知识蒸馏(定位蒸馏与分类蒸馏)
一、 什么是知识蒸馏
知识蒸馏指的是模型压缩的思想,通过使用一个较大的已经训练好的网络去教导一个较小的网络确切地去做什么。
蒸馏的核心思想在于好模型的目标不是拟合训练数据,而是学习如何泛化到新的数据。所以蒸馏的目标是让学生模型学习到教师模型的泛化能力,理论上得到的结果会比单纯拟合训练数据的学生模型要好。
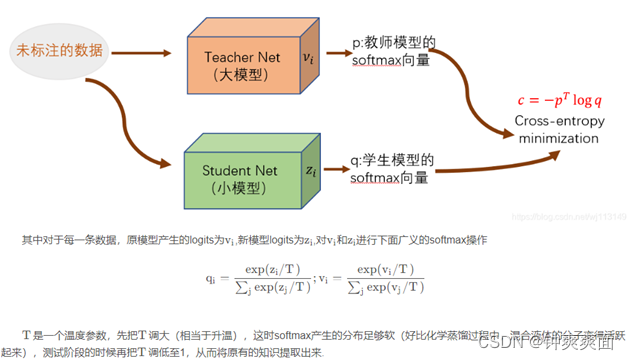
在蒸馏的过程中,我们将原始大模型称为教师模型(teacher),新的小模型称为学生模型(student),训练集中的标签称为hard label,教师模型预测的概率输出为soft label,temperature(T)是用来调整soft label的超参数。
二、 为什么要知识蒸馏
训练和部署使用的模型存在着一定的不一致性:
在训练过程中,我们需要使用复杂的模型,大量的计算资源,以便从非常大、高度冗余的数据集中提取出信息。在实验中,效果最好的模型往往规模很大,甚至由多个模型集成得到。而大模型不方便部署到服务中去,常见的瓶颈如下:
• 推断速度慢
• 对部署资源要求高(内存,显存等)
• 在部署时,我们对延迟以及计算资源都有着严格的限制。
因此,模型压缩(在保证性能的前提下减少模型的参数量)成为了一个重要的问题。而”模型蒸馏“属于模型压缩的一种方法。
三、 知识蒸馏的理论依据
Teacher—Student模型:teacher是“知识”的输出者,student是“知识”的接受者。
知识蒸馏的过程分为2个阶段:
• 原始模型训练:
训练“Teacher模型”Net-T,它的特点是模型相对复杂,“Teacher模型”不作任何关于模型架构、参数量、是否集成方面的限制,唯一的要求就是,也就是ROC/mAP/mIoU指
标,无明显bias
• 精简模型训练:
训练“Student模型”Net-S,它是参数量较小、模型结构相对简单的单模型。同样的,
比如分类模型,经过softmax后同样能输出对应类别的概率值。
四、 知识蒸馏的关键点
(1) 通过增加网络容量,获得泛化能力强的模型:
在某问题的所有数据上都能很好地反应输入和输出之间的关系,无论是训练数据,还是测试数据,还是任何属于该问题的未知数据。
(2) 我们在利用Net-T来蒸馏训练Net-S时,可以直接让Net-S去学习Net-T的泛化能力。
(3) 直白且高效的迁移泛化能力的方法就是:
使用softmax层输出的类别的概率来作为“soft target”
【KD的训练过程和传统的训练过程的对比】:
传统training过程(hard targets): 对ground truth求极大似然,交叉熵和极大似然的关系
KD的training过程(soft targets): 用large model的class probabilities作为soft targets
(4) 极大似然函数

(5) KL散度
用于衡量两个分部P、Q的距离

(6) 交叉熵与熵

(7) 交叉熵损失函数

五、 KD训练过程为什么更有效
softmax层的输出,除了正例之外,负标签也带有大量的信息,比如某些负标签对应的概率远远大于其他负标签(宝马,兔子和垃圾车)。
在传统的训练过程(hard target)中,所有负标签都被one-hot编码后变成0,从而将负标签所携带的信息丢弃。最终Net-T只将正样本的信息进行蒸馏训练负样本。

(传统的训练过程,one-hot后只保留正样本的信息)
而KD的训练方式不使用one-hot编码,使得每个样本信息都保留,从而给 Net-S带来的信息量大于传统的训练方式

(KD的训练过程,保留所有负样本的信息)
例子:
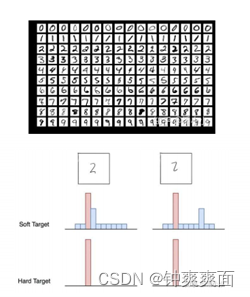
在手写体数字识别任务MNIST中,输出类别有10个。假设某个输入的“2”更加形似"3",softmax的输出值中"3"对应的概率为0.1,而其他负标签对应的值都很小,而另一个"2"更加形似"7","7"对应的概率为0.1。这两个"2"对应的hard target的值是相同的,但是它们的soft target却是不同的,由此我们可见soft target蕴含着比hard target多的信息。并且soft target分布的熵相对高时,其soft target蕴含的知识就更丰富
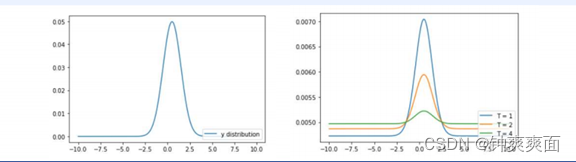
六、 带“温度”的softmax
先回顾一下原始的softmax函数 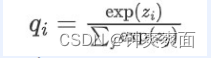
但要是直接使用softmax层的输出值作为soft target, 这又会带来一个问题: 当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。因此"温度"这个变量就派上了用场。
下面的公式时加了温度这个变量之后的softmax函数:
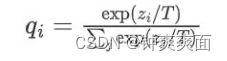
这里的T就是温度。
原来的softmax函数是T = 1的特例。 T越高,softmax的output probability distribution越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
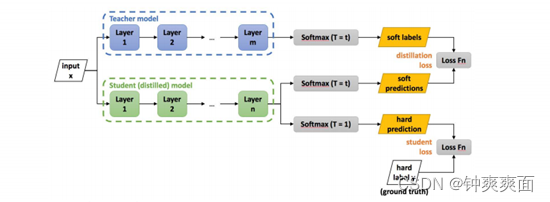
七、 知识蒸馏的具体方法(分类网络)
1、 通用的知识蒸馏方法:
(1) 训练好教师网络Net-T;
(2) 在高温T下,蒸馏Net-T的知识到Net-S
训练Net-T的过程很简单,下面详细讲讲第二步:高温蒸馏的过程。高温蒸馏过程的目标
函数由distill loss(对应soft target)和student loss(对应hard target)加权得到。示意图如。
2、 高温蒸馏过程
(1) 损失函数:
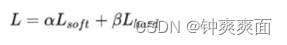
a) 损失函数的第一部分
Net-T 和 Net-S同时输入 transfer set (这里可以直接复用训练Net-T用到
的training set), 用Net-T产生的softmax distribution (with high
temperature) 来作为soft target,Net-S在相同温度T条件下的softmax输
出和soft target的cross entropy就是Loss函数的第一部分 
b) 损失函数第二部分
Net-S在T=1的条件下的softmax输出和ground truth的cross entropy就是Loss函数的第二部分 
c) 为什么要第二部分的loss
Net-T也有一定的错误率,使用ground truth可以有效降低错误被传播给Net-S的可能。打个比方,老师虽然学识远远超过学生,但是他仍然有出错的可能,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,就可以有效地降低被老师偶尔的错误“带偏”的可能性
d) Loss拆分解析
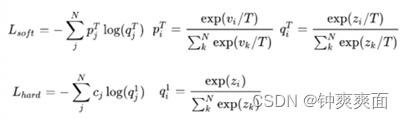


(2) Loss函数求导:


八、 定位蒸馏 (LD)
1、 为什么会有定位蒸馏:
bbox分布与定位模糊性
说起 LD,就不得不说起 bbox 分布建模,它主要来源于 GFocalV1(NeurIPS 2020)[1] 与 Offset-bin(CVPR 2020)[2] 这两篇论文。
我们知道 bbox 的表示通常是 4 个数值,一种如 FCOS 中的点到上下左右四条边的距离(tblr),还有一种是 anchor-based 检测器中所用的偏移量,即 anchor box 到 GT box 的映射(encoded xywh)。
GFocalV1 针对 tblr 形式的 bbox 建模出了 bbox 分布,Offset-bin 则是针对 encoded xywh 形式建模出了 bbox 分布,它们共同之处就在于尝试将 bbox 回归看成一个分类问题。并且这带来的好处是可以建模出 bbox 的定位模糊性。

那么用 n 个概率值去描述一条边,可以显示出模型对一个位置的定位模糊估计,越尖锐的分布说明这个位置几乎没有模糊性(比如大象的上边界),越平坦的分布说明这个位置有很强的模糊性(大象的下边界)。当然不光是 bbox 分布的平坦度,形状上还可分为单峰型,双峰型,甚至多峰型。
2、 定位蒸馏:
LD 的 idea 已经不言自明,bbox 的一条边是 n 个 logits ,一个 bbox 就有 4 个 ,每个 作用上一个带有温度 的 softmax 函数,把定位知识软化一下,随后一样的 KL loss,让 student 的 bbox 分布去拟合 teacher 的 bbox 分布。
为验证 LD 的有效性,我们先在检测器的 positive location 上进行,也就是哪里进行了 bbox regression,哪里就进行 LD。大模型 teacher 是一个已经训练了 24 epochs 的高精度检测器(比如 ResNet-101),小模型 student 可以是 ResNet-50。在 COCO 数据集上,我们只需要稍微调一调温度 就可以在 GFocalV1 的基础上提高 1.0AP,特别是 AP75 的提升最为显著,说明 LD 确实显著改善了定位精度。
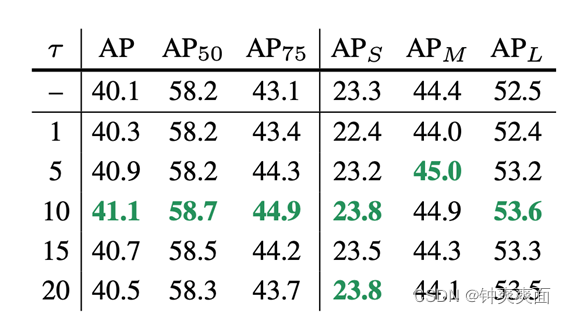
定位蒸馏 LD 与分类蒸馏 KD 从公式上来看是完全一致的,都是针对 head 的输出 logits 做知识传递,这为目标检测知识蒸馏提供了一个统一的 logit mimicking 框架。
九、 特征图蒸馏
1、 为什么会与特征图蒸馏:
分类KD的低效性:
以往许多工作指出了分类 KD 的蒸馏效率低下(涨点低),这主要有两个方面:
在不同的数据集中,类别数量会变化,较少的类别可能给 student 提供不了很多有用的信息。
一直以来 logit mimicking 都只能在分类 head 上操作,而无法在定位 head 上操作,这自然忽视了定位知识传递的重要性。
基于这两个原因,人们将视线转向了另一个很有前景的知识蒸馏方法,Feature imitation。该方法主要受到 FitNet 的启发,一言以概之,就是不光分类 head 上要做 logit mimicking,中间隐藏层(特征图)也要让 student 去拟合 teacher,通过最小化 L2 loss 来完成。
于是形成了如下的目标检测知识蒸馏框架:
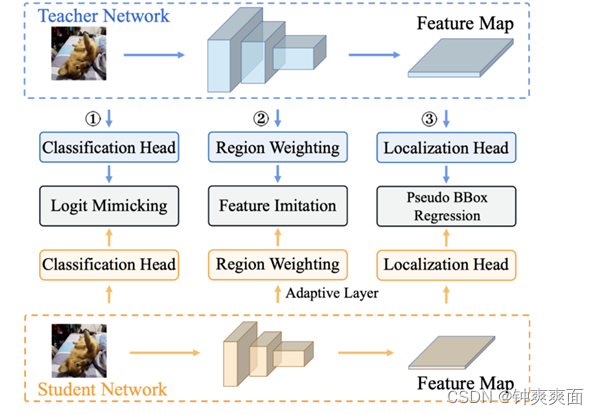
其中分类 head 上是 logit mimicking(分类 KD),特征图上是 Feature imitation (teacher 与 student 特征图之间的 L2 loss),定位 head 上是伪 bbox regression,即把 teacher 预测框当成额外的回归目标。
Feature imitation 在师生的特征图上施加监督,最常见的做法是先将 student 的特征图尺寸与 teacher 特征图对齐,之后再选择一些感兴趣的区域作为蒸馏区域,例如 FitNet(ICLR 2015)[3] 在全图上蒸馏;Fine-Grained(CVPR 2019)[4] 在一些 anchor box 的 location 上蒸馏;还有 DeFeat(CVPR 2021)[5] 在 GT box 内部用小 loss weight,在 GT box 外部用大 loss weight;亦或者是 GI imitation(CVPR 2021)[6] 的动态蒸馏区域,但无论选择何种区域,最后都是在蒸馏区域上计算二者的 L2 loss.
2、 Feature imitation的好处:
在 multi-task learning 框架下,特征图相当于树根,下游的各个 head 相当于树的叶子。那么特征图显然包含了所有叶子所需要的知识。进行 Feature imitation 自然就会同时传递分类知识与定位知识,而分类 KD 却无法传递定位知识。
3、 Feature imitation的弊端:
答案自然还是它会在蒸馏区域中的每个 location 上同时传递分类知识与定位知识。
前后一对比,乍看之下岂不矛盾?让我来解释一下。
分类知识与定位知识的分布是不同的。这一点在以往的工作中有提到,例如 Sibling Head(CVPR 2020)[7]。
两种知识的分布不同,自然就导致了并不是在一个 location 上同时传递分类知识与定位知识都有利。很有可能某些区域仅对分类知识传递有利,也有可能某些区域仅对定位知识传递有利。换言之,我们需要分而治之、因地制宜地传递知识。这显然就是 Feature imitation 无能为力的事情了,因为它只会传递混合知识。
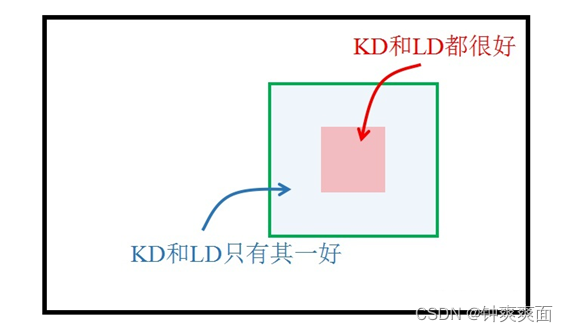
于是我们利用 multi-task learning 天然地把知识解耦成不同类型,这就允许我们在一个区域中有选择性地进行知识蒸馏。为此,我们引入了一个有价值定位区域 VLR (Valuable Localization Region)的概念,来帮助我们进行分而治之的蒸馏。
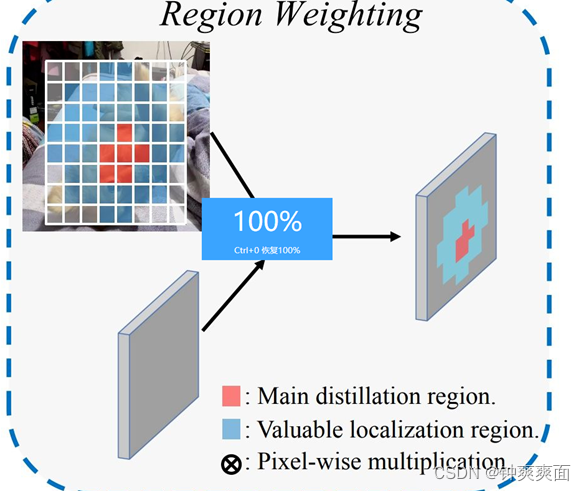
与以往的 Feature imitation 方法不同,我们的蒸馏分为两个区域:
Main distillation region (主蒸馏区域):即检测器的 positive location,通过 label assignment 获得。
VLR:与一般的 label assignment 做法类似,但区域更大,包含了 Main region,但去掉了 Main region。VLR 可以视为是 Main region 的向外扩张。