准备知识
-
余弦相似度
假设有 x 和 w 两个单位向量,那么它们间的余弦相似度计算方法如图


计算公式
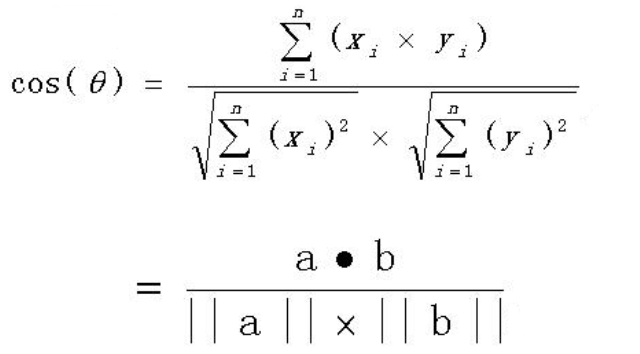
python代码
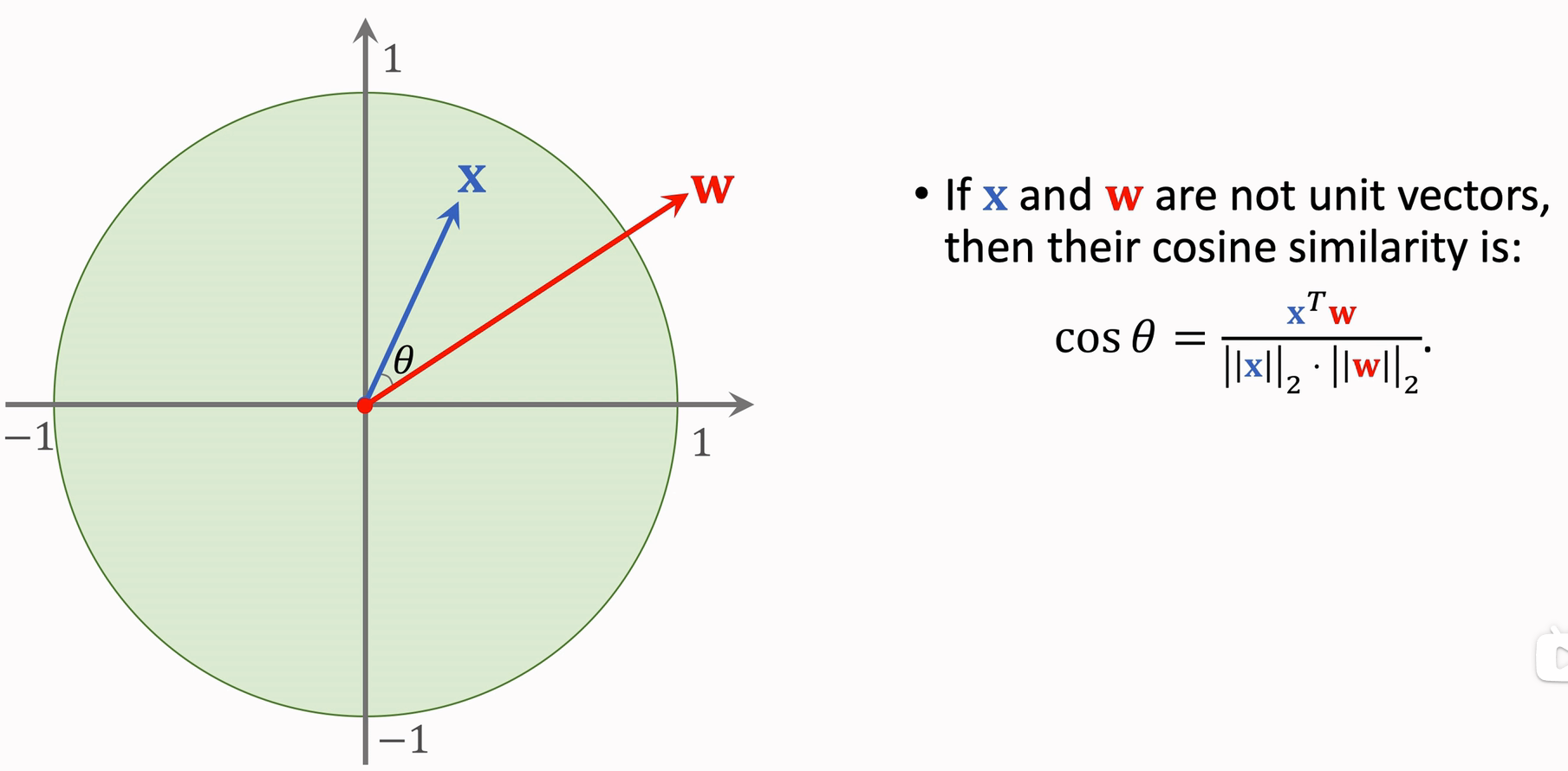
import numpy as np vec1= np.array([1,2,3,4,5]) vec2 = np.array([3,4,5,6,7]) vec3 = np.array([1,2,3,4,5]) # np.linalg.norm() 是 np 内置的函数用来求算范数,向量的 norm 范数就是向量的模长 simi12 = np.sum(vec1 * vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2)) simi13 = np.sum(vec1 * vec3) / (np.linalg.norm(vec1) * np.linalg.norm(vec3)) print(simi12,simi13)如果 x 和 w 不是单位长度向量,那么需要归一化后求余弦相似度
Pretraining
-
用孪生网络或者监督学习预训练一个CNN分类器,如果使用传统的监督学习,那么训练完成后,将全连接层去掉
-
训练好的网络用在 Support Set 上面
假设我们现在是 3-way 2-shot Support Set ,训练好的网络使用方法如下
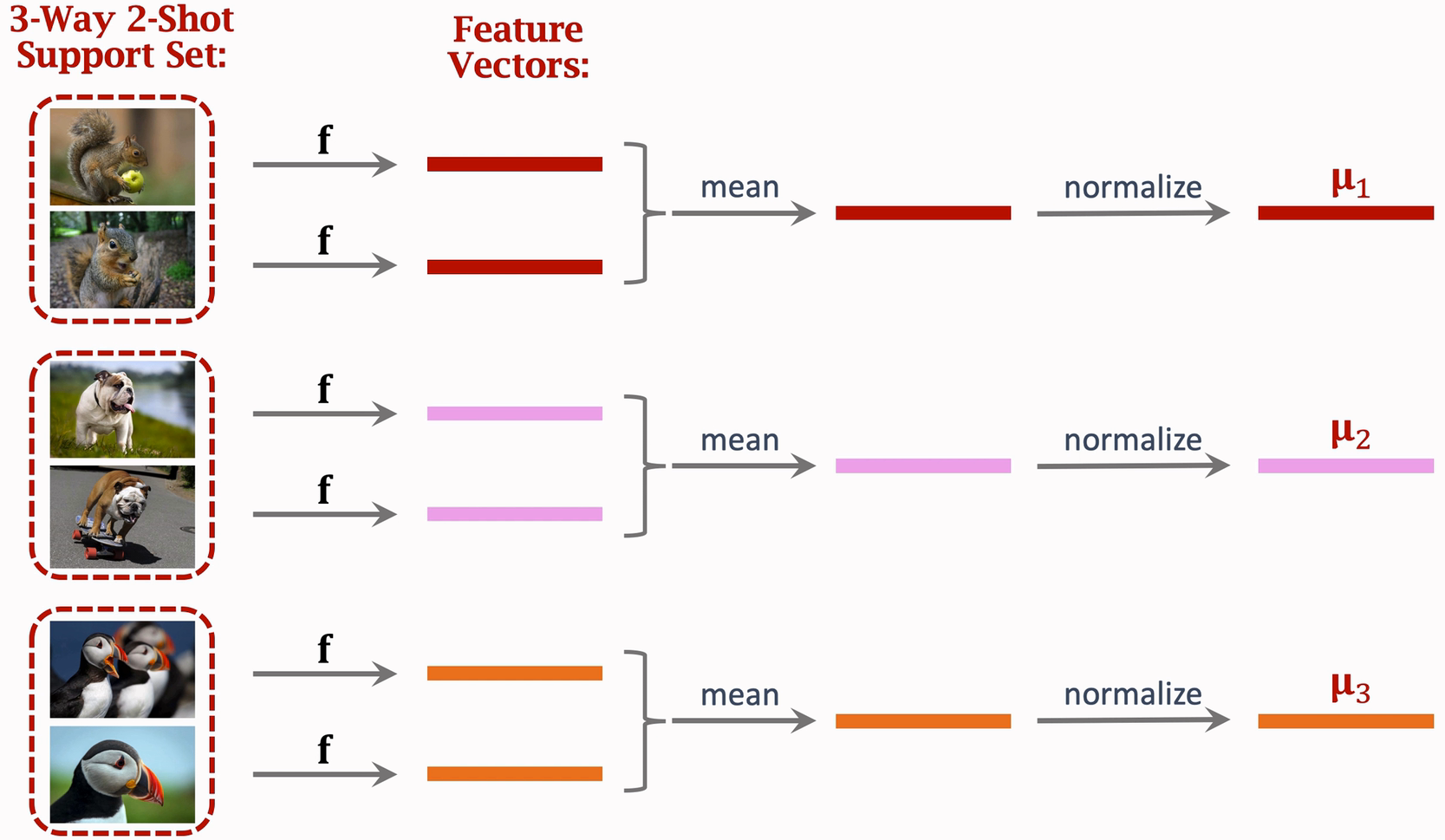
mean 表示对两个向量求平均,normalize 表示对向量归一化
# 对向量归一化 import torch import torch.nn.functional as F a = torch.arange(9, dtype= torch.float) a = a.reshape((3,3)) print(a) ''' tensor([[0., 1., 2.], [3., 4., 5.], [6., 7., 8.]]) ''' # 对二维数组按行归一化 # p=2表示二范式, dim=1表示按行归一化 b = F.normalize(a, p=2, dim=1) print(b) ''' tensor([[0.0000, 0.4472, 0.8944], [0.4243, 0.5657, 0.7071], [0.4915, 0.5735, 0.6554]]) '''由此得到三个 μ 向量:μ1,μ2,μ3
-
将训练好的网络用在Query上面进行预测
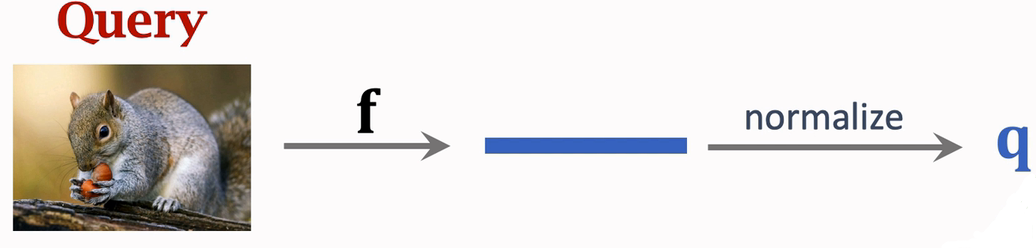
得到q向量
然后求出q向量 与 μ1,μ2,μ3 的余弦相似度

另一种方法(论文中常用,本节重点)
将 μ1,μ2,μ3 堆叠起来,成为一个矩阵 M

然后将矩阵M与q.T向量乘起来 得到p ,p就是一个概率值,p是一个3*1的矩阵,哪行值越大,那么q就归属于哪个类别

Fine Tuning
-
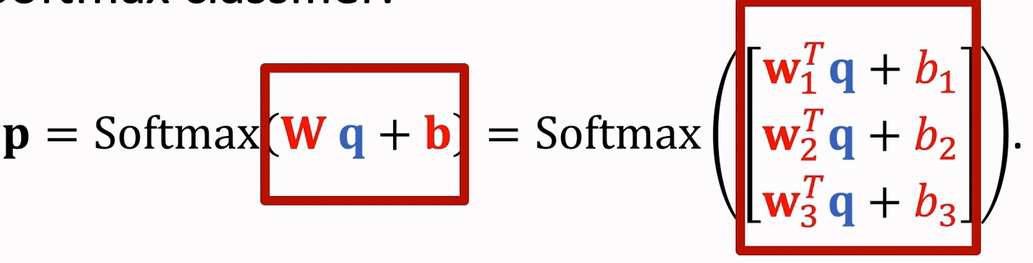
不使用Fine Tuning时,P = Softmax( M*q )

但是 P的原型是
P = Softmax( W*f(x) + b ), 这里W=M ,b=0,f(x) = q如果我们不固定W=M ,b=0,而是在 Support Set上学习这两个参数,那么称之为 Fine Tuning
这样做可以提升准确率
-
使用Fine Tuning,这里是使用 Support Set中的样本和标签来学习
i 表示属于哪个类别
( xi, yi ) 是Support Set 中的图像样本与标签
f(xi) 是CNN 输出的Query 的特征向量
pi = Softmax(W*f(xi) + b)是输出Query属于哪一个类别的概率损失函数:
loss = ∑i CrossEntropy( pi, yi),把每个样本的CrossEntropyLoss 都加起来作为目标函数,然后最小化这个 loss 函数,可将这些梯度传播到CNN网络中,让神经网络提取参数更有效。因为Support Set比较小,模型可能会发生过拟合,所以需要加上一个参数
Regularization,得到loss = ∑i CrossEntropy( pi, yi) + Regularization-
训练 Fine Tuning 的技巧
-
初始化参数 W 和 b
我们不要随机初始化 W 和 b 参数,而是初始就让 W = M,b = 0

-
Regularization怎么求(上一点说到的参数 Regularization 的选择)(下述算法是其中一种比较有效的)

注意:
- 此处的 f(x) 的输入是 Query中的图片,可能只有一个,也可能有多个
- Entropy的计算公式 是将所有Query中的图片算出的 -p*logp 相加
- Entropy regularization 是将Entropy 求平均得到的结果
Entropy regularization 的原理
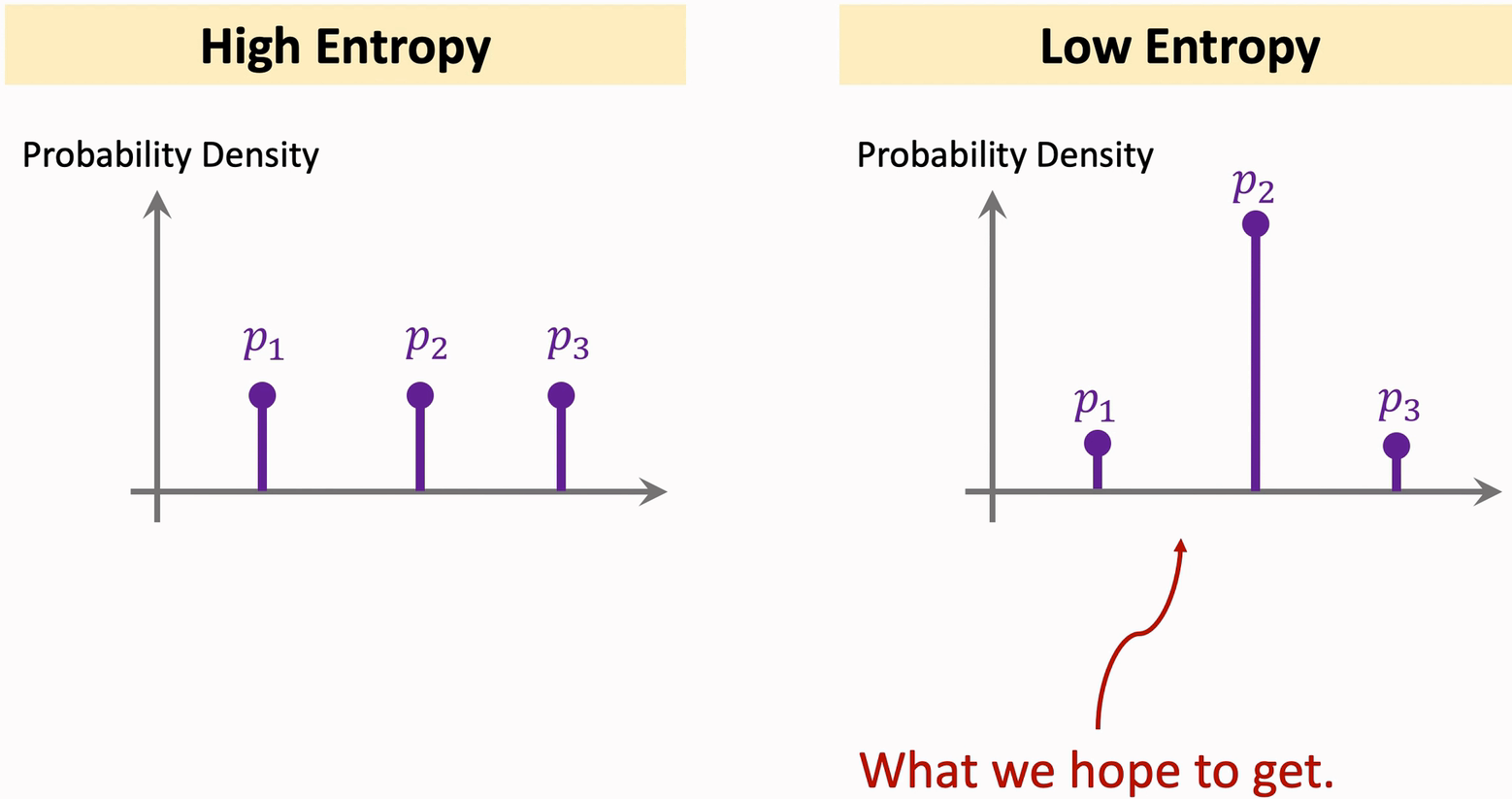
左图是难分类的样本,对应的Entropy值很高;
右图是易分类的样本,对应的Entropy值很低;
我们希望分类器得到右图的 低Entropy 的结果,所以把Entropy regularization 加进 Loss 函数中,使 得其在训练过程中变小
-
将余弦相似度和Softmax分类器结合起来 (显著提升准确率)

-
-
回顾
