上一篇博文中我们介绍了知识蒸馏的一些基础知识,这里我们来学习其到底是如何完成知识蒸馏过程的。
知识蒸馏为何可以让学生网络模型小却性能强?
详细很多同学与我有相同的疑问,尽管它依靠不同的蒸馏温度T可以学得一些hard target标注无法包含的知识,但这个过程还是太过抽象。
蒸馏温度T
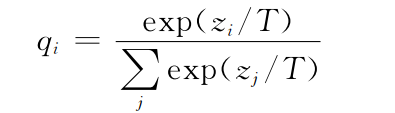
Hard Target与Soft Target
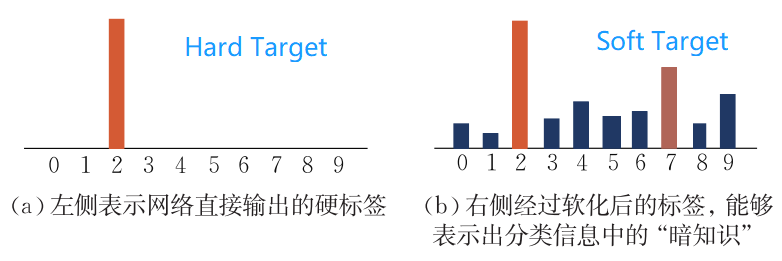
大量的实验性研究表明,所谓的“暗知识”其实是软化的标签对网络的学习产生的正则化效用。
正则化的作用是为了防止过拟合,主要方法有两种,一种是在损失函数中加入惩罚项,来防止模型收敛到最小点(在训练集上收敛到最小点,在测试集上效果不一定好,这就是过拟合)
另一种方法就是Dropout。
因而,通过标签平滑正则化(Label Smoothing Regularization,LSR)可以在一定程度上模拟出知识蒸馏的效果。
知识蒸馏过程
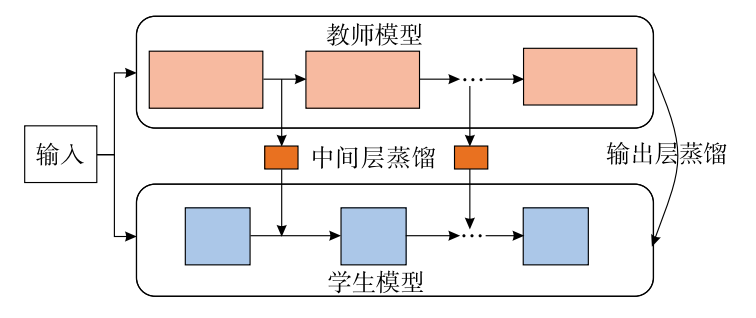
下图为知识蒸馏模型的整体结构.其由一个多层的教师模型和学生模型组成,教师模型主要负
责向学生模型传递知识,这里的“知识”包括了标签知识、中间层知识、参数知识、结构化知识、图表示知识.在知识的迁移过程中,通过在线或离线等不同的学习方式将“知识”从教师网络转移到了学生网络。
由下图可知,知识蒸馏并不仅仅像我们前一篇文章中所描述的那种仅仅是通过输出层的结果进行约束来实现知识转移过程,其中间层也会进行蒸馏操作。
我的直观理解
关于知识蒸馏我们可以这样理解:教师网络是一个大模型,它包含很多层,具有很多参数,因此其能够对大量数据进行学习,总而得到答案(答案即输出层结果),而为何学生网络即使模型体积很小也能够拥有与教师网络相媲美的性能呢,这就是知识蒸馏的意义了:教师网络不但告诉学生网络答案(即将教师网络的输出结果来与学生网络输出结果求损失,随着损失不断变小,学生网络学得也就越好),而仅仅是学得答案是不够的,教师-学生网络的设定是让学生还能学习到教师网络的解题过程,以卷积网络为例,其每层卷积后都会生成特征图,这也是知识,那么教师网络在与学生网络进行特征对齐后进行对比计算损失,也就可以让学生网络学得解题过程。
知识蒸馏整体分类框架
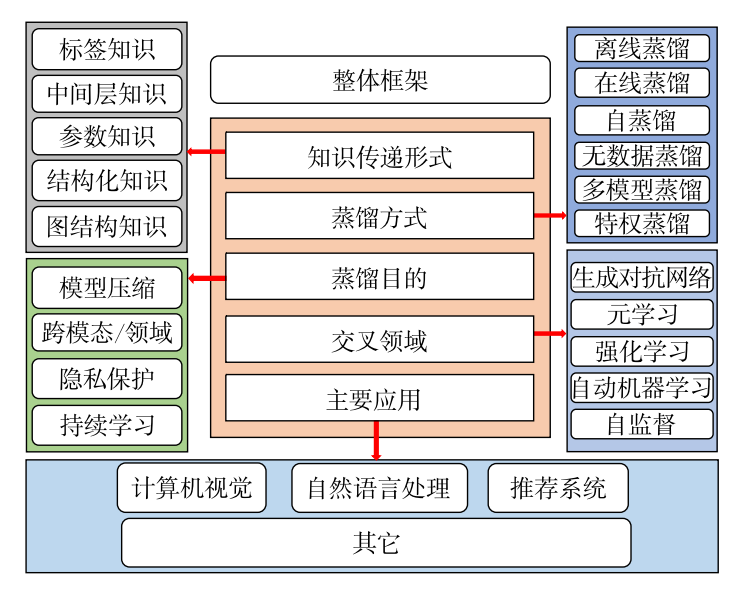
知识蒸馏方法的核心在于“知识”的设计、提取和迁移方式的选择,通常不同类型的知识来源于网络模型不同组件或位置的输出.根据知识在教师-学生模型之间传递的形式可以将其归类为标签知识、中间层知识、参数知识、结构化知识和图表示知识。
标签知识一般指在模型最后输出的logits概率分布中的软化目标信息;中间层知识一般是在网络中间层输出的特征图中表达的高层次信息;参数知识是训练好的教师模型中存储的参数信息;结构化知识通常是考虑多个样本之间或单个样本上下文的相互关系;图表示知识一般是将特征向量映射至图结构来表示其中的关系,以满足非结构化数据表示的学习需要。
不同知识传递形式下的蒸馏方法形式化表示对比表
