目标检测之RCNN
个人成果,禁止以任何形式转载!
1.前言
《Rich feature hierarchies for accurate object detection and semantic segmentation Tech report (v5)》
论文地址:https://arxiv.org/abs/1311.2524.
此文仅对目标检测部分进行介绍,语义分割可查看论文。由于方法比较老了,也仅作概述,理解其思想为主。
过去十年在各种视觉识别任务方面取得的进展在很大程度上是基于使用 SIFT和HOG。但是,如果我们看看视觉识别任务 PASCALVOC 检测的性能,可以认为在 2010-2012 年期间基本停滞,只能靠着模型融合来得到很小的性能提升。2013年,R-CNN可以说是将卷积神经网络用于目标检测的开山之作 ,性能也极大提升,2014年发表于CVPR。R-CNN:Regions with CNN features.
2.R-CNN系统
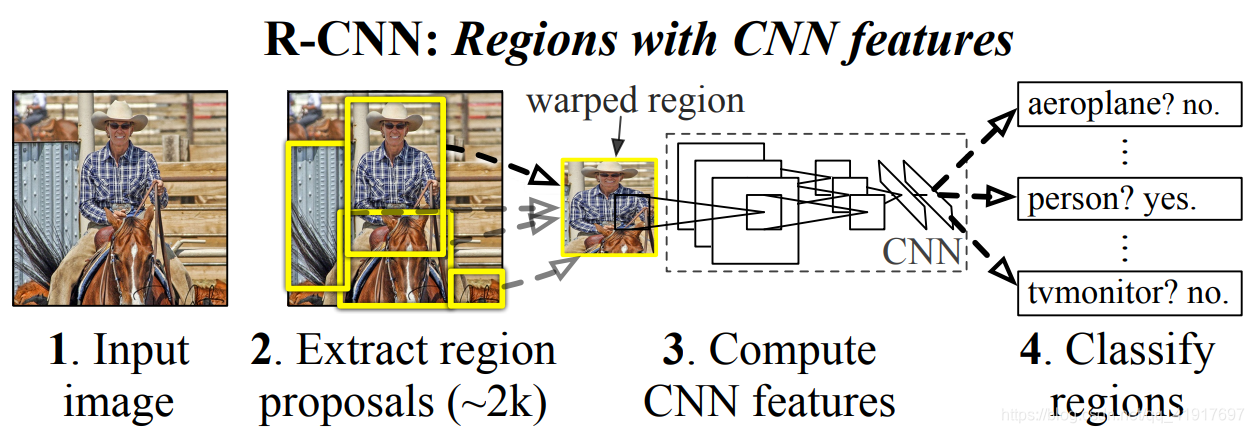 1)获取输入图像。
1)获取输入图像。
2)提取2000左右自下而上的region proposals。使用的是Selective Search。
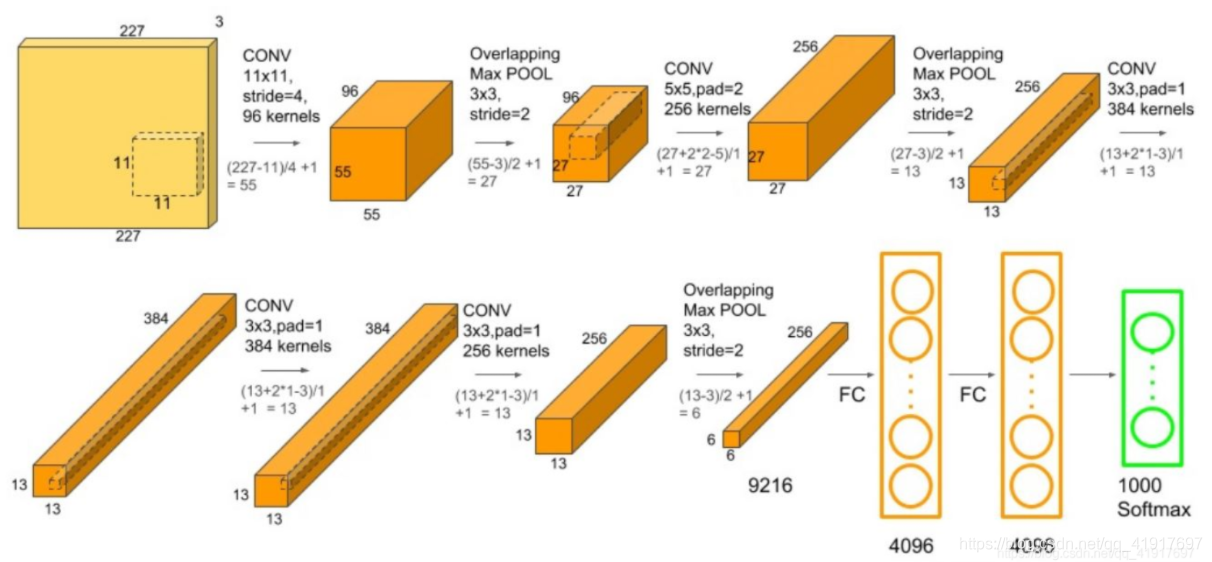
3)利用卷积神经网络提取每个proposal(227x227RGB 图像)的图像特征,每个提取4096维特征向量。特征是通过五个卷积层和两个全连接层来计算的(其实就是AlexNet,可以看这里介绍的)。
因为候选区有大有小,所以需要先处理成227×227大小,处理方法如图所示:

(A )原始候选区
(B )利用周围像素填充成正方形(周围没有图像像素的,就用平均值进行填充)
(C )直接利用平均值进行填充
(D )直接将候选区warp成正方形。无论候选区域的大小或长宽比如何,我们都会将其扭曲到所需的大小。在变换之前,我们先扩张候选区,图像周围的p像素(p = 16)。
最后实验表明使用(D)效果更好。显然,更多的替代方案是可能的,包括使用复制而不是平均填充。作为今后的工作,对这些替代办法、需详尽的对比评估。
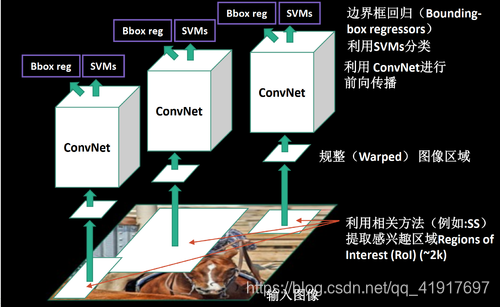
4)利用SVM进行分类。利用前面提取到的候选区域的特征,对每个类别训练一个SVM分类器(背景也算作一类)来判断,候选框里物体的类别,是positive or negative。这里为什么用SVM,不直接softmax得出结果呢?
因为svm适用于少样本训练,但对IoU要求比较严格。CNN需要大量的训练数据,否则容易过拟合。
3.网络的一些细节补充
在目标检测中,需要完成分类和回归两个任务。下面在这两方面对RCNN进行补充。
3.1 classifiers 正负样本
如果仅仅是把有目标的候选区作为正样本,没有目标的候选区作为负样本,那么,候选区只有一小部分的目标该怎么划分呢?作者利用IoU来划分,通过在{0, 0.1, . . . , 0.5} 进行网格搜索,选择了0.3这个阈值。想象一下,每张图都有那么多候选区需要进行训练,对内存和时间消耗特别大。因此,作者采用了standard hard negative mining 的方法,能够快速收敛。
此外,在CNN微调和SVM训练中,正负样本的定义是不同的。SVM训练时,只把ground-truth boxes作为正样本(SVM要求比较严格),小于0.3 IoU的作为负样本,大于0.3的忽略掉。微调时,IoU至少大于0.5的作为正样本,其他作为负样本。这样的设置很重要,因为在微调时跟SVM训练时定义一样的话,正样本会很少很少,造成样本不平衡,选择0.5-1.0作为正样本可以增多30倍的正样本,还能避免overfitting。(CNN需要大量的训练数据,否则容易过拟合。)
3.2 Bounding-box regression
由于selective search提取的区域可能不是很完整,所以需要再次对边框进行回归调整。P代表初步提取的候选框位置,G代表真实的位置,我们用d§来表示P与G的映射函数关系。这里,x,y其实是借助宽高比例直接调整(这里的x,y是框的中点),w,h是先求了exp(w,h必须是正数,且对数空间减少不稳定性)。
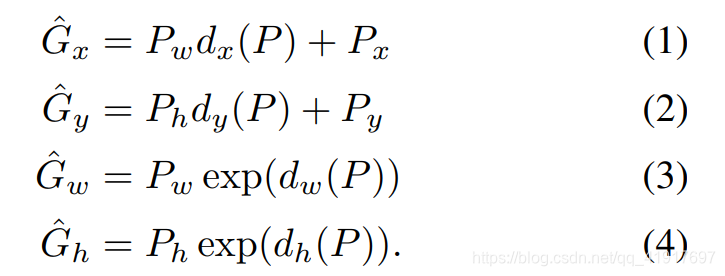
如果利用d()预测出来的G^与真实的G完全一致,那么反解出来d()(用t表示)。
所以我们Bounding-box regression预测出来的t^就应该以刚刚反解出来的t作为目标。
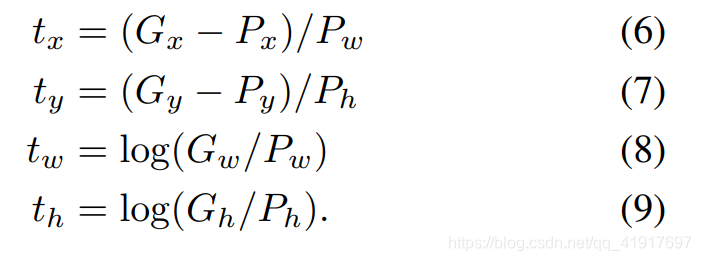
因此,我们需要优化:
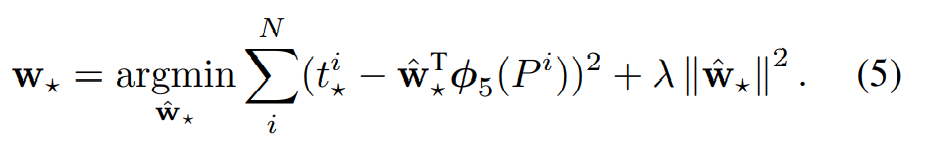
测试时,我们预测每个候选区的分数,并只回归一次边框。原则上,我们可以迭代这个过程(例如,重新为新预测的边框评分,然后从中再预测一个新的边界框,等等)。然而,我们发现迭代并没有改善结果。
4.训练
在训练中,面临一个挑战:缺少足够的标记数据,目前可用的数量不足以训练大型CNN。解决这一问题的传统方法是使用无监督的预训练,然后进行有监督的微调。
第二种是,在大型辅助数据集(ILSVRC)上进行有监督的预训练,然后在小型数据集(PASCAL)上进行特定领域的微调,是在数据稀缺时学习CNN的有效范例。
4.1 Supervised pre-training
在一个大型的辅助数据集(ILSVRC2012 classification)上有区别地预先训练CNN,只使用图像级标注(该数据没有绑定框标签)。
4.2 Domain-specific fine-tuning
为了使CNN 适应新的任务(检测) ,我们只使用warped的候选区继续对CNN参数进行SGD训练。 除了用随机初始化的(N+1)路分类层(其中 N 是对象类的数量,加上背景的1)来替换CNN的分类层外,CNN 的体系结构是不变的。 对于 VOC,N=20,对于ILSVRC2013,N=200。我们将所有>0.5loU为正样本,其余为负样本。 开始 SGD的学习速率为0.001(初始预训练速率的十分之一)。 在每次 SGD迭代中,我们均匀地采样 32 个正样本框(在所有类上)和 96 个负样本背景框,以构造大小为 128 的mini-batch。 我们将抽样偏向于正样本,因为它与背景相比非常罕见。
4.3 总流程*
1)有监督预训练CNN网络(4096->1000),针对目标任务进行微调CNN网络(1000->21)。
2)Selective Search提取候选区,再送入CNN网络得到4096维特征特征保存下来。
注意:这里到底是使用那一层的特征?
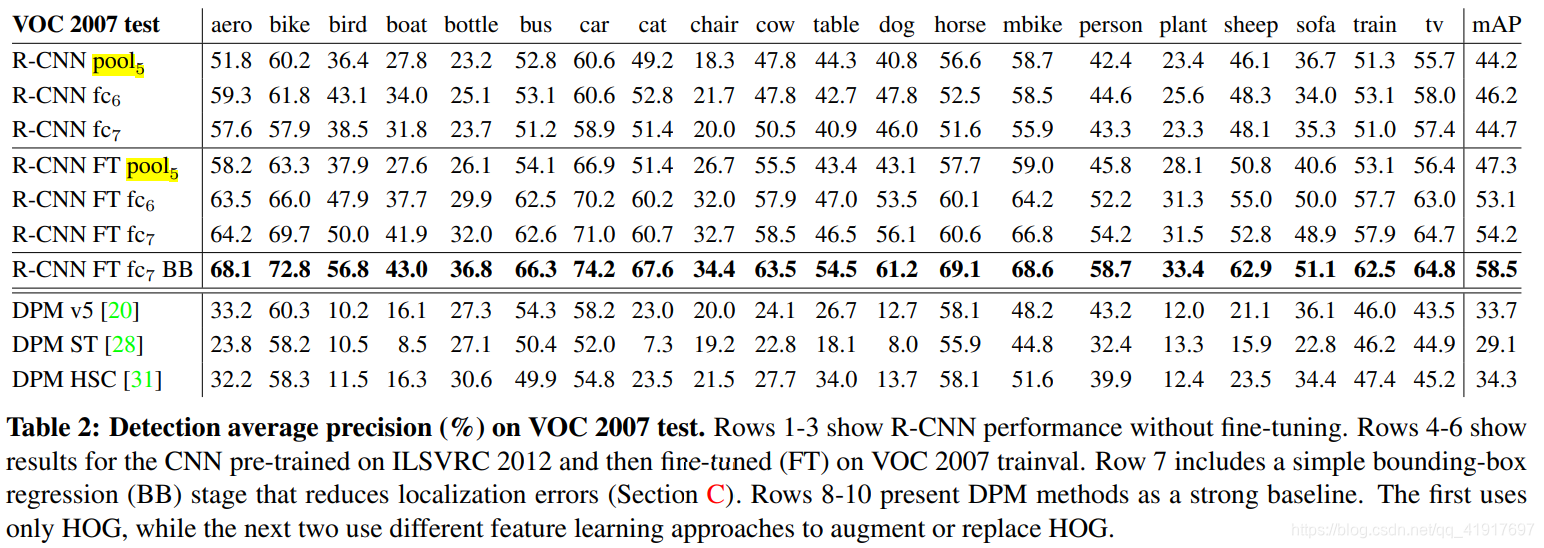
如上图的所示,前三行没有微调时选取AlexNet的pool5,fc6,fc7时的mAP其实差异不大,但fc6和fc7含有的参数量却很大。但是,加上微调后,fc6,fc7性能会更加好!!说明全连接层的存在对于微调来说很重要。fc7+微调+边界框回归性能达到最好。
3)深度网络输出的4096维特征训练N个SVM分类器(二分类),使用hard negative mining方法。
4)深度网络pool5输出的特征图训练线性回归模型去修正边框位置。因为,回归器依赖坐标信息(要输出坐标的修正量),必须取还还有坐标信息的层。
5.缺点
1.使用Selective Search生产候选区时非常耗时。
2.只使用pool5底层的特征,会导致回归边框的准确率不高。
3.一张图像上有2K个候选区,需要使用2K次CNN来提取特征,存在大量的重复计算。
4.特征提取、图像分类、边框回归是三个独立的步骤,要分别训练,测试效率也较低。
个人成果,收藏即可,禁止以任何形式转载!