决策树
优点:计算复杂度不高,输出结果易于理解,对中间值得缺失不敏感,可以处理不相关特征数据。
缺点:可能会产生过度匹配问题
适用数据类型:数值型和标称型
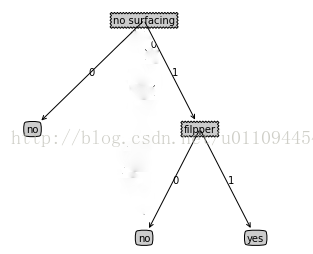
如图为决策树的一个形式,最后有“no”、“yes”两个分类结果。“no surfacing”与“filpper”为两个判断划分。
在使用决策树之前,必须在海量的无序数据中找出最优的划分方法,这时就要计算信息增益。
集合信息的度量方式成为香农熵,熵定义为信息的期望值,计算公式有:
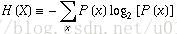
其中
P(x)为选择该分类的概率。
python3.6实现香农熵的计算代码
def calcShannonEnt(dataSet):
num = len(dataSet)
labelCounts = {}
for featVec in dataSet: #计算每个分类出现的次数,并记录
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1
shannonEnt = 0.0
for value in labelCounts: #计算选择该分类的概率,并累加熵
prob = float(labelCounts[value])/num
shannonEnt -= prob*log(prob,2)
return shannonEnt #返回最终的信息期望
def chooseBestFeatureToSplit(dataSet):
#获得除分类结果以外的特征值的数量
numFeatures = len(dataSet[0])-1
#计算数据集dataSet的香农熵
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0;bestFeature = 1
for i in range(numFeatures):
#得到dataSet中索引i所在的那一列
featList = [example[i] for example in dataSet]
#将这一列的数据用集合表示
uniqueVels = set(featList)
newEntropy = 0.0
#将包含集合中特征值的子数据集从数据集中分离,计算该特征值出现的概率prob
#并计算该特征的香农熵
for value in uniqueVels:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob*calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
#取最大的香农熵
if infoGain>bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
#返回最好的熵所在的index
return bestFeature利用上面选出的最好的划分判断的特征值,我们便可以开始创建决策树
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
#如果列中只有一个分类则返回这个分类
if classList.count(classList[0]) == len(classList):
return classList[0]
#如果已经将所有的特征值全部使用完了,则返回这列中出现频率最高的分类
if len(dataSet[0])==1:
return majorityCnt(classList)
#得到最优划分
bestFeat = chooseBestFeatureToSplit(dataSet)
#得到这个最优划分所在的特征标签值
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
#将这个标签删除
del(labels[bestFeat])
#取出这个最优划分标签所在的列
featValues = [example[bestFeat] for example in dataSet]
#集合这个列的值
setOfFeat = set(featValues)
for value in setOfFeat:
#为了保证每次引用不改变原始列表的值,用subLabels复制labels
subLabels = labels[:]
#递归获取树的子树
myTree[bestFeatLabel][value] = createTree(splitDataSet\
(dataSet,bestFeat,value),subLabels)
return myTree这个树是由字典键值对组成的,如{A:{B:‘c’,C:{D:‘d’,E:‘e’}}}这样的形式
由此创建树的主要方法也就解读完成,算法主要是
ID3,而目前最流行的算法还是
CART与
C4.5。