知识蒸馏
知识蒸馏是一种模型压缩方法,在训练过程中,我们需要使用复杂的模型,但是在部署中,我们尽量使用简单高效的模型,在保证性能的前提下减少模型的参数量。
知识蒸馏的过程分为2个阶段:
- 原始模型训练: 训练"Teacher模型", 简称为Net-T,它的特点是模型相对复杂,也可以由多个分别训练的模型集成而成。我们对"Teacher模型"不作任何关于模型架构、参数量、是否集成方面的限制,唯一的要求就是,对于输入X, 其都能输出Y,其中Y经过softmax的映射,输出值对应相应类别的概率值。
- 精简模型训练: 训练"Student模型", 简称为Net-S,它是参数量较小、模型结构相对简单的单模型。同样的,对于输入X,其都能输出Y,Y经过softmax映射后同样能输出对应相应类别的概率值。
在本论文中,作者将问题限定在分类问题下,或者其他本质上属于分类问题的问题,该类问题的共同点是模型最后会有一个softmax层,其输出值对应了相应类别的概率值。
softmax层
柔性最大值传输函数,softmax往往加在神经网络的输出层,用于加工神经网络的输出结果:把微弱程度不同的信号整理成概率值,这便是机器学习模型对分类任务的置信度confidence。
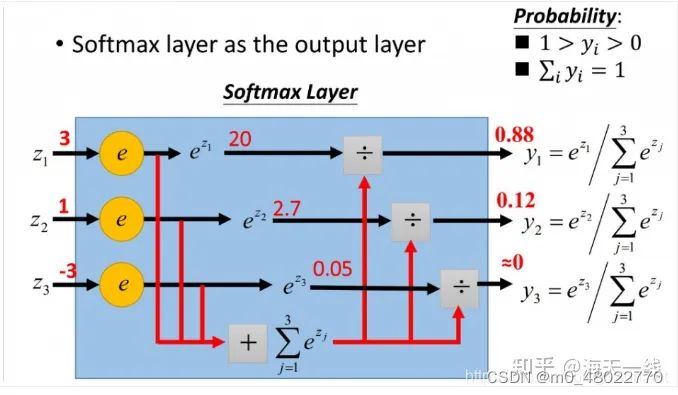
比如有一个神经网络对制作的是否为热狗进行判断,x代表是否满足某条件,1代表满足,0代表不满足,w代表这个条件对最后判断结果的权重。现在根据三个条件进行判断,分别是番茄酱(权重为3),芥末酱(权重为2),圆面包(权重为6),判断的神经元阈值为4(也就是说权重和大于4就是热狗,在深度学习中用b代表神经元阈值的相反数)。可以写成z=wx+b,当z大于0时代表判断为真,否则为假。上述情况是神经元网络对某事物真假的判断,而softmax函数一般用于事物的分类,一般用于多个神经元。上图中,假设三个神经元分别代表猫、狗、猴子,它们的输出z分别为3,1,-1,这说明结果为猫的可能性更大。如果是硬性的类别标签的话,这里会直接判断为猫。而老师模型通过软目标(soft targets)的方式来指导学生模型的训练。软目标是指老师模型在进行预测时输出的概率分布,而不是硬性的类别标签。这种概率分布包含了更多关于数据分布的信息,有助于提高模型的泛化能力。通过将老师模型的软目标作为学生模型的监督信号,可以帮助学生模型更好地学习到数据的分布特征,从而提高泛化能力。所以在这里判断结果为88%的概率是猫,12%的概率为狗,0%的概率为猴子。这就是softmax的意义,也是softmax和soft targets的联系。
softmax有2个无法抗拒的优势:1. softmax作为输出层,结果可以直接反映概率值,并且避免了负数和分母为0的尴尬;在上图中可以看到,softmax把z值换成e的幂,保证了恒为正数。2. softmax求导的计算开销非常小,毕竟是对e进行求导。
计算softmax函数的偏导数的意义在于在深度学习中进行反向传播算法时,用于更新模型参数(例如神经网络的权重和偏置)的梯度下降过程中。在训练深度学习模型时,我们需要通过梯度下降算法来最小化损失函数,以便使模型能够更好地拟合训练数据,并具有更好的泛化能力。
具体来说,对于softmax函数的偏导数(即梯度),它可以告诉我们在当前模型参数下,如果改变某个参数,损失函数会如何变化。这对于反向传播算法来说非常重要,因为它允许我们根据损失函数的梯度来更新模型参数,以便逐步优化模型的性能。
在深度学习中,反向传播算法通过链式法则来计算损失函数对模型参数的偏导数,然后使用梯度下降算法来更新模型参数。softmax函数的偏导数是其中一个重要的计算步骤,它能够告诉我们如何调整模型参数,以使损失函数最小化。
如果回归机器学习最最基础的理论,我们可以很清楚地意识到一点(而这一点往往在我们深入研究机器学习之后被忽略): 机器学习最根本的目的在于训练出在某个问题上泛化能力强的模型。泛化能力强是指机器学习模型不论是训练数据还是测试数据还是其他任何数据都能很好地反应输入和输出之间的关系,如果仅在训练数据上表现好称为过拟合。
在知识蒸馏时,由于我们已经有了一个泛化能力较强的Net-T,我们在利用Net-T来蒸馏训练Net-S时,可以直接让Net-S去学习Net-T的泛化能力。一个很直白且高效的迁移泛化能力的方法就是:使用softmax层输出的类别的概率来作为“soft target”。target应该是标签,soft target是包含了负标签的。这里的意思就是,softmax会直接给出分类的概率,老师模型的概率输出是多少,那给学生模型的概率输出也蒸馏为多少。softmax的结果不是硬性的类别标签,而是概率明显的,对于数据特征能更全面的描述,是具有很好的泛化能力的。再加上老师模型的结构和参数完全可以给学生模型提供经验,能更好的提高泛化能力。
使用softmax层输出的类别的概率作为"soft target"是一个直白且高效的迁移泛化能力的方法,原因如下:
-
信息丰富:Softmax层输出的类别概率包含了丰富的信息,可以反映出模型对于每个类别的置信度。这些概率值不仅告诉了我们模型的预测结果,还表达了模型对于预测的确定性程度。因此,这些概率值能够更全面地描述数据的分布特征,有助于学生模型更好地学习到数据的特性。
-
迁移泛化能力:通过使用softmax层输出的类别概率作为soft target,学生模型可以在训练过程中直接受益于老师模型的泛化能力。老师模型通过softmax输出的概率分布传递了对于数据分布的理解和泛化能力,这种信息有助于指导学生模型更好地泛化到新的、未见过的数据。老师模型不仅提供了软目标,还可以通过知识蒸馏的方式将自己所学到的知识传递给学生模型。知识蒸馏可以包括将老师模型的隐藏层表示、特征映射、权重参数等信息传递给学生模型,从而帮助学生模型学习到老师模型的泛化能力。除了软目标和知识蒸馏,老师模型还可以指导学生模型的模型结构设计和超参数选择,以便学生模型更好地适应数据的分布特征。老师模型的结构和超参数通常经过精心设计和调优,因此可以为学生模型提供宝贵的指导信息。
-
直观易懂:Softmax输出的类别概率是直观且易于理解的,因为它们可以直接对应到不同类别上的置信度。这种直观性使得soft target更容易被学生模型理解和利用,有助于提高学生模型的性能。
【KD的训练过程和传统的训练过程的对比】
- 传统training过程(hard targets): 对ground truth求极大似然
- KD的training过程(soft targets): 用large model的class probabilities作为soft targets

KD的训练过程为什么更有效?
标签、负标签、ground truth、熵、logits
标签通常是由人工标注的,也就是由人工给定的,以便训练模型进行监督学习。在训练过程中,模型将根据输入数据和标签之间的关系进行学习,以便能够对新的未见过的数据进行准确的分类或回归预测。在监督学习任务中,我们通常会使用带有标签的数据来训练模型,这些标签就是"ground truth"。"负标签"就是指代负类别的标签,也就是指代不属于我们感兴趣的类别的标签。
熵可以理解为概率分布的不确定性度量。当概率分布更加均匀或者更加平稳时,熵的值会更大,表示概率分布的不确定性更高。
在深度学习中,logits(对数几率)通常指代模型输出层的未经过激活函数处理的原始输出。softmax 函数可以将logits 转换为每个类别的概率。
softmax层的输出,除了正例之外,负标签也带有大量的信息,比如某些负标签对应的概率远远大于其他负标签。而在传统的训练过程(hard target)中,所有负标签都被统一对待。也就是说,KD的训练方式使得每个样本给Net-S带来的信息量大于传统的训练方式。比如在手写体数字识别任务MNIST中,输出类别有10个。假设某个输入的“2”更加形似"3",softmax的输出值中"3"对应的概率为0.1,而其他负标签对应的值都很小,而另一个"2"更加形似"7","7"对应的概率为0.1。这两个"2"对应的hard target的值是相同的,但是它们的soft target却是不同的,由此我们可见soft target蕴含着比hard target多的信息。并且soft target分布的熵相对高时,其soft target蕴含的知识就更丰富。这就解释了为什么通过蒸馏的方法训练出的Net-S相比使用完全相同的模型结构和训练数据只使用hard target的训练方法得到的模型,拥有更好的泛化能力。
先回顾一下原始的softmax函数:
但要是直接使用softmax层的输出值作为soft target, 这又会带来一个问题: 当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。因此**“温度”**这个变量就派上了用场。
下面的公式时加了温度这个变量之后的softmax函数:
- 这里的T就是温度。
- 原来的softmax函数是T = 1的特例。 T越高,softmax的output probability distribution越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
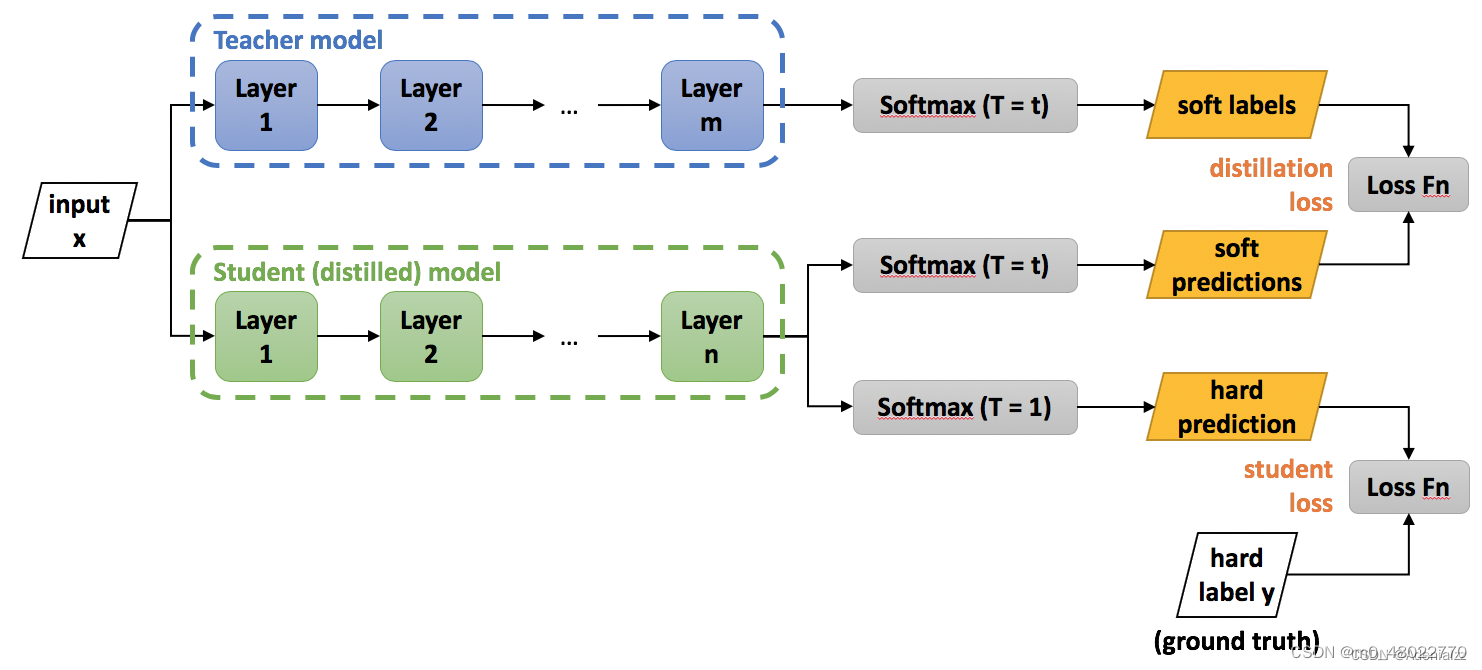
通用的知识蒸馏方法:第一步是训练Net-T;第二步是在高温T下,蒸馏Net-T的知识到Net-S
训练Net-T的过程很简单,下面详细讲讲第二步:高温蒸馏的过程。高温蒸馏过程的目标函数由distill loss(对应soft target)和student loss(对应hard target)加权得到。示意图如上。


我们都知道“蒸馏”需要在高温下进行,那么这个“蒸馏”的温度代表了什么,又是如何选取合适的温度?如下图所示,随着温度T的增大,概率分布的熵逐渐增大。

因此温度的选取比较empirical,本质上就是在下面两件事之中取舍:
- 从有部分信息量的负标签中学习 --> 温度要高一些
- 防止受负标签中噪声的影响 -->温度要低一些
总的来说,T的选择和Net-S的大小有关,Net-S参数量比较小的时候,相对比较低的温度就可以了(因为参数量小的模型不能capture all knowledge,所以可以适当忽略掉一些负标签的信息)
参考:
这是本人学习知识蒸馏时参考的博主@Adenialzz的文章,算是自己写的学习笔记,仅供自己学习之用。贴下原文地址:【经典简读】知识蒸馏(Knowledge Distillation) 经典之作-CSDN博客