最近在学习降噪处理不良天气的算法过程中,接触到了知识蒸馏,该算法作为一个深度学习通用算法,不仅广泛应用在自然语言处理方面,在计算机视觉等领域也广受追捧。
概要
简单来说,知识蒸馏就是将一个大的教师网络萃取到一个小的学生网络中,即完成一个知识迁移的过程,这个教师网络可能是很多网络的集合,是一个很臃肿的模型,为了方便将其部署在一些算力受限的平台设备上,如手机,自动驾驶平台,便将教师网络浓缩变为学生网络。
预备知识
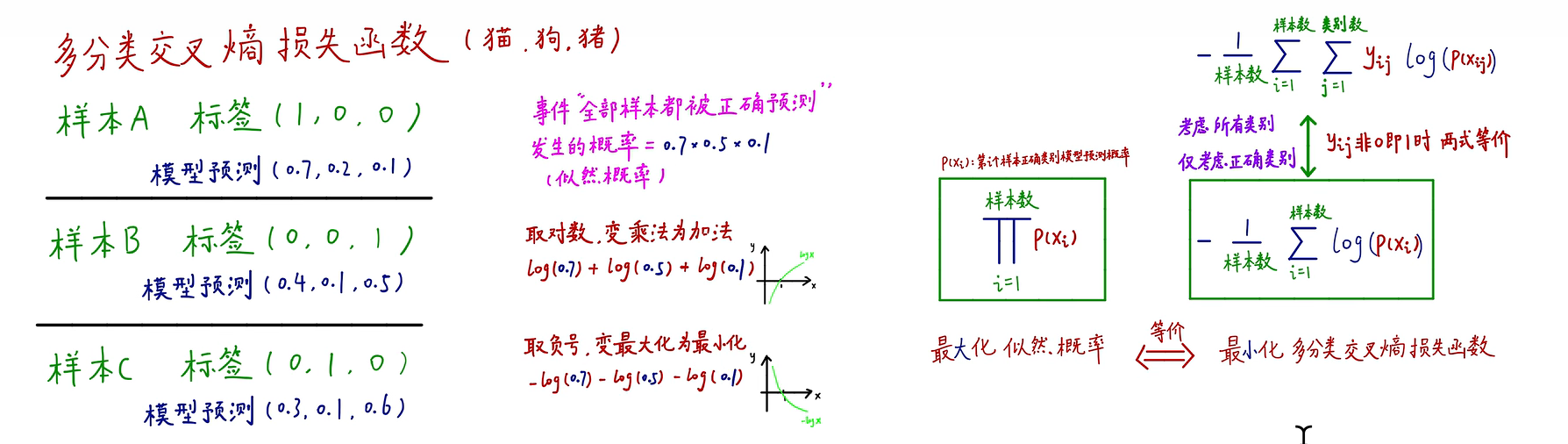
我们以一个分类模型来介绍知识蒸馏过程,在分类模型中使用交叉熵损失作为损失函数,下面介绍一下交叉熵损失函数的推导过程。
交叉熵损失函数推导过程
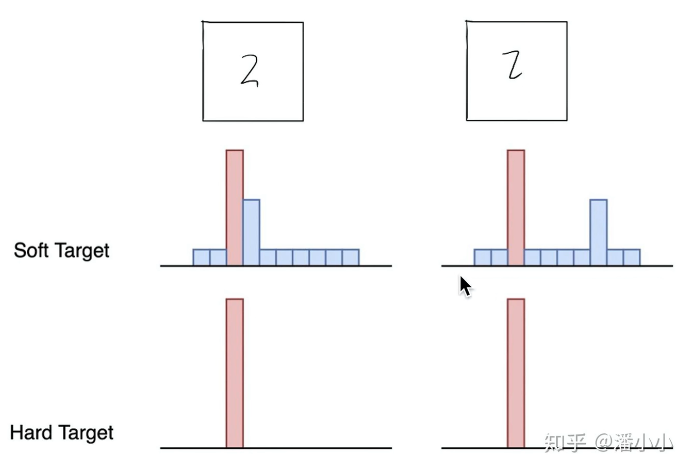
hard target与soft target
了解完交叉熵损失函数后,在这里我们需要引入一个概念,分别是hard target与soft target,以分类模型为例:
每个样本都有确定的类别,即其值要么为0,要么为1,这样的标签则为hard target(红框表示),而soft target则是以概率的形式表示,这也是我们分类网络的输出结果(绿框表示)这种表示方式也是我们一般标注文件的形式,但这种方式在从模型学习的过程来看是不科学的。

例如以下面的三分类来看,hard target明确告诉我们图片中某个目标是马,他不是车也不是驴。

而soft target则给出了目标是三者的概率,如马0.7 ,驴0.2,车0.1,这种方式不仅给出了其正确类别,还给出了非正确类别间的相对差别,即驴与马还是有些相似的,而车却很不像,相较于hard target,这种方式包含了更多的信息。
如下图手写数字识别分类:sotf target包含很多信息,更像谁,更不像谁,所以soft target相较于hard target是更科学的。我们可以使用teacher 网络训练出的sotf target送入到学生网络中作为标签进行学习。
总结一句话:
soft target相较于hard target,包含更多的知识和信息,更像谁,更不像谁,有多像,有多不像,特别是其能出给非正确类别概率的相对大小
扫描二维码关注公众号,回复: 15437399 查看本文章
为了让类别的间的相对误差更加明显,引入了蒸馏温度的概念。
蒸馏温度
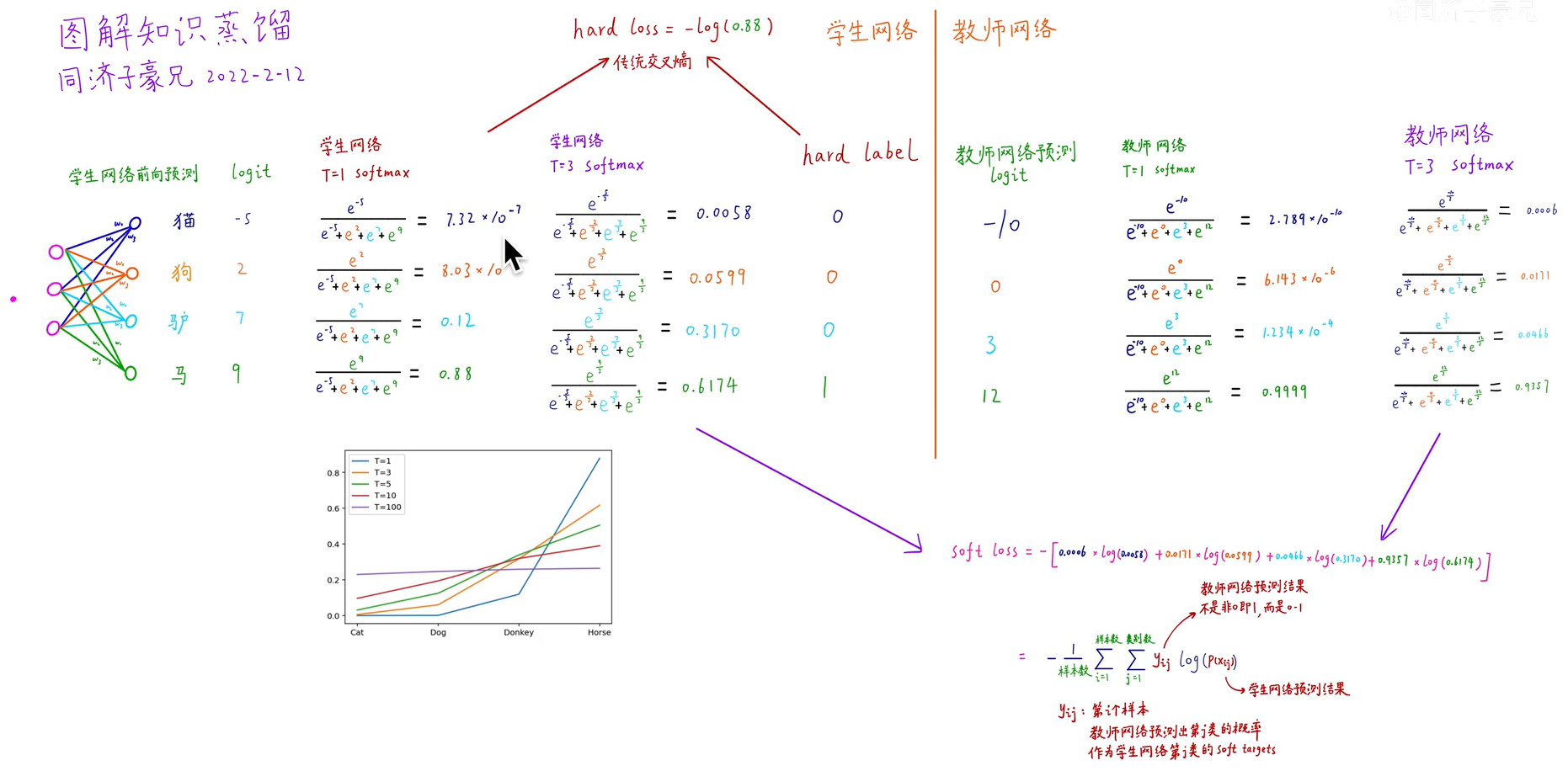
如何理解蒸馏温度呢?其实很简单,就是在softmax函数的计算中加入了调制温度系数T用于放大差别,定义如下:但T不能太大,贫富差距就变小了
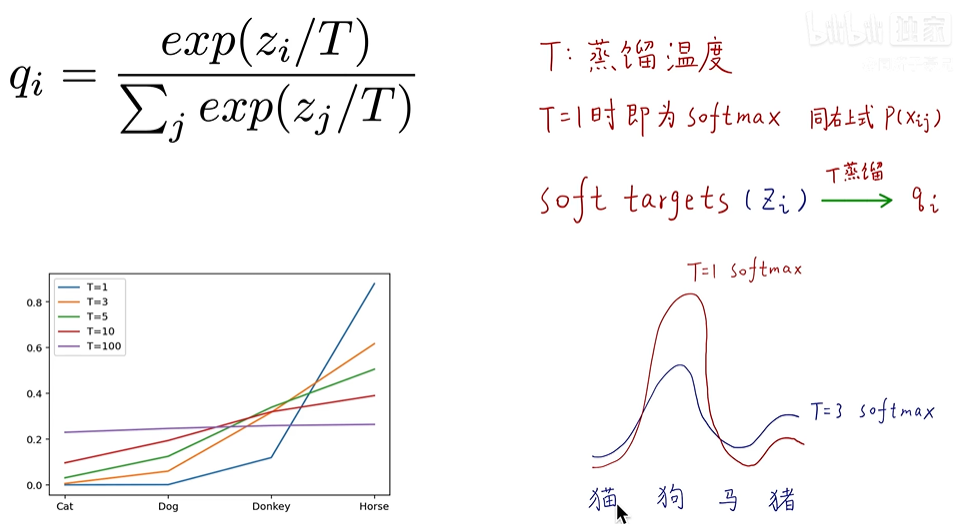
具体计算如下,分别计算原始的softmax与T=3时的损失。
知识蒸馏模型架构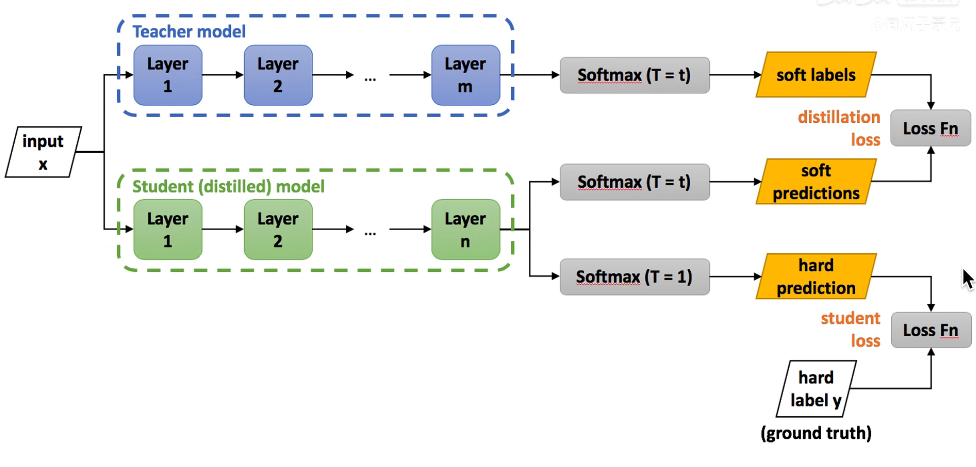
具体过程:
将大量数据送入已经训练好的教师网络,求出T=t时的soft labels(soft target),再将数据送入一个没有训练过,或是半成品的学生网络去计算T=t时的soft prediction,然后与soft labels求损失,同时学生网络中还要求T=1时的预测结果,称为hard prediction,其与hard target求损失,最后两个损失进行加权求和即得到最终的损失。
关于学习的内容:
可以是最后的输出结果(soft target),也可以是中间的特征层,也可以是注意力图谱。
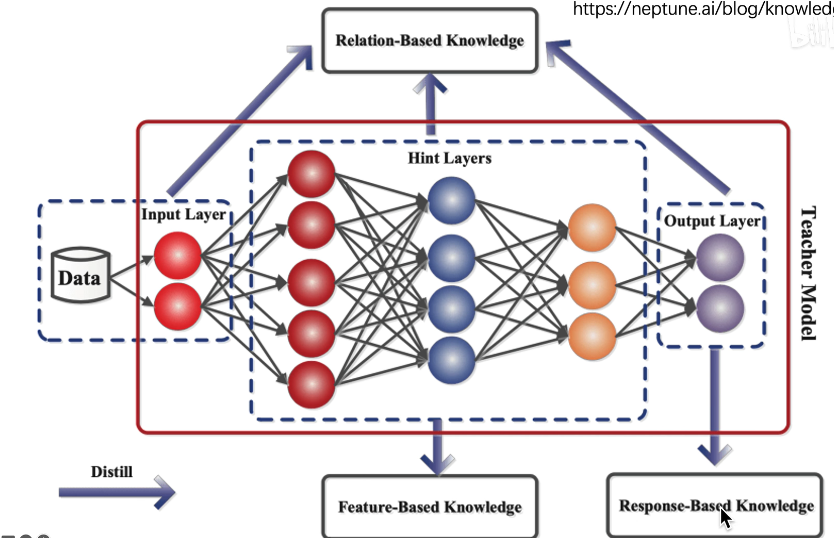
知识蒸馏为何有用?
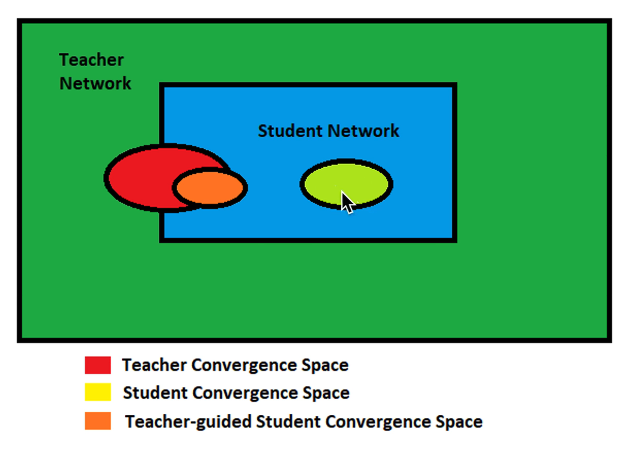
椭圆为收敛域空间,可以看到通过教师网络收敛的域空间与学生网络自己收敛的域空间也是很相近的。