,2i+1)xPE(k,2i)PE(pos+k,2i+1)=PE(pos,2i+1)xPE(k,2i+1)−PE(pos,2i)xPE(k,2i)(4)
方程组4中可以看出对于pos+k位置的位置向量某一维2i或2i+1而言,可以表示为,pos位置与k位置 的位置向量的2i与2i+1维的线性组合,这样就可以很明显看出pos位置和k位置的字存在关联,也表明等式(4)蕴含了字之间的相对位置信息。
参考:汉语自然语言处理-从零解读碾压循环神经网络的transformer模型(一)
如何理解Transformer论文中的positional encoding,和三角函数有什么关系?
2.2 自注意力机制
下图是B站大神视频讲解里材料,因为这部分大神将的已经非常通俗易懂了,所以我就直接贴在这儿了,相信大家看了他的解释一定可以明白自注意力机制的数学表达。

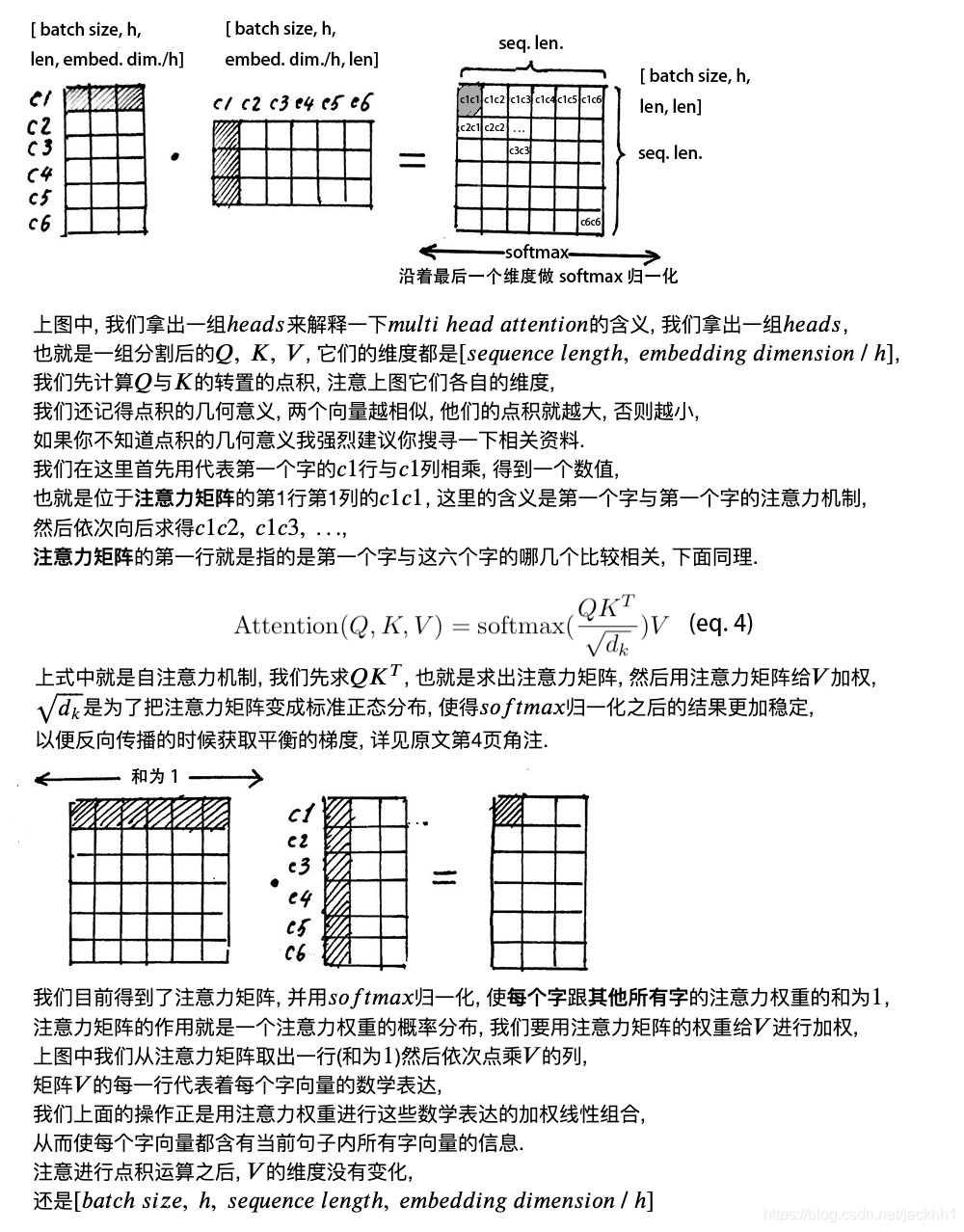
在计算自注意力矩阵的时候,我们一次计算的其实是多个句子,每个句子的长度不一样(mini-batch训练模式),针对这种情况,模型都是按照最长的句子长度(当然也会有个超参数max_seqence_length)为标准,将所有的句子打补丁成一样长,这样计算得到 Q K T QK^{T} QKT中许多地方为0,而下一步是softmax操作,这些为0的区域经过softmax后就变的有值了,这样对于后面的计算其实危害很大,因为本来没有值,不需要计算的地方,经过这一轮计算后,又变得需要进行运算了,因此Transformer在这里还引入了一个操作:Attention Mask
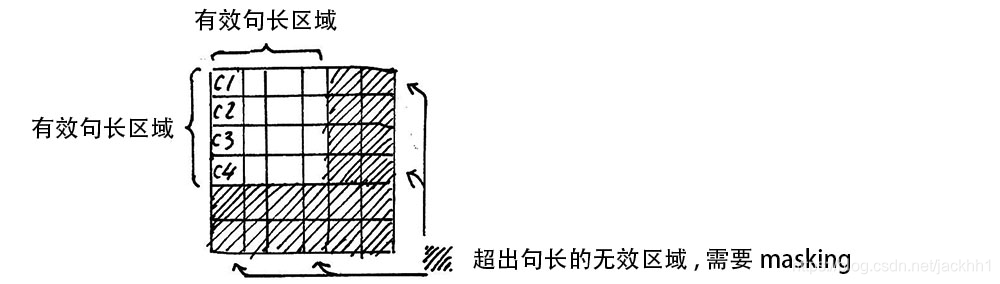
我们给这些无效的区域加一个很大的负数偏置 B i a s i l l e g a l Bias_{illegal} Biasillegal,那样经过softmax变换后,该区域还是0,具体如下:
z i l l e g a l = z i l l e g a l + B i a s i l l e g a l B i a s i l l e g a l → ∞ e z i l l e g a l → 0 z_{illegal} = z_{illegal} + Bias_{illegal} \\ Bias_{illegal} \rightarrow\infty \\ e^{z_{illegal}}\rightarrow 0 zillegal=zillegal+BiasillegalBiasillegal→∞ezillegal→0
这样无效区域就不会再参与计算。
2.3 残差连接和层归一化
得到自注意力矩阵Attention(Q, K, V),形状为 [ b a t c h s i z e , h , s e q l e n g t h , e m b e d d i n g s i z e / h ] [batch_size, h, seq_length, embedding_size/h] [batchsize,h,seqlength,embeddingsize/h],在进行残差连接前我们需要将自注意力矩阵形状转置成和 X e m b e d d i n g X_{embedding} Xembedding一样,即 [ b a t c h s i z e , s e q l e n g t h , e m b e d d i n g s i z e ] [batch_size, seq_length, embedding_size] [batchsize,seqlength,embeddingsize]
残差连接:
X = X e m b e d d i n g + X a t t e n t i o n X = X_{embedding} + X_{attention} X=Xembedding+Xattention
完成残差连接之后,接着就是层归一化,层归一化的作用吴恩达老师的视频都有提到,忘记的可以点这里复习下https://blog.csdn.net/jackhh1/article/details/103909958
层归一化公式:
μ i = 1 m ∑ i = 1 m x i j \mu_{i}=\frac{1}{m} \sum^{m}_{i=1}x_{ij} μi=m1i=1∑mxij
σ j 2 = 1 m ∑ i = 1 m ( x i j − μ j ) 2 \sigma^{2}_{j}=\frac{1}{m} \sum^{m}_{i=1}(x_{ij}-\mu_{j})^{2} σj2=m1i=1∑m(xij−μj)2
L a y e r N o r m ( x ) = α ⨀ x i j − μ i σ i 2 + ϵ + β LayerNorm(x) = \alpha\bigodot\frac{x_{ij}-\mu_i}{\sqrt{\sigma_i^{2}+\epsilon}}+\beta LayerNorm(x)=α⨀σi2+ϵxij−μi+β
α \alpha α一般全初始化为1, β \beta β一般全初始化为0,他们是用来弥补归一化过程中损失掉的信息。
经层归一化后:
X a t t e n t i o n = L a y e r N o r m ( X a t t e n t i o n ) X_{attention} = LayerNorm(X_{attention}) Xattention=LayerNorm(Xattention)
2.4 FeedForward层
这层的操作时两次线性变换并用激活函数激活得到:
X h i d d e n = A c t i v a t e ( L i n e a r ( L i n e a r ( X a t t e n t i o n ) ) X_{hidden} = Activate(Linear(Linear(X_{attention})) Xhidden=Activate(Linear(Linear(Xattention))
2.5 残差连接和层归一化
这一步就跟第三步一样,重复第三步的公式就可以了:
X h i d d e n = X a t t e n t i o n + X h i d d e n X h i d d e n = L a y e r N o r m ( X h i d d e n X h i d d e n ∈ R b a t c h s i z e ∗ s e q . l e n . ∗ e m b e d . d i m . X_{hidden} = X_{attention} + X_{hidden}\\ X_{hidden} = LayerNorm(X_{hidden}\\ X_{hidden} \in \mathbb{R}^{batch \ size \ * \ seq. \ len. \ * \ embed. \ dim.} Xhidden=Xattention+XhiddenXhidden=LayerNorm(XhiddenXhidden∈Rbatch size ∗ seq. len. ∗ embed. dim.
三、解码器(decoder)
3.1 decoder input
解码器的输入也同编码器输入一样,进行词嵌入和位置嵌入,以< start >开始符开始进行解码,得到的输出又重新作为编码器的输入,与之前时刻的编码器输入进行位置嵌入,然后进行下一步
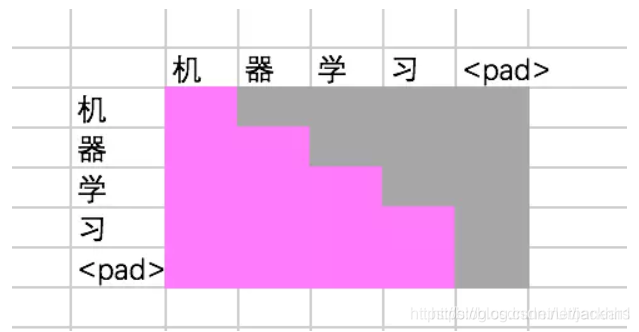
3.2 Masked Multi-Head Attention
这层也是注意力层,但为什么叫Masked Multi-Head Attention?因为解码器跟传统的seq2seq模型中的解码器一样,不是并行的,它还是按照上一时刻的输出来进行下一时刻的预测,因此在进行这层操作的时候,得到的必然是一个下三角矩阵,即已知时刻有对应的值,位置时刻没有值,相当于被掩盖了。总之,这里的masked decoder self attention, 就是为了防止当前生成的单词对未来的单词产生依赖性。
3.3 残差连接和层归一化
解码器的残差连接和层归一化和编码器的残差连接和层归一化一样,直接参考2.3的内容
3.4 Multi-Head Attention
解码器与编码器在这一层产生连接,其中K,V矩阵由编码器Encoder输出提供,Q由编码器Masked Multi-Head Attention提供,具体公式跟2.2中的一样。
3.5 残差连接和层归一化
解码器的残差连接和层归一化和编码器的残差连接和层归一化一样,直接参考2.3的内容
3.6 Feed Forward
解码器的Feed Forward层跟编码器的Feed Forward层一样,直接参考2.4部分内容
3.7 残差连接和层归一化
解码器的残差连接和层归一化和编码器的残差连接和层归一化一样,直接参考2.3的内容
3.8 Linear & Softmax
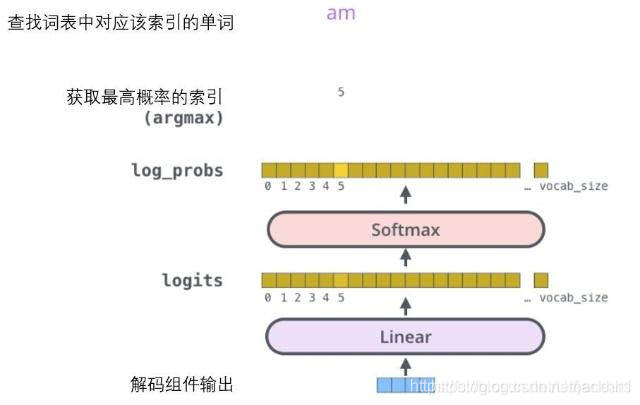
解码器的最后两层是一个线性变换和softmax层,跟之前的语言模型类似,Linear层是一个全连接层,可以把解码器输出的向量投射到一个比它大得多的被称作对数几率(logits)的向量里,就是词汇表里每个元素都有一个对数几率(logits),然后再经过softamax变换转换成概率(取值范围0-1),概率最高的值对应的单词(操作np.argmax)会作为这个时间步的输出,并做为下一个时间步的解码器输入,直到预测的单词时< end >停止符。
四、Transformer整体运行流程
一图胜千言…
